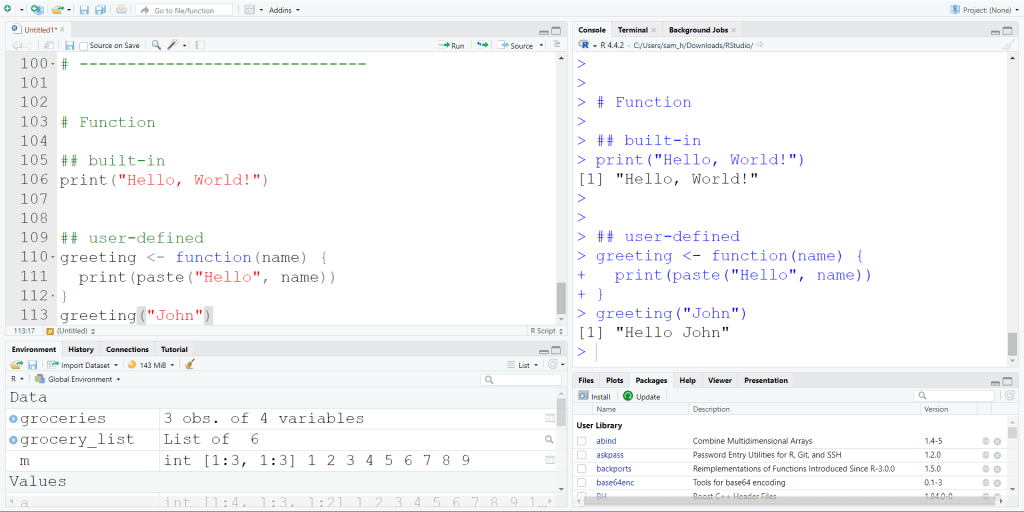
ในบทความนี้ เราจะมาทำความรู้กันกับ KNN model และวิธีสร้าง KNN model ด้วย class package ในภาษา R กัน
- 💻 KNN in R With class Package
- 1️⃣ Step 1. Get class Package
- 2️⃣ Step 2. Get the Dataset
- 3️⃣ Step 3. Prepare Data
- 4️⃣ Step 4. Train a KNN Model
- 5️⃣ Step 5. Evaluate the Model
- 🍩 Bonus: Fine-Tuning
- 😺 GitHub
- 📃 References
- ✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
KNN หรือ K-Nearest Neighbors เป็น machine learning algorithm ประเภท supervised learning ซึ่งใช้ได้กับงานประเภท classification (จัดกลุ่ม) และ regression (ทำนายแนวโน้ม)
การทำงานของ KNN ตรงไปตรงมา คือ ทำนายข้อมูลโดยการดูจากข้อมูลใกล้เคียง จำนวน k ข้อมูล (เราสามารถกำหนดค่า k เองได้)
ยกตัวอย่างเช่น เราต้องการใช้ KNN ทำนายราคาหุ้น KNN จะดูราคาหุ้นที่อยู่ใกล้เคียงกับหุ้นที่เราต้องการทำนายราคา เช่น 5 หุ้นใกล้เคียง โดย:
- 2/5 หุ้น = ราคาลง
- 3/5 หุ้น = ราคาขึ้น
KNN จะทำนายว่า หุ้นในใจของเรา จะราคาขึ้น เพราะหุ้นใกล้เคียงส่วนใหญ่ปรับราคาขึ้น เป็นต้น
💻 KNN in R With class Package
เราสามารถสร้าง KNN model ในภาษา R ด้วย class package โดยมี 5 ขั้นตอนดังนี้:
- Get
classpackage - Load the dataset
- Prepare the data
- Train a KNN model
- Evaluate the model
เราไปดูตัวอย่างการสร้าง KNN model เพื่อทำนายประเภทดอกไม้ ด้วย iris dataset กัน
1️⃣ Step 1. Get class Package
ในขั้นแรก ให้เราติดตั้งและเรียกใช้งาน class package
ติดตั้ง (ทำครั้งเดียว):
# Install
install.packages("class")
เรียกใช้งาน (ทำทุกครั้งที่เริ่ม session ใหม่):
# Load
library(class)
2️⃣ Step 2. Get the Dataset
ในขั้นที่สอง ให้เราโหลด dataset ที่จะใช้งาน
โดยในบทความนี้ เราจะใช้ iris ที่มีข้อมูลดอกไม้ 3 ชนิด ได้แก่:
- Iris setosa
- Iris virginica
- Iris versicolor
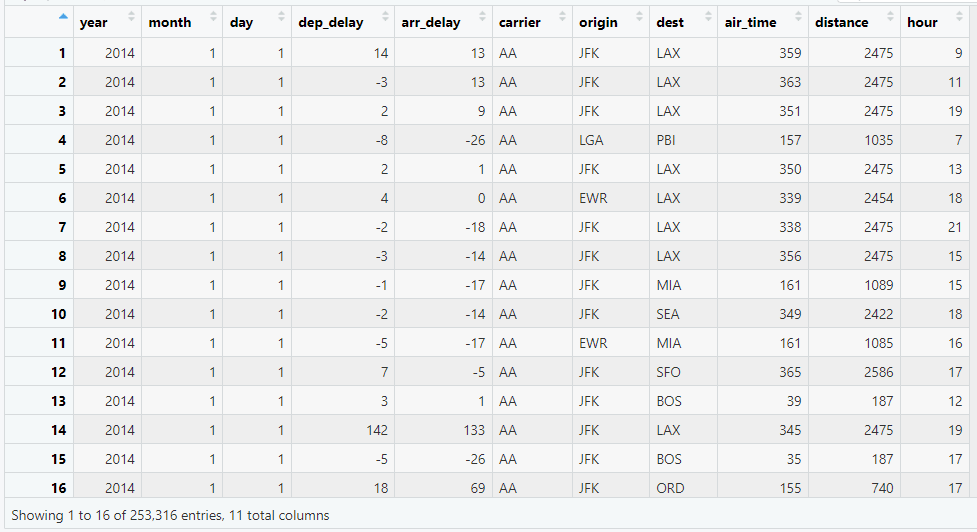
นอกจากประเภทดอกไม้ (species) iris dataset ยังประกอบด้วยความกว้าง (width) และความยาว (length) ของกลีบดอกชั้นนอก (sepal) และชั้นใน (petal)
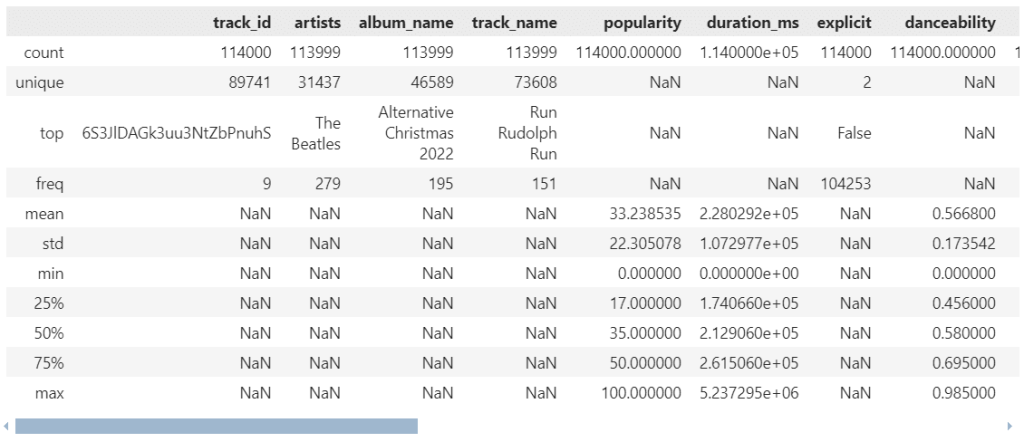
เนื่องจาก iris เป็น built-in dataset ใน ภาษา R เราสามารถโหลดข้อมูลด้วยคำสั่ง data() ได้:
# Load
data(iris)
เมื่อโหลดแล้ว เราสามารถดูตัวอย่าง dataset ได้ด้วย head():
# Preview
head(iris)
ผลลัพธ์:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
3️⃣ Step 3. Prepare Data
ในขั้นที่สาม เราจะเตรียมข้อมูล เพื่อใช้สร้าง KNN model
โดยสำหรับ iris dataset เราจะทำ 3 อย่าง คือ:
- Normalise data
- Split data
- Separate features from the label
.
📉 Normalise Data
เนื่องจาก KNN model อ้างอิงระยะห่างระหว่างข้อมูลในการทำนายผลลัพธ์ ข้อมูลที่มีช่วงกว้าง (เช่น 0-100) จะมีน้ำหนักกว่าข้อมูลที่มีช่วงแคบ (เช่น 0-10) และทำให้ model ของเรา bias ได้
เพื่อป้องกันความเสี่ยงนี้ เราต้อง normalise ข้อมูล หรือการทำให้ข้อมูลมีช่วงมีช่วงข้อมูลเดียวกัน
การทำ normalisation มีหลายวิธี แต่วิธีที่นิยมใช้กับ KNN คือ min-max normalisation ซึ่งเปลี่ยนช่วงข้อมูลให้อยู่ในช่วง 0-1 ผ่านสูตร:
(X - Min) / (Max - Min)
- X คือ ข้อมูล
- Min คือ ค่าที่น้อยที่สุด
- Max คือ ค่าที่มากที่สุด
ในภาษา R เราไม่มี function ที่ใช้ทำ min-max normalisation ได้โดยตรง เราเลยต้องเขียน function ขึ้นมาใช้เอง:
# Define a function for normalisation
normalise <- function(x) {
return((x - min(x)) / (max(x) - min(x)))
}
จากนั้น ให้เราใช้ function นี้กับ columns ที่เป็นตัวเลข (numeric) เช่น Sepal.Length แล้วเก็บผลลัพธ์ไว้ใน data frame ใหม่ ชื่อ iris_normalises:
# Apply the function to the dataset
iris_normalised <- as.data.frame(lapply(iris[, 1:4],
normalise))
เนื่องจากตอนที่เราใช้ function เราตัด column ที่ไม่ใช่ตัวเลขออก ทำให้ iris_normalised ไม่มี column Species
เราสามารถใส่ Species กลับเข้าไป เพื่อใช้ในขั้นตอนถัดไป แบบนี้:
# Add species column back into the data frame
iris_normalised$Species <- iris$Species
สุดท้าย เราเช็กผลลัพธ์ด้วยการเรียกดูสถิติของ iris_normalised:
# Check the results
summary(iris_normalised)
ผลลัพธ์:
Sepal.Length Sepal.Width
Min. :0.0000 Min. :0.0000
1st Qu.:0.2222 1st Qu.:0.3333
Median :0.4167 Median :0.4167
Mean :0.4287 Mean :0.4406
3rd Qu.:0.5833 3rd Qu.:0.5417
Max. :1.0000 Max. :1.0000
Petal.Length Petal.Width
Min. :0.0000 Min. :0.00000
1st Qu.:0.1017 1st Qu.:0.08333
Median :0.5678 Median :0.50000
Mean :0.4675 Mean :0.45806
3rd Qu.:0.6949 3rd Qu.:0.70833
Max. :1.0000 Max. :1.00000
Species
setosa :50
versicolor:50
virginica :50
จะเห็นว่า:
- Columns ที่เป็นตัวเลข มีช่วงอยู่ระหว่าง 0 และ 1
- เรายังมี column
Speciesอยู่
.
🪓 Split Data
ในการสร้าง KNN model เราควรแบ่ง dataset ที่มีเป็น 2 ส่วน คือ:
- Training set: ใช้สำหรับสร้าง model
- Test set: ใช้สำหรับประเมิน model
เราเริ่มแบ่งข้อมูลด้วยการสุ่ม row index ที่จะอยู่ใน training set:
# Set seed for reproducibility
set.seed(2025)
# Create a training index
train_index <- sample(1:nrow(iris_normalised),
0.7 * nrow(iris_normalised))
จากนั้น subset ข้อมูลด้วย row index ที่สุ่มไว้:
# Split the data
train_set <- iris_normalised[train_index, ]
test_set <- iris_normalised[-train_index, ]
.
🏷️ Separate Features From Label
ขั้นตอนสุดท้ายในการเตรียมข้อมูล คือ แยก features หรือ X (columns ที่จะใช้ทำนาย) ออกจาก label หรือ Y (สิ่งที่ต้องการทำนาย):
# Separate features from label
## Training set
train_X <- train_set[, 1:4]
train_Y <- train_set$Species
## Test set
test_X <- test_set[, 1:4]
test_Y <- test_set$Species
4️⃣ Step 4. Train a KNN Model
ขั้นที่สี่เป็นขั้นที่เราสร้าง KNN model ขึ้นมา โดยเรียกใช้ knn() จาก class package
ทั้งนี้ knn() ต้องการ input 3 อย่าง:
train: fatures จาก training settest: feature จาก test setcl: label จาก training setk: จำนวนข้อมูลใกล้เคียงที่จะใช้ทำนายผลลัพธ์
# Train a KNN model
pred <- knn(train = train_X,
test = test_X,
cl = train_Y,
k = 5)
ในตัวอย่าง เรากำหนด k = 5 เพื่อทำนายผลลัพธ์โดยดูจากข้อมูลที่ใกล้เคียง 5 อันดับแรก
5️⃣ Step 5. Evaluate the Model
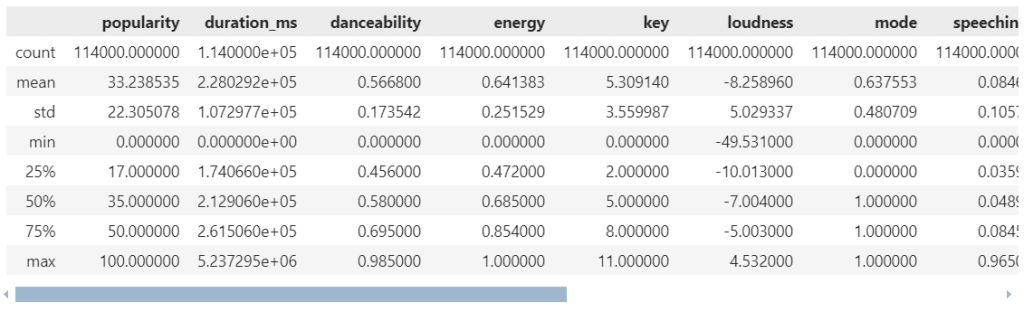
หลังจากได้ model แล้ว เราประเมินประสิทธิภาพของ model ในการทำนายผลลัพธ์ ซึ่งเราทำได้ง่าย ๆ โดยคำนวณ accuracy หรือสัดส่วนของข้อมูลที่ model ตอบถูกต่อจำนวนข้อมูลทั้งหมด:
Accuracy = Correct predictions / Total predictions
ในภาษา R ให้เราสร้าง confusion matrix หรือ matrix แสดงจำนวนคำตอบที่ถูกและผิด ด้วย table() function:
# Create a confusion matrix
cm <- table(Predicted = predictions,
Actual = test_Y)
# Print the matrix
print(cm)
ผลลัพธ์:
Actual
Predicted setosa versicolor virginica
setosa 15 0 0
versicolor 0 17 0
virginica 0 2 11
Note: จะเห็นได้ว่า model เราตอบถูกเป็นส่วนใหญ่ (ราว 90%)
จากนั้น คำนวณ accuracy ด้วย sum() และ diag():
# Calculate accuracy
acc <- sum(diag(cm)) / sum(cm)
# Print accuracy
cat("Accuracy:", round(acc, 2))
ผลลัพธ์:
Accuracy: 0.96
จากผลลัพธ์ เราจะเห็นว่า model มีความแม่นยำสูงถึง 96%
🍩 Bonus: Fine-Tuning
ในบางครั้ง ค่า k ที่เราตั้งไว้ อาจไม่ได้ทำให้เราได้ KNN model ที่ดีที่สุด
แทนที่เราจะแทนค่า k ใหม่ไปเรื่อย ๆ เราสามารถใช้ for loop เพื่อหาค่า k ที่ทำให้เราได้ model ที่ดีที่สุดได้
ให้เราเริ่มจากสร้าง vector ที่มีค่า k ที่ต้องการ:
# Create a set of k values
k_values <- 1:20
และ vector สำหรับเก็บค่า accuracy ของค่า k แต่ละตัว:
# Createa a vector for accuracy results
accuracy_results <- numeric(length(k_values))
แล้วใช้ for loop เพื่อหาค่า accuracy ของค่า k:
# For-loop through the k values
for (i in seq_along(k_values)) {
## Set the k value
k <- k_values[i]
## Create a KNN model
predictions <- knn(train = train_X,
test = test_X,
cl = train_Y,
k = k)
## Create a confusion matrix
cm <- table(Predicted = predictions,
Actual = test_Y)
## Calculate accuracy
accuracy_results[i] <- sum(diag(cm)) / sum(cm)
}
# Find the best k and the corresponding accuracy
best_k <- k_values[which.max(accuracy_results)]
best_accuracy <- max(accuracy_results)
# Print best k and accuracy
cat(paste("Best k:", best_k),
paste("Accuracy:", round(best_accuracy, 2)),
sep = "\n")
ผลลัพธ์:
Best k: 12
Accuracy: 0.98
แสดงว่า ค่า k ที่ดีที่สุด คือ 12 โดยมี accuracy เท่ากับ 98%
นอกจากนี้ เรายังสามารถสร้างกราฟ เพื่อช่วยทำความเข้าใจผลของค่า k ต่อ accuracy:
# Plot the results
plot(k_values,
accuracy_results,
type = "b",
pch = 19,
col = "blue",
xlab = "Number of Neighbors (k)",
ylab = "Accuracy",
main = "KNN Model Accuracy for Different k Values")
grid()
ผลลัพธ์:

จะเห็นได้ว่า k = 12 ให้ accuracy ที่ดีที่สุด และ k = 20 ให้ accuracy ต่ำที่สุด ส่วนค่า k อื่น ๆ ให้ accuracy ในช่วง 93 ถึง 96%
😺 GitHub
ดู code ทั้งหมดในบทความนี้ได้ที่ GitHub
📃 References
- Supervised Learning in R: Classification
- K-Nearest Neighbors (KNN) Classification with R Tutorial
- knn: k-Nearest Neighbour Classification
- K-Nearest Neighbors (KNN) – Using R
- KNN Classifier in R Programming
✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
📕 ขอฝากหนังสือเล่มแรกในชีวิตด้วยนะครับ 😆
🙋 ใครที่กำลังเรียนจิตวิทยาหรือทำงานสายจิตวิทยา และเบื่อที่ต้องใช้ software ราคาแพงอย่าง SPSS และ Excel เพื่อทำข้อมูล
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
- Correlation
- t-tests
- ANOVA
- Reliability
- Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
แล้วทุกคนจะแปลกใจว่า ทำไมภาษา R ง่ายขนาดนี้ 🙂↕️
👉 สนใจดูรายละเอียดหนังสือได้ที่ meb: