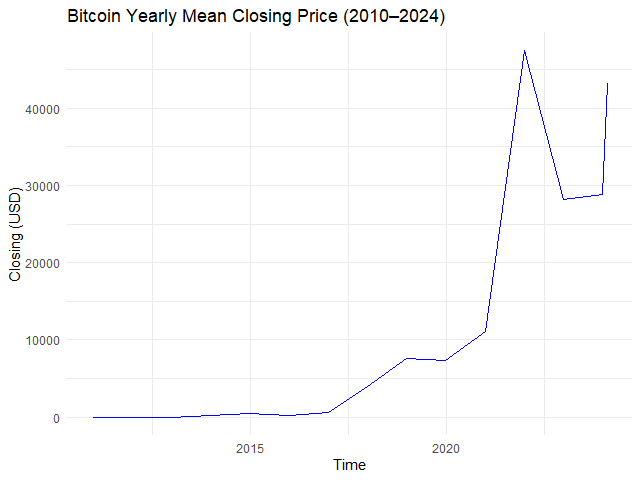# Print when sunny
if weather == "sunny":
print("It's a sunny day. Don't forget your sunscreen!")
# Print when rainy
elif weather == "rainy":
print("It's raining. Remember to bring an umbrella!")
# Print when other conditions
else:
print("Likely chilly. Wear a jacket!")
ผลลัพธ์:
Likely chilly. Wear a jacket!
อธิบาย code:
if block: ประเมินว่า weather เป็น "sunny" ไหม ถ้าใช่ จะ print "It's a sunny day. Don't forget your sunscreen!"
elif block: weather เป็น "rainy" ไหม ถ้าใช่ จะ print "It's raining. Remember to bring an umbrella!"
# A shopping list program
shopping_list = ["milk", "bread", "chips", "apple", "toothpaste", "chocolate"]
# Loop through the list
for item in shopping_list:
# Skip item if chip
if item == "chips":
print("Chips are unhealthy. Skipping ...")
continue
# Stop the loop if toothpaste
if item == "toothpaste":
print("Found toothpaste, done shopping early!")
break
# Do nothing if milk
if item == "milk" or item == "bread":
pass
# Print item
print("Putting", item, "into the cart.")
ผลลัพธ์:
Putting milk into the cart.
Putting bread into the cart.
Chips are unhealthy. Skipping ...
Putting apple into the cart.
Found toothpaste, done shopping early!
ยกตัวอย่าง เรามีไอเดียและโพสต์ไอเดียลง social media เราสามารถเข้าถึงคนที่เราต้องการได้ภายในเวลาอันสั้น และถ้าไอเดียนี้ดี เราก็จะได้ผลตอบรับที่ดีจำนวนมากกลับมา แต่ถ้าเป็นไอเดียไม่เป็นที่ยอมรับของสังคม เราก็จะได้รับแรงต้านมหาศาลเช่นกัน
If you can’t decide, then the answer is no: ถ้าเราตัดสินใจไม่ได้ (เช่น จะไปเรียนต่อไหม) คำตอบคือไม่ เพราะในปัจจุบัน เรามีตัวเลือกมากมาย และเราควร say “yes” ก็ต่อเมื่อเรามั่นใจในตัวเลือกจริง ๆ แล้วเท่านั้น
Classic work: อ่านหนังสือต้นฉบับหรือหนังสือ classic เช่น ถ้าเราต้องการอ่านเกี่ยวกับ evolution เราควรอ่านงานของ Charles Darwin ก่อน แล้วค่อยอ่านหนังสือของคนอื่นที่เขียนต่อยอดจาก Charles Darwin เป็นต้น
No obligation to finish a book: เราอ่านเพื่อทำความเข้าใจไอเดียพื้นฐานของหนังสือ เราไม่จำเป็นต้องอ่านหนังสือให้จบทั้งเล่ม ถ้าเรารู้สึกว่าเข้าใจไอเดียพื้นฐานในหนังสือแล้ว เราสามารถข้ามไปเล่มถัดไปได้ และกลับมาดูหนังสือเล่มเก่าอีกครั้งเมื่อต้องการทบทวนความรู้
You are what you read: เลือกหนังสือที่อ่านให้ดี เพราะหนังสือจะเหมือนเนื้อเพลงที่เล่นวนอยู่ในหัวเรา เราจะกลายเป็นสิ่งที่เราอ่าน
Read to teach: อ่านโดยมีความตั้งใจว่าจะอธิบายให้คนอื่นฟัง การทำเช่นนี้จะทำให้เราเข้าใจสิ่งที่อ่านมากขึ้น
from ใช้กำหนดวันแรกของข้อมูล และ to กำหนดวันสุดท้ายของข้อมูล
ยกตัวอย่างเช่น เราต้องการโหลดข้อมูล Apple ในเดือนพฤษภาคม 2025:
# Load data for May 2025
apple_data_2025_05 = getSymbols("AAPL",
auto.assign = FALSE,
from = "2025-05-01",
to = "2025-05-31")
# Print results
print("First three records:")
head(apple_data_2025_05, n = 3)
print("------------------------------------------------------------------------------")
print("Last three records:")
tail(apple_data_2025_05, n = 3)
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
Specific knowledge เป็นสิ่งที่ทำให้เราแตกต่างจากคนอื่น และทำให้เราสามารถสร้างสิ่งที่สังคมต้องการแต่ยังไม่รู้ว่าจะหามาได้ยังไง เพราะสิ่งนั้นมีแต่เราที่รู้/ทำได้
Specific knowledge เกิดมาจาก 3 ส่วน ได้แก่:
Innate trait: ลักษณะที่ติดตัวเรามาตั้งแต่เกิด
Passion: ความชอบ/ความหลงใหล
Experience: ประสบการณ์ชีวิต
What’s your specific knowledge?
แต่ละคนมี specific knowledge ที่ไม่เหมือนใคร เราสามารถสังเกต specific knowledge ของเราได้โดยมองหาสิ่งที่:
Labour หรือแรงงานเป็น leverage ที่เก่าแก่ที่สุด แต่ใช้งานยาก เพราะเราต้องมี leadership skill ที่ดี
Capital หรือเงินทุน เป็น leverage ที่ scale ได้ดี แต่จัดการได้ยาก แต่ใครที่ทำได้จะได้แต้มต่อจากคนอื่นมาก
Leverage ประเภทสุดท้าย คือ product with no marginal cost of replication
ในขณะที่ labour และ capital เป็น permission-based leverage เพราะเราจะใช้ได้ก็ต่อเมื่อได้รับความยินยอมจากคนอื่น product with no marginal cost of replication เป็น permissionless leverage เพราะเราสามารถใช้ได้โดยไม่ต้องขอความยินยอมจากใคร
Product with no marginal cost of replication คือ สิ่งที่เราสามารถสร้างเพิ่มได้โดยใช้ต้นทุนแทบเป็น 0 เช่น:
หนังสือ
เพลง
โค้ด
YouTube video
ในยุคที่เทคโนโลยีพัฒนาอย่างรวดเร็ว ทุกคนสามารถเข้าถึง product with no marginal cost of replication ทุกคนสามารถสร้าง video และ copy ไปโพสต์ตาม platform ต่าง ๆ โดยไม่เสียค่าใช้จ่ายสักบาท และทำให้ตัวเองให้เป็นที่รู้จักไปทั่วโลกได้ในชั่วข้ามคืนได้
ถ้าอยากจะสร้างความมั่งคั่ง เราควรจะมี leverage ซึ่ง leverage ที่เข้าถึงได้ง่ายที่สุด คือ product with no marginal cost of replication
.
🫡 3.3 Accountability
Clear accountability is important. Without accountability, you don’t have incentives.
ในบทความนี้ เราจะมาสรุปเนื้อหาจาก The Brain Audit ซึ่งเป็น event พิเศษที่พี่ทอย DataRockie จัดขึ้นร่วมกับ Sean D’Souza เจ้าของ one person business “Psychotactics” ซึ่งสอนทักษะทางธุรกิจ เช่น marketing และ copywriting
ก่อนวันงาน The Brain Audit ไม่กี่วัน CK Cheong ซึ่งเป็น CEO ของ Fastwork ออกมาแสดงความเห็นว่า ความต้องการคนที่เป็นเป็ดกำลังลดลง โดยเฉพาะตอนนี้ที่ทุกคนมี AI ซึ่งเป็นเป็ดที่เก่งทุกด้านอยู่ในกระเป๋าอยู่แล้ว
มุมมองของ CK Cheong ต่อการเป็น generalist (source: TNN Tech)
ในมุมนี้ CK Cheong อาจมีส่วนที่สอดคล้องกับความเป็นจริงอยู่บ้าง เพราะถ้าเราดูรายละเอียดประกาศรับสมัครงานต่าง ๆ เราจะเห็นได้ว่า บริษัทต้องการคนที่มีความรู้ความสามารถอยู่ไม่กี่ด้าน
ยกตัวอย่างเช่น ประกาศงานตำแหน่ง Data Analyst ของ AIS ที่ต้องการคนที่ทักษะดังนี้:
ลูกค้าที่สำคัญที่สุด คือ ลูกค้าที่กลับมาซื้อซ้ำ เราจะต้องทำให้ลูกค้ากลับมาซ้ำโดยการให้ result ไม่ใช่ให้ information เพราะในยุคของ AI ลูกค้าสามารถหา information ได้ง่ายมาก แต่น้อยคนที่จะให้ result กับลูกค้าได้
Name Letter Preference Task ที่ให้คนให้คะแนนความชอบต่อตัวอักษรต่าง ๆ ซึ่งสามารถประเมิน self-esteem ได้ (คนส่งนใหญ่จะให้คะแนนตัวอักษรในชื่อตัวเองมากกว่าตัวอักษรอื่น)
แม้ว่า face validity อาจไม่ใช่ตัวบ่งชี้ validity ที่ดี แต่ face validity มีประโยชน์เมื่อเราต้องการสร้างแรงจูงใจให้ผู้ตอบ: เมื่อแบบทดสอบดูเหมือนจะประเมินในสิ่งที่ควรประเมิน (มี face validity) ผู้ตอบจะมีแรงจูงใจที่จะทำแบบทดสอบให้เสร็จ มากกว่าเมื่อแบบทดสอบขาด face validity
.
🧐 Content Validity
เช่นเดียวกับ face validity, content validity เกิดมาจากความคิดเห็น แต่แทนที่จะมาจากคนทั่วไป content validity เป็นความเห็นของผู้เชี่ยวชาญ
Part II และ III ของ Furr และ Bacharach (2014): บทเรียนเชิงทฤษฎีและสถิติของ reliability และ validity
📃 References
Ashton, M. C. (2018). Basic concepts in psychological measurement. In M. C. Ashton (Ed.), Individual differences and personality (3rd ed., pp. 1–28). Academic Press. https://doi.org/10.1016/B978-0-12-809845-5.00001-9
Furr, R. M., & Bacharach, V. R. (2014). Psychometrics: An introduction (2nd ed.). Sage.
Geisinger, K. F. (2013). Reliability. In K. F. Geisinger, B. A. Bracken, J. F. Carlson, J. I. C. Hansen, N. R. Kuncel, S. P. Reise, & M. C. Rodriguez (Eds.), APA handbook of testing and assessment in psychology, Vol. 1. Test theory and testing and assessment in industrial and organizational psychology (pp. 21–42). American Psychological Association. https://doi.org/10.1037/14047-002
Rindskopf, D. (2001). Reliability: Measurement. In N. J. Smelser & P. B. Baltes (Eds.), International encyclopedia of the social & behavioral sciences (pp. 13023–13028). Pergamon. https://doi.org/10.1016/B0-08-043076-7/00722-1
Sireci, S. G., & Sukin, T. (2013). Test validity. In K. F. Geisinger, B. A. Bracken, J. F. Carlson, J. I. C. Hansen, N. R. Kuncel, S. P. Reise, & M. C. Rodriguez (Eds.), APA handbook of testing and assessment in psychology, Vol. 1. Test theory and testing and assessment in industrial and organizational psychology (pp. 61–84). American Psychological Association. https://doi.org/10.1037/14047-004
✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
Writing Is Not Magic, It’s Design เป็นหนังสือของ João Batalheiro Ferreira ที่แนะนำแนวคิดในการเขียนสำหรับนักออกแบบ (designer) ซึ่งมัก “คิดเป็นภาพ” ได้ดีกว่า “คิดเป็นตัวหนังสือ”
แม้ว่า Writing Is Not Magic, It’s Design จะถูกเขียนมาให้นักออกแบบ แต่แนวคิดในหนังสือสามารถปรับใช้ได้กับทุกคนที่ต้องการพัฒนาทักษะการเขียนของตัวเอง โดยเฉพาะการเขียน non-fiction อย่างเขียน blog และบทความ
ในบทความนี้ เราจะมาสรุปเนื้อหาของ Writing Is Not Magic, It’s Design ใน 5 ส่วนกัน:
What writing is: การเขียนคืออะไร
Writing method: วิธีเขียนจาก 0 ถึง 100
Modular writing: การจัดการโครงสร้างงานเขียน
Writing stages: วิธีแปลงไอเดียให้เป็นงานเขียน
Writing method combined: วิธีเขียนอย่างเป็นระบบ
ถ้าพร้อมแล้ว ไปเริ่มกันเลย
หนังสือ Writing Is Not Magic, It’s Design จาก Amazon
ในบทความนี้ เราจะมาเรียนรู้ 7 วิธีการทำงานกับ time series data หรือข้อมูลที่จัดเรียงด้วยเวลา ในภาษา R ผ่านการทำงานกับ Bitcoin Historical Data ซึ่งมีข้อมูล Bitcoin ในช่วงปี ค.ศ. 2010–2024 กัน:
Converting: การแปลงข้อมูลเป็น datetime และ time series
Missing values: การจัดการ missing values ใน time series data
Plotting: การสร้างกราฟ time series data
Subsetting: การเลือกข้อมูลจาก time series data
Aggregating: การสรุป time series data
Rolling window: การทำ rolling window
Expanding window: การทำ expanding window
ถ้าพร้อมแล้วไปเริ่มกันเลย
🏁 Getting Started
ในการเริ่มทำงานกับ time series ในภาษา R เราจะเริ่มต้นจาก 2 อย่าง ได้แก่:
Install and load packages
Load dataset
.
1️⃣ Install & Load Packages
ในภาษา R เรามี 3 packages ที่ใช้ทำงานกับ time series data บ่อย ๆ ได้แก่:
Base R packages ที่มาพร้อมกับภาษา R
lubridate: ใช้แปลงข้อมูลและจัด format ของ date-time data
เรามาดูวิธีแรกในการทำงานกับ time series data กัน นั่นคือ:
การแปลงข้อมูลให้เป็น datetime
การแปลงข้อมูลให้เป็น time series
.
1️⃣ การแปลงข้อมูลให้เป็น Datetime
ในการทำงานกับ time series data เราจะต้องแปลงข้อมูลประเภทอื่น ๆ เช่น character และ numeric ให้เป็น datetime ก่อน เช่น date (เช่น “Feb 09, 2024”) ใน Bitcoin dataset
เราสามารถแปลงข้อมูลจาก character เป็น Date ได้ 2 วิธี ดังนี้:
.
วิธีที่ 1. ใช้ as.Date() ซึ่งเป็น base R function และต้องการ input 2 อย่าง ได้แก่:
x: ข้อมูลที่ต้องการแปลงเป็น Date
format: format ของวันเวลาของข้อมูลต้นทาง (เช่น วัน-เดือน-ปี, ปี-เดือน-วัน, เดือน-วัน-ปี)
# Convert `date` to Date
btc_cleaned$date <- as.Date(btc_cleaned$date,
format = "%b %d, %Y")
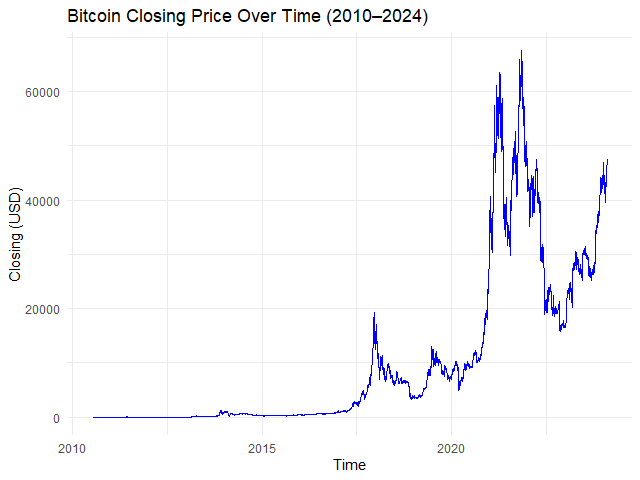
# Plot the time series
autoplot.zoo(btc_zoo[, "close"]) +
## Adjust line colour
geom_line(color = "blue") +
## Add title and labels
labs(title = "Bitcoin Closing Price Over Time (2010–2024)",
x = "Time",
y = "Closing Price (USD)") +
## Use minimal theme
theme_minimal()
# Example 1. View yearly mean closing price
btc_yr_mean <- apply.yearly(btc_zoo[, "close"],
FUN = mean)
# Plot the results
autoplot.zoo(btc_yr_mean) +
## Adjust line colour
geom_line(color = "blue") +
## Add title and labels
labs(title = "Bitcoin Yearly Mean Closing Price (2010–2024)",
x = "Time",
y = "Closing (USD)") +
## Use minimal theme
theme_minimal()
ผลลัพธ์:
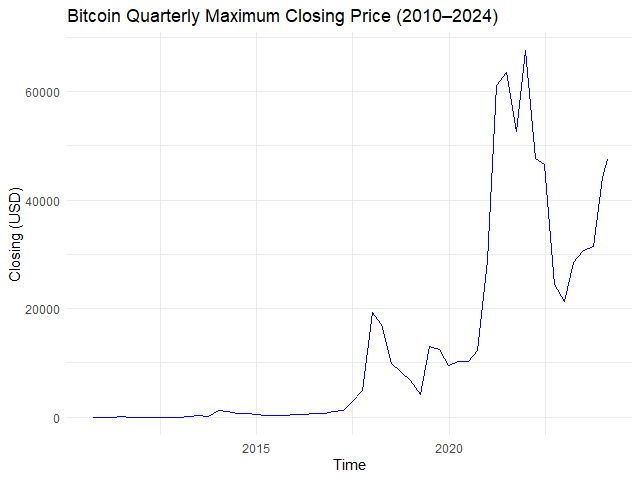
หรือหาราคาปิดสูงสุดในแต่ละไตรมาส:
# Example 2. View quarterly max closing price
btc_qtr_max <- apply.quarterly(btc_zoo[, "close"],
FUN = max)
# Plot the results
autoplot.zoo(btc_qtr_max) +
## Adjust line colour
geom_line(color = "blue") +
## Add title and labels
labs(title = "Bitcoin Quarterly Maximum Closing Price (2010–2024)",
x = "Time",
y = "Closing (USD)") +
## Use minimal theme
theme_minimal()
# Create the window for mean price
btc_30_days_roll_mean <- rollmean(x = btc_zoo,
k = 30,
align = "right",
fill = NA)
# Plot the results
autoplot.zoo(btc_30_days_roll_mean[, "close"]) +
## Adjust line colour
geom_line(color = "blue") +
## Add title and labels
labs(title = "Bitcoin 30-Day Rolling Mean Price (2010–2024)",
x = "Time",
y = "Closing (USD)") +
## Use minimal theme
theme_minimal()
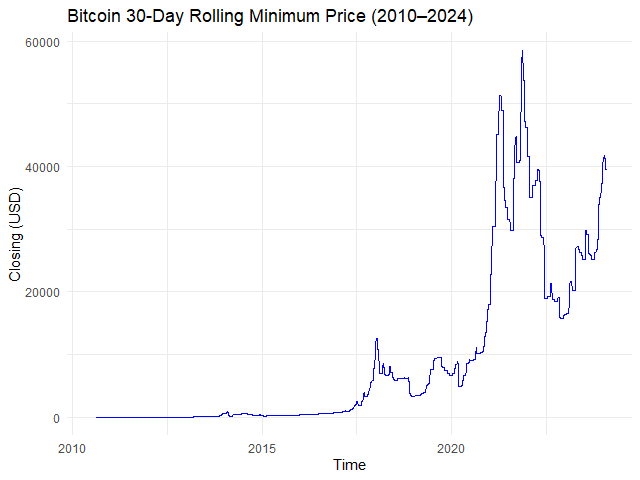
# Creating a rolling window with min() function
btc_30_days_roll_min <- rollapply(data = btc_zoo,
width = 30,
FUN = min,
align = "right",
fill = NA)
# Plot the results
autoplot.zoo(btc_30_days_roll_min[, "close"]) +
## Adjust line colour
geom_line(color = "blue") +
## Add title and labels
labs(title = "Bitcoin 30-Day Rolling Minimum Price (2010–2024)",
x = "Time",
y = "Closing (USD)") +
## Use minimal theme
theme_minimal()
ผลลัพธ์:
➡️ Expanding Window
Expanding window เป็นการสรุปข้อมูลแบบสะสม เช่น:
Date
Average
2024-01-01
หาค่าเฉลี่ยของวันที่ 1
2024-01-02
หาค่าเฉลี่ยของวันที่ 1 + 2
2024-01-03
หาค่าเฉลี่ยของวันที่ 1 + 2 + 3
2024-01-04
หาค่าเฉลี่ยของวันที่ 1 + 2 + 3 + 4
2024-01-05
หาค่าเฉลี่ยของวันที่ 1 + 2 + 3 + 4 + 5
ในภาษา R เราสามารถสร้าง expanding window ได้ด้วย rollapply() โดยเราต้องกำหนดให้:
# Subset for Jan 2024 data
btc_jan_2024 <- window(x = btc_zoo,
start = as.Date("2024-01-01"),
end = as.Date("2024-01-31"))
# Create a sequence of widths
btc_jan_2024_width <- seq_along(btc_jan_2024)
# Create an expanding window for mean price
btc_exp_mean <- rollapply(data = btc_2024,
width = btc_jan_2024_width,
FUN = mean,
align = "right",
fill = NA)
# Plot the results
autoplot.zoo(btc_exp_mean[, "close"]) +
## Adjust line colour
geom_line(color = "blue") +
## Add title and labels
labs(title = "Bitcoin Expanding Mean Price (Jan 2024)",
x = "Time",
y = "Closing (USD)") +
## Use minimal theme
theme_minimal()
ผลลัพธ์:
😎 Summary
ในบทความนี้ เราได้ทำความรู้จักกับ 7 วิธีการทำงานกับ time series ในภาษา R โดยใช้ base R, lubridate, และ zoo package กัน:
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
Donald Miller เขียนหนังสือ How to Grow Your Small Business เพื่อถ่ายทอดแนวทางในการทำงานที่ช่วย “professionalise” (ทำให้เป็นมืออาชีพ) ธุรกิจของเรามากขึ้น
หลายปีก่อน แม้ว่าธุรกิจจะเป็นไปได้ดี แต่ Miller ก็รู้สึกว่า ยังมีอะไรบางอย่างขาดหายไป และสิ่งนั้นทำให้ Miller รู้สึกติดกับอยู่ในธุรกิจของตัวเอง เพราะแทนที่ธุรกิจจะเติบโตได้ด้วยตัวเอง Miller ต้องคอยกำกับปฏิบัติการธุรกิจไม่ให้ “ลุกเป็นไฟ” ตลอดเวลา
จากการลองผิดลองถูก Miller ค้นพบแนวทางการทำงานที่เหมาะสมและช่วยให้ธุรกิจเดินไปข้างหน้าได้โดยไม่ต้องคอยกำกับทุกย่างก้าว
ในบทความนี้ เราจะมาสรุป Small Business Flight Plan หรือ 6 แนวทางการดำเนินธุรกิจจาก How to Grow Your Small Business กัน
ส่วนสุดท้ายของ Business on a Mission Guiding Principles คือ Critical Actions ซี่งหมายถึง action ที่ทีมงานแต่ละคนสามารถทำได้ทุกวัน ซึ่งจะช่วยขับเคลื่อนธุรกิจไปข้างหน้า พร้อมกับสร้างวัฒนธรรมองค์กรและภายลักษณ์ของธุรกิจให้คนภายนอก
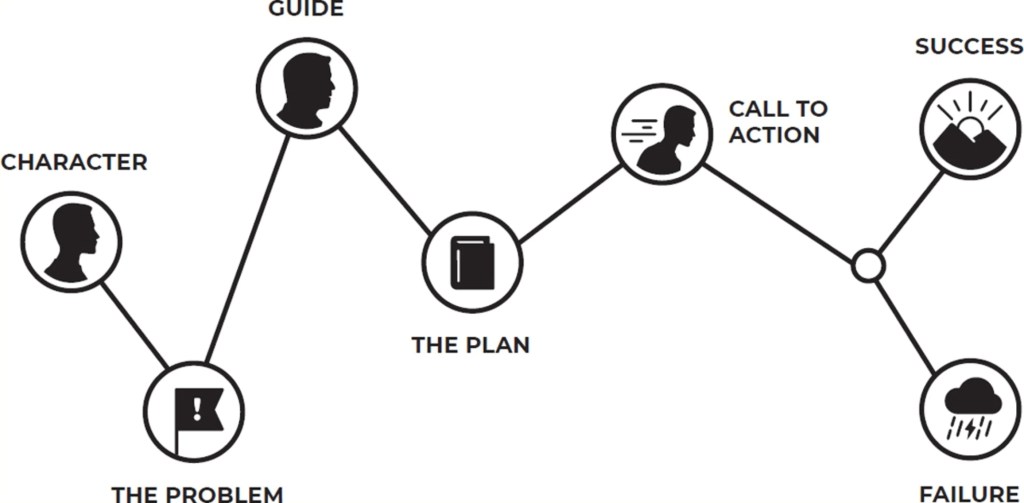
Character เป็นองค์ประกอบแรกสุดในของทุกเรื่องราว หนังที่เราดูหรือนิยายที่เราอ่านเปิดเรื่องมาด้วยตัวละครเอกที่มีความต้องการอะไรบางอย่าง (เช่น ต้องการเป็นราชาโจรสลัด)
กรนำเสนอตัวเอกเป็นการเปิด story loop ในใจของผู้รับสาร และชวนให้อยากติดตามสารของเรา
การบริหารการเงินอาจไม่ใช่เรื่องที่สนุกที่สุดของการดำเนินธุรกิจ แต่ก็เป็นสิ่งที่จำเป็น Miller เองดูเหมือนนักธุรกิจหลาย ๆ คนที่ชอบการหาเงินมากกว่าจัดการเงิน ดังนั้น แนวทางในการบริหารเงินของ Miller จึงเน้นความเข้าในง่ายและตอบโจทย์ได้จริง
💸 Cash Flow Made Simple
แนวคิด Cash Flow Made Simple เสนอให้เราแบ่งบัญชีออกป็น 5 บัญชี ได้แก่:
Miller เปรียบเทียบการมีเงิน ใน Business Profit Account เหมือนกับเครื่องบินที่มีน้ำมันสำรอง ยิ่งมีเยอะก็ยิ่งทำให้บินรอบสนามได้นานได้จนกว่าสถานการณ์จะดีขึ้นและเครื่องบินสามารถลงจอดได้
จ้าง certified coach ของ Business Made Simple (HireACoach.com)
ไม่ว่าจะใช้วิธีไหน เราสามารถปรับใช้ Small Business Flight Plan ได้ตามความเหมาะสมของธุรกิจเรา เพราะแต่ละธุรกิจมีลักษณะที่ไม่เหมือนกัน และคนที่รู้จักธุรกิจเราดีที่สุด คือ ตัวเราเอง
XGBoost เป็น machine learning model ที่จัดอยู่ในกลุ่ม tree-based models หรือ models ที่ทำนายข้อมูลด้วย decision tree อย่าง single decision tree และ random forest
ใน XGBoost, decision trees จะถูกสร้างขึ้นมาเป็นรอบ ๆ โดยในแต่ละรอบ decision trees ใหม่จะเรียนรู้จากความผิดพลาดของรอบก่อน ซึ่งจะทำให้ decision trees ใหม่มีความสามารถที่ดีขึ้นเรื่อย ๆ
เมื่อสิ้นสุดการสร้าง XGBoost ใช้ผลรวมของ decision trees ทุกต้นในการทำนายข้อมูล ดังนี้:
# A tibble: 6 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compact
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compact
3 audi a4 2 2008 4 manual(m6) f 20 31 p compact
4 audi a4 2 2008 4 auto(av) f 21 30 p compact
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compact
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compact
จากผลลัพธ์ เราจะเห็นได้ว่า mpg มี columns ที่เราต้องปรับจาก character เป็น factor อยู่ เช่น manufacturer, model ซึ่งเราสามารถปรับได้ดังนี้:
# Convert character columns to factor
## Get character columns
chr_cols <- c("manufacturer",
"model",
"trans",
"drv",
"fl",
"class")
## For-loop through the character columns
for (col in chr_cols) {
mpg[[col]] <- as.factor(mpg[[col]])
}
## Check the results
str(mpg)
# Separate the features from the outcome
## Get the features
x <- mpg[, !names(mpg) %in% "hwy"]
## One-hot encode the features
x <- model.matrix(~ . - 1,
data = x)
## Get the outcome
y <- mpg$hwy
ข้อที่ 2. จากนั้น เราจะแบ่ง dataset เป็น training (80%) และ test sets (20%) ดังนี้:
# Split the data
## Set seed for reproducibility
set.seed(360)
## Get training index
train_index <- sample(1:nrow(x),
nrow(x) * 0.8)
## Create x, y train
x_train <- x[train_index, ]
y_train <- y[train_index]
## Create x, y test
x_test <- x[-train_index, ]
y_test <- y[-train_index]
## Check the results
cat("TRAIN SET", "\\n")
cat("1. Data in x_train:", nrow(x_train), "\\n")
cat("2. Data in y_train:", length(y_train), "\\n")
cat("---", "\\n", "TEST SET", "\\n")
cat("1. Data in x_test:", nrow(x_test), "\\n")
cat("2. Data in y_test:", length(y_test), "\\n")
ผลลัพธ์:
TRAIN SET
1. Data in x_train: 187
2. Data in y_train: 187
---
TEST SET
1. Data in x_test: 47
2. Data in y_test: 47
.
ข้อที่ 3. สุดท้าย เราจะแปลง x, y เป็น DMatrix ซึ่งเป็น object ที่ xgboost ใช้ในการสร้าง XGboost model ดังนี้:
# Convert to DMatrix
## Training set
train_set <- xgb.DMatrix(data = x_train,
label = y_train)
## Test set
test_set <- xgb.DMatrix(data = x_test,
label = y_test)
## Check the results
train_set
test_set
ผลลัพธ์:
TRAIN SET
xgb.DMatrix dim: 187 x 77 info: label colnames: yes
---
TEST SET
xgb.DMatrix dim: 47 x 77 info: label colnames: yes
4️⃣ Train the Model
ในขั้นที่สี่ เราจะสร้าง XGBoost model ด้วย xgb.train() ซึ่งต้องการ 5 arguments ดังนี้:
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ