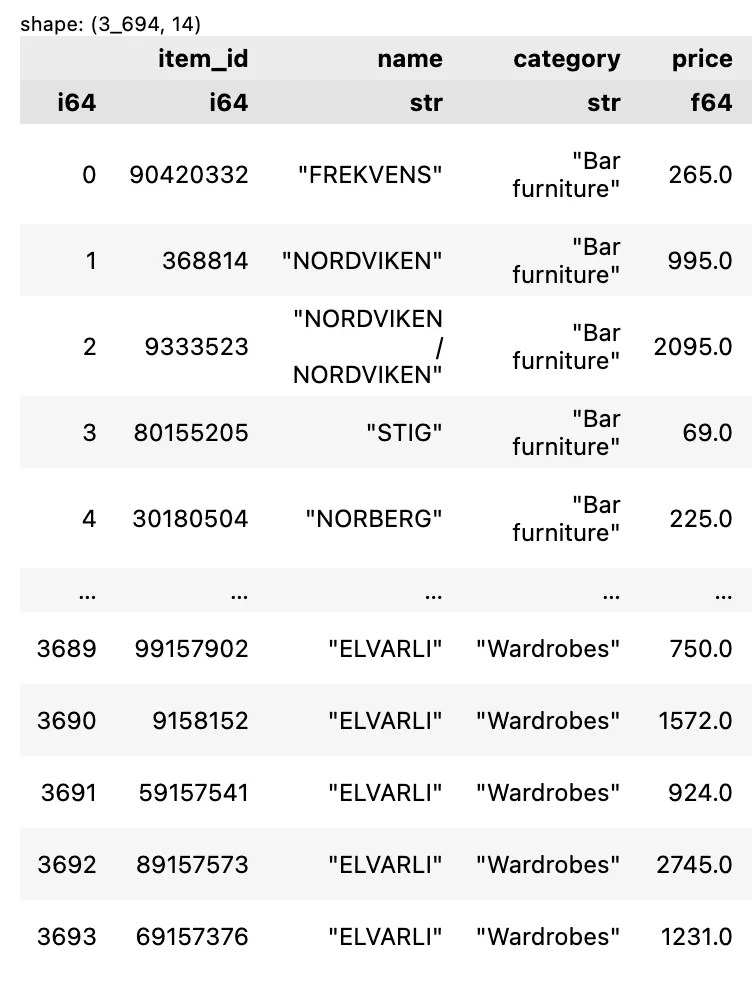
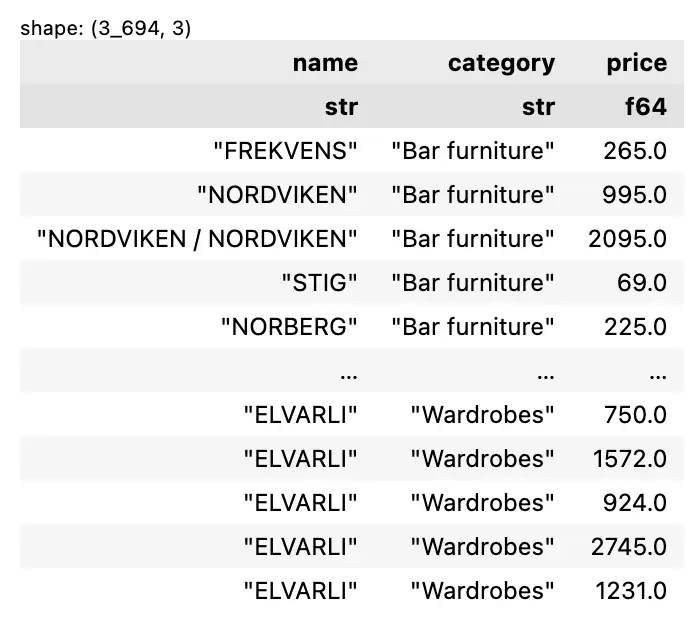
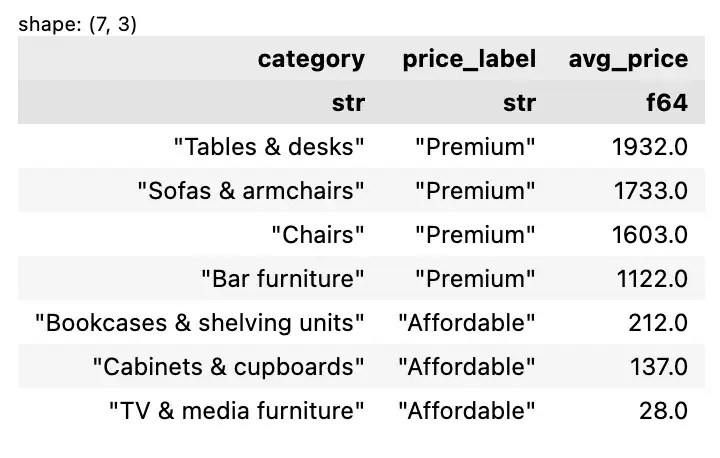
หนังสือ Negotiation Made Simple ของ John Lowry เป็นหนังสือสอนการเจรจา ซึ่งไม่ได้ใช้กับนักธุรกิจเท่านั้น แต่ยังใช้กับคนทั่วไปอีกด้วย
ในบทความนี้ ผมจะมาสรุป 20 ข้อคิดจาก Part II. Ambitious Competition ของหนังสือ ซึ่งจัดได้เป็น 3 กลุ่มดังนี้:
- Competitive Negotiation: แนะนำให้รู้จักกับ competitive negotiation
- First Move: แนะนำการออกแบบและรับมือ first move ใน competitive negotiation
- Concessions: แนะนำวิธีการต่อรองใน competitive negotiation
ถ้าพร้อมแล้ว ไปเริ่มกันเลย

⚔️ Group 1. Competitive Negotiation
ข้อคิด 6 ข้อในกลุ่มแรกแนะนำให้รู้จักกับ competitive negotiation:
- What is competitive negotiation
- Competitive negotiation is not inherently bad
- When to be competitive
- Competitive negotiation is predictable
- Use predictability to your advantage
- Be competitive yet cooperative
.
ข้อ 1. What is competitive negotiation
Competitive negotiation เป็นการเจรจาเพื่อหาผลประโยชน์ใส่ตัวให้ได้มากที่สุด ไม่ว่าอีกฝ่ายจะเสียผลประโยชน์หรือไม่
เช่น การต่อรองราคา เราต้องการส่วนลดให้ได้มากที่สุด ไม่ว่าคนขายจะขาดทุนหรือไม่ก็ตาม
.
ข้อ 2. Competitive negotiation is not inherently bad
Competitive negotiation ไม่ใช่สิ่งไม่ดี และเป็นสิ่งที่จำเป็นในหลาย ๆ ครั้ง
เช่น เด็กที่ถูกพ่อแม่ทำร้าย แต่พ่อแม่ไม่ยอมสละสิทธิเลี้ยงดูลูก เราจะต้องใช้ competitive negotiation (เจรจาแบบมีฝ่ายแพ้ฝ่ายชนะ) เพื่อเรียกร้องสิทธิให้กับเด็ก
.
ข้อ 3. When to be competitive
เราใช้ competitive negotiation ใน 2 กรณี:
- Capture more value: ต่อรองเพื่อให้กอบโกยผลประโยชน์ให้ได้มากที่สุด (เช่น ต่อรองเพื่อให้ส่วนลดและของแถมมากที่สุด)
- Defend yourself: ป้องกันตัวเวลาเจรจากับคนที่ aggressive (เช่น พ่อค้าที่พยายามขายของราคาแพงให้เราอย่างไม่ลดละ)
.
ข้อ 4. Competitive negotiation is predictable
Competitive negotiation มีลักษณะ 8 อย่างที่ตายตัว:
- Limited pie: ผลประโยชน์ที่แบ่งกันได้มีจำกัด
- Zero-sum game: จะต้องมีฝ่ายที่แพ้ (เสียผลประโยชน์) และฝ่ายที่ชนะ (ได้ผลประโยชน์)
- Start from positions: คู่เจรจาเริ่มต้นจาก positions ของตัวเอง (เช่น ราคาขายเริ่มต้น vs ราคาแรกที่เราต่อลงมา)
- Multiple concessions: มีการต่อรองกลับไปกลับมาหลายรอบ
- Concessions get smaller: การต่อรองจะเล็กลงเรื่อย ๆ (เช่น ขอส่วน 1,000 บาท, 500 บาท, 10 บาท)
- The midpoint: การต่อรองจะเข้าใกล้จุดกึ่งกลางระหว่าง positions ของทั้งสองฝ่ายขึ้นเรื่อย ๆ
- The dance is inevitable: เราไม่สามารถข้ามขั้นตอนได้ ถ้าอยากได้สิ่งที่ต้องการ เราจะต้องใจเย็นและยอมต่อรองจนกว่าจะถึง midpoint
- Tension is normal: บรรยากาศจะตึงเครียดขึ้นเรื่อย ๆ
.
ข้อ 5. Use predictability to your advantage
เราสามารถใช้รูปแบบที่ตายตัวของ competitive negotiation เพื่อวางกลยุทธ์ในการต่อรองที่ดีได้
.
ข้อ 6. Be competitive yet cooperative
แม้ว่าการเจรจาจะ competitive (เน้นผลประโยชน์ส่วนตัว) แต่เราสามารถสื่อสารแบบ cooperative (สื่อสารด้วยความเคารพและสุภาพ) ได้
⛳ Group 2. First Move
ข้อคิด 8 ข้อในกลุ่ม 2 แนะนำวิธีออกแบบและรับมือกับ first move ใน competitive negotiation:
- First move is the most important
- Get over your discomfort
- Don’t wait and see
- Drop the anchor
- Don’t be too aggressive
- How to counter anchor bias
- Fight unreasonable offers with unreasonable offers
- Walking away is always an option
.
ข้อ 7. First move is the most important
First move เป็น move ที่สำคัญที่สุด เพราะเป็นสิ่งที่กำหนดทิศทางในการเจรจา
.
ข้อ 8. Get over your discomfort
คนที่เริ่ม first move มักจะรู้สึกกังวลและมีความสุขกับผลลัพธ์สุดท้ายน้อยกว่าคนที่เริ่มทีหลัง
แต่คนเหล่านี้มักได้ผลลัพธ์ที่ดีกว่าอีกฝ่าย
ดังนั้น เราควรจะก้าวข้ามความกังวลและเริ่ม first move ก่อน
.
ข้อ 9. Don’t wait and see
ถ้ารอให้อีกฝ่ายเริ่มก่อน เราจะเสียเปรียบได้ เพราะการตัดสินใจของเราจะถูกตีกรอบด้วย first move ของอีกฝ่าย
.
ข้อ 10. Drop the anchor
First move จะต้องมี anchor หรือสิ่งที่จะตีกรอบการเจรจาและการตัดสินใจของอีกฝ่าย
เช่น ถ้าเราอยากได้ส่วนแบ่งบริษัทเยอะ เราจะต้องเริ่มจากเลขที่สูง (เช่น 70%) เพื่อให้อีกฝ่ายต่อรองลงมาในจุดที่เราต้องการ (50%)
ถ้าเราเริ่มด้วยเลขที่ต่ำ (50%) เราจะถูกต่อลงมาอีก (30%) เพราะอีกฝ่ายจะคิดว่า 50% คือเลขที่สูงแล้ว
.
ข้อ 11. Don’t be too aggressive
อีกฝ่ายมีสิทธิ์จะเดินออกจากการเจรจาตลอดเวลา
เราไม่ควรเริ่ม first move ด้วย anchor ที่สูงเกินไป เพราะอีกฝ่ายอาจจะไม่อยากต่อรองกับเราได้
.
ข้อ 12. How to counter anchor bias
ในกรณีที่เราไม่ได้เริ่มก่อน และอีกฝ่ายทิ้ง anchor แล้ว เราสามารถรับมือได้ 3 วิธี:
- Reject: ถ้าเรารู้ว่า สิ่งที่เสนอเป็นแค่ anchor
- Do research: หาข้อมูลเพิ่ม (เช่น หาว่าราคาที่เสนอมาสูงกว่าตลาดไหม)
- Drop another: ทิ้ง anchor ของเราเอง เพื่อเปลี่ยนกรอบในการตัดสินใจของการเจรจา
.
ข้อ 13. Fight unreasonable offers with unreasonable offers
ถ้าอีกฝ่ายให้ข้อเสนอที่ไม่สมเหตุสมผล (เช่น ราคาสูงกว่าราคาตลาดมาก) เราจะต้องไม่ยื่นข้อเสนอที่สมเหตุสมผลกลับ (ราคาตลาด)
เราต้องยื่นข้อเสนอที่ไม่สมเหตุสมผลเช่นกัน (ราคาที่ต่ำกว่าราคาตลาดมาก) เพื่อปรับให้ midpoint กลับมาอยู่ใกล้จุดที่เราต้องการ (ต่ำกว่าราคาตลาดเล็กน้อย)
.
ข้อ 14. Walking away is always an option
ถ้าข้อเสนอไม่สมเหตุสมผลและอีกฝ่ายไม่ยอมเปลี่ยนข้อเสนอ เราสามารถเดินออกจากการเจรจาได้ตลอดเวลา
🫰 Group 3. Concessions
ข้อคิด 6 ข้อในกลุ่มสุดท้ายแนะนำวิธีการที่ดีในการต่อรอง:
- Concessions are crucial
- The other side also needs a win
- Manage perception
- Don’t take all
- Say no
- Unblock with linkage
.
ข้อ 15. Concessions are crucial
การต่อรองเป็นสิ่งจำเป็น
การเจรจาที่ไม่มีการต่อรองจะทำให้ฝ่ายที่เกี่ยวข้องไม่พอใจ เพราะไม่มีส่วนร่วมในการตัดสินใจ
เช่น เราจะรู้สึกดีกว่า ถ้าได้ต่อรองราคาของจาก 1,000 บาท ลงมาเหลือ 500 บาท มากกว่าถ้าเราซื้อของที่ 500 บาทเลย
ดังนั้น ใน competitive negotiation เราจะต้องออกแบบข้อเสนอที่เผื่อต่อรองด้วย
.
ข้อ 16. The other side also needs a win
แม้ว่าในการเจรจา เราจะเป็นฝ่ายชนะ แต่เราทำให้อีกฝ่ายรู้สึกเป็นฝ่ายชนะด้วย เพราะนักเจรจาที่ดีรู้ว่าจะทำให้ทุกฝ่ายพอใจได้ยังไง
.
ข้อ 17. Manage perception
ทางหนึ่งที่เราช่วยให้อีกฝ่ายรู้สึกเป็นฝ่ายชนะได้ คือ ทำให้รู้สึกเหมือนเราเป็นฝ่ายแพ้ เช่น ทำเป็นลังเลก่อนตอบรับข้อเสนอสุดท้าย แม้ว่าข้อเสนอนั้นเป็นสิ่งที่เราต้องการมาตลอด
.
ข้อ 18. Don’t take all
อีกทางหนึ่ง คือ เหลือผลประโยชน์บางส่วนให้อีกฝ่าย (เช่น ไม่ลดราคาให้ แต่ยอมให้ของแถมเพิ่ม)
.
ข้อ 19. Say no
เราจะต้อง say no บ้าง เพราะจะทำให้อีกฝ่ายรู้สึกว่า ข้อเสนอไม่ได้มาง่ายจนเกินไป และรู้สึกเป็นฝ่ายชนะเมื่อได้อะไรบางอย่างไป
.
ข้อ 20. Unblock with linkage
ถ้าทั้งสองฝ่ายมาถึงทางตัน เราสามารถใช้ linkage หรือการเชื่อมข้อเสนอ เพื่อออกจากทางตันได้
ตัวอย่าง linkage เช่น:
- ถ้าลดราคาให้ เราจะจ่ายเงินสด
- ถ้าซื้อวันนี้ เราจะให้ของแถม
- ถ้าซื้อยกเซ็ต เราจะให้ส่วนลด
🔔 ใครที่ชอบบทความนี้ ฝากกด subscribe และติดตามกันได้ที่:
- Website: shinoshigoto.com
- Facebook: Svaron Solution
- Instagram: @svaronsolution
- Thread: @svaronsolution