
ในบทความนี้ เราจะมาทำความรู้จักกับ logistic regression model รวมทั้งการสร้างและประเมิน logistic regression ด้วย glm(), roc(), และ auc() ในภาษา R กัน
- 📈 Logistic Regression คืออะไร?
- 🔨 วิธีสร้าง Logistic Regression ในภาษา R
- 1️⃣ Step 1. Load the Dataset
- 2️⃣ Step 2. Prepare the Data
- 3️⃣ Step 3. Split the Data
- 4️⃣ Step 4. Train the Model
- 5️⃣ Step 5. Evaluate the Model
- 😺 GitHub
- ✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
📈 Logistic Regression คืออะไร?
Logistic regression เป็น machine learning algorithm ประเภท classification สำหรับทำนายผลลัพธ์ที่มี 2 ค่า (binary) เช่น:
- Spam filter: เป็น spam vs เป็นอีเมลปกติ
- Churn prediction: ลูกค้าจะเลิกใช้บริการ vs ใช้บริการต่อ
- Fraud detection: เป็นธุรกรรมทุจริต vs ไม่ทุจริต
- Disease diagnosis: เป็นโรค vs ไม่เป็นโรค
โดยการทำงานของ logistic regression เป็นการต่อยอดจาก linear regression
ใน linear regression เราหาเส้นตรงที่ช่วยทำนายตัวแปรตาม (y) ด้วยตัวแปรต้น (x) ได้ดีที่สุด ตามสมการเส้นตรง:
y = mx + c
- y = ตัวแปรตาม
- m = ความชันของเส้นตรง
- x ตัวแปรต้น
- c = จุดตัดระหว่าง x และ y
Linear regression ใช้งานได้ดีกับข้อมูลที่เป็น continuous data และความสัมพันธ์ระหว่าง x และ y เป็นเส้นตรง:

แต่เส้นตรงไม่ใช่เส้นที่ดีที่สุด ในการทำนาย y ที่มีเพียง 2 ระดับ:
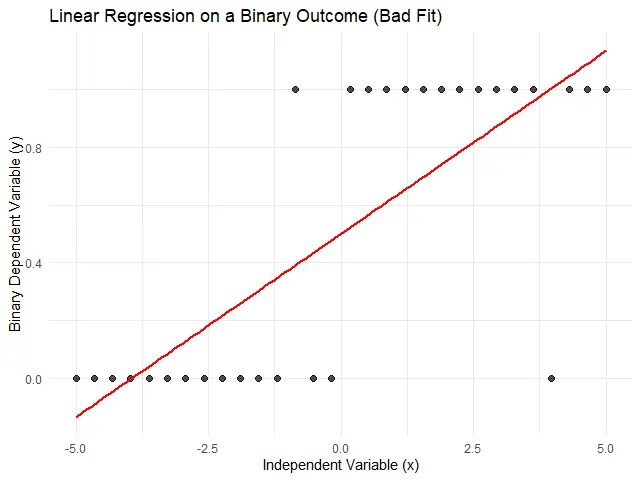
เพื่อแก้ปัญหานี้ เราต้องใช้ logistic regression ซึ่งใช้ sigmoid function ที่ทำนายความเป็นได้ (probability) ที่ y จะตกอยู่ในระดับใดระดับหนึ่ง แทนการทำนายค่า y โดยตรง:
y = sigmoid_func(mx + c)
- y = ตัวแปรตาม
- sigmoid_func = sigmoid function
- m = ความชันของเส้นตรง
- x ตัวแปรต้น
- c = จุดตัดระหว่าง x และ y
เมื่อใช้ sigmoid function เราจะได้เส้นในการทำนายข้อมูลเรียกว่า sigmoid curve ที่ดูคล้ายตัว S ดังภาพ:

🔨 วิธีสร้าง Logistic Regression ในภาษา R
ในภาษา E เราสร้าง logistic regression model ได้ง่าย ๆ ด้วย glm() function โดยทำตาม 5 ขั้นตอนของ machine learning workflow:
- Load the dataset
- Prepare the data
- Split the data
- Train the model
- Evaluate the model
1️⃣ Step 1. Load the Dataset
ในขั้นแรก ให้เราโหลด dataset ที่จะใช้งานเข้ามาใน R
โดยในบทความนี้ เราจะทำงานกับ mtcars dataset ซึ่งมข้อมูลรถจาก ปี ค.ศ. 1974 เช่น รุ่นรถ ระดับการกินน้ำมัน แรงม้า ประเภทเกียร์ และน้ำหนัก
เป้าหมายของเรา คือ สร้าง logistic regression model เพื่อทำนายประเภทเกียร์ ว่า เป็นรถเกียร์ auto (0) หรือ manual (1)
เนื่องจาก mtcars เป็น built-in dataset ในภาษา R เราสามารถโหลดข้อมูลได้ด้วย data() function:
# Load the dataset
data(mtcars)
หลังการโหลด เราสามารถ preview ข้อมูลได้ด้วย head():
# Preview the dataset
head(mtcars)
ผลลัพธ์:
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 manual 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 manual 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 manual 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 automatic 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 automatic 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 automatic 3 1
2️⃣ Step 2. Prepare the Data
สำหรับการสร้าง logistic regression model ตัวแปรตามของเราจะต้องมี data type เป็น factor
เราสามารถเช็ก data type ของ dataset ได้ด้วย str():
# Check the data typs of the columns
str(mtcars)
ผลลัพธ์:
'data.frame': 32 obs. of 11 variables:
$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
$ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
$ disp: num 160 160 108 258 360 ...
$ hp : num 110 110 93 110 175 105 245 62 95 123 ...
$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
$ wt : num 2.62 2.88 2.32 3.21 3.44 ...
$ qsec: num 16.5 17 18.6 19.4 17 ...
$ vs : num 0 0 1 1 0 1 0 1 1 1 ...
$ am : num 1 1 1 0 0 0 0 0 0 0 ...
$ gear: num 4 4 4 3 3 3 3 4 4 4 ...
$ carb: num 4 4 1 1 2 1 4 2 2 4 ...
จากผลลัพธ์ เราจะเห็นได้ว่า am ซึ่งบอกประเภทเกียร์รถ มี data type เป็น num (numeric) แสดงว่า เราจะต้องทำ operation เพื่อเปลี่ยน data type ก่อนไปขั้นต่อไป
เราสามารถเปลี่ยน data type ได้ด้วย factor():
# Convert column `am` to factor
mtcars$am <- factor(mtcars$am,
levels = c(0, 1),
labels = c("automatic", "manual"))
จากนั้น เช็กผลลัพธ์ที่ได้ด้วย str() อีกครั้ง:
# Check the result
str(mtcars)
ผลลัพธ์:
'data.frame': 32 obs. of 11 variables:
$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
$ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
$ disp: num 160 160 108 258 360 ...
$ hp : num 110 110 93 110 175 105 245 62 95 123 ...
$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
$ wt : num 2.62 2.88 2.32 3.21 3.44 ...
$ qsec: num 16.5 17 18.6 19.4 17 ...
$ vs : num 0 0 1 1 0 1 0 1 1 1 ...
$ am : Factor w/ 2 levels "automatic","manual": 2 2 2 1 1 1 1 1 1 1 ...
$ gear: num 4 4 4 3 3 3 3 4 4 4 ...
$ carb: num 4 4 1 1 2 1 4 2 2 4 ...
จะเห็นว่า ตอนนี้ am เป็น factor แล้ว และเราสามารถไปขั้นตอนถัดไปได้
3️⃣ Step 3. Split the Data
ในขั้นที่สาม เราจะต้องแบ่ง dataset เป็น 2 ชุด ได้แก่:
- Training set สำหรับสร้าง model
- Test set สำหรับประเมินความสามารถของ model
เราแบ่ง dataset ได้โดยเริ่มจากสร้าง row index ที่จะอยู่ใน training set:
# Set seed for reproducibility
set.seed(300)
# Create a training index
train_index <- sample(1:nrow(mtcars),
nrow(mtcars) * 0.7)
Note: เรากำหนด row index ใน training set เป็น 70% แสดงว่า test set จะมีข้อมูล 30% จาก dataset
จากนั้น ใช้ row index แบ่ง dataset เป็น 2 ชุด:
# Create training and test sets
train_set <- mtcars[train_index, ]
test_set <- mtcars[-train_index, ]
ตอนนี้ เราพร้อมที่จะสร้าง model กันแล้ว
4️⃣ Step 4. Train the Model
ในขั้นที่สี่ เราจะสร้าง logistic regression model โดยใช้ glm() function กัน
glm() ต้องการ input 3 อย่าง:
glm(formula, data, family)
| No. | Input | คำอธิบาย | ในบทความนี้ |
|---|---|---|---|
| 1 | formula | ตัวแปรตามที่ต้องการทำนาย และตัวแปรต้นที่จะใช้ทำนาย | am ~ . |
| 2 | data | ชุดข้อมูลที่จะใช้สร้าง model | train_set |
| 3 | family | Regression algorithm ที่เราจะเรียกใช้ | "binomial" |
# Build a logistic regression model
log_reg <- glm(am ~ .,
data = train_set,
family = "binomial")
ตอนนี้ เราก็จะได้ logistic regression model ในการทำนายประเภทเกียร์มาเรียบร้อย
5️⃣ Step 5. Evaluate the Model
ในขั้นสุดท้าย เราจะประเมินความสามารถของ model ในการทำนายประเภทเกียร์กัน
เราจะใช้ 3 metrics ในการประเมิน:
- Accuracy: สัดส่วนของผลลัพธ์ที่ทำนายถูก
- ROC curve: กราฟแสดงความสัมพันธ์ระหว่าง true positive rate (TPR) และ false positive rate (FPR) โดยยิ่งเส้นกราฟออกห่างเหนือเส้นตรงมากเท่าไรก็ยิ่งดี
- AUC: พื้นที่ใต้กราฟของ ROC โดยมีค่าระหว่าง 0 กับ 1 โดยค่ายิ่งเข้าใกล้ 1 เท่าไรก็ยิ่งดี
.
⚖️ Threshold
ในการคำนวณทั้ง 3 metrics เราจะต้องกำหนด threshold เพื่อทำนายปรพเภทเกียร์ก่อน เพราะ glm() ให้ model ที่ส่งค่าความเป็นไปได้ (แทนประเภทเกียร์) กลับมา เช่น:
- 0.45
- 0.32
- 0.93
Threshold จะเป็นค่าที่ระบุประเภทเกียร์ให้เรา เช่น เรากำหนด threshold ที่ 0.30:
| ความเป็นไปได้ | เทียบกับ 0.30 | ประเภทเกียร์ที่ทำนาย |
|---|---|---|
| 0.45 | > 0.30 | Manual |
| 0.32 | > 0.30 | Manual |
| 0.93 | > 0.30 | Manual |
หรือ threshold ที่ 0.80:
| ความเป็นไปได้ | เทียบกับ 0.80 | ประเภทเกียร์ที่ทำนาย |
|---|---|---|
| 0.45 | < 0.80 | Auto |
| 0.32 | < 0.80 | Auto |
| 0.93 | > 0.80 | Manual |
จะเห็นว่า threshold ที่เรากำหนด มีผลต่อผลลัพธ์ในการทำนาย
Note: ทั้งนี้ threshold ที่ดีที่สุดขึ้นอยู่กับแต่ละ model
ในบทความนี้ เราจะลองกำหนด threshold ไว้ที่ 0.50
เมื่อกำหนด threshold แล้ว เราจะใช้ predict() เพื่อสร้าง column ที่เก็บค่าความเป็นไปได้ ใน test_set:
# Get predictive probability
test_set$pred_prob <- predict(log_reg,
newdata = test_set,
type = "response")
จากนั้น ใช้ ifelse() และ threshold เพื่อทำนายประเภทเกียร์:
# Predict the outcome
test_set$pred <- ifelse(test_set$pred_prob > 0.5,
1,
0)
# Set column `pred ` as factor
test_set$pred <- factor(test_set$pred,
levels = c(0, 1),
labels = c("automatic", "manual"))
จากนั้น เราดูผลลัพธ์ได้ด้วย head():
# Check the results
head(test_set[c("pred_prob", "pred", "am")])
ผลลัพธ์:
pred_prob pred am
Datsun 710 1.000000e+00 manual manual
Hornet 4 Drive 2.220446e-16 automatic automatic
Merc 240D 9.999999e-01 manual automatic
Merc 280C 2.220446e-16 automatic automatic
Cadillac Fleetwood 2.220446e-16 automatic automatic
Chrysler Imperial 3.941802e-11 automatic automatic
ตอนนี้ เราได้ผลลัพธ์ในการทำนายมา และพร้อมที่จะคำนวณ metrics ในการประเมินแล้ว
.
🎯 Metric #1. Accuracy
เรามาคำนวณแต่ละ metric กัน โดยเริ่มจาก accuracy
สำหรับ accuracy เราจะสร้าง confusion matrix ที่เปรียบการทำนายและประเภทเกียร์จริง ๆ ในข้อมูล:
# Create a confusion matrix
cm <- table(Predicted = test_set$pred,
Actual = test_set$am)
# Print cm
print(cm)
ผลลัพธ์:
Actual
Predicted automatic manual
automatic 6 1
manual 1 2
จากนั้น เรานำสัดส่วนผลลัพธ์ที่ทำนายถูกมาหารด้วยผลลัพธ์ทั้งหมด:
# Compute accuracy
accuracy <- sum(diag(cm)) / sum(cm)
# Print accuracy
cat("Accuracy:", round(accuracy, 2))
ผลลัพธ์:
Accuracy: 0.8
จะเห็นได้ว่า model มีความแม่นยำในการทำนายอยู่ที่ 80%
.
📈 Metric #2. ROC Curve
สำหรับการสร้าง ROC curve เราจะเรียกใช้ roc() function จาก pROC package
Note: ในการใช้งาน pROC package ให้รันคำสั่ง install.packages("pROC") เพื่อติดตั้ง และ library(pROC) เพื่อเรียกใช้งาน
roc() ต้องการ input 2 อย่าง:
roc(actual, predicted)
- actual = ประเภทเกียร์ในข้อมูลจริง
- predicted = ความเป็นไปได้ในการทำ
# Calculate ROC
ROC <- roc(test_set$am,
pred_prob)
จากนั้น เราสร้างกราฟ ROC curve ด้วย plot():
# Plot ROC
plot(ROC,
main = "ROC Curve",
col = "blue",
lwd = 2)
ผลลัพธ์:
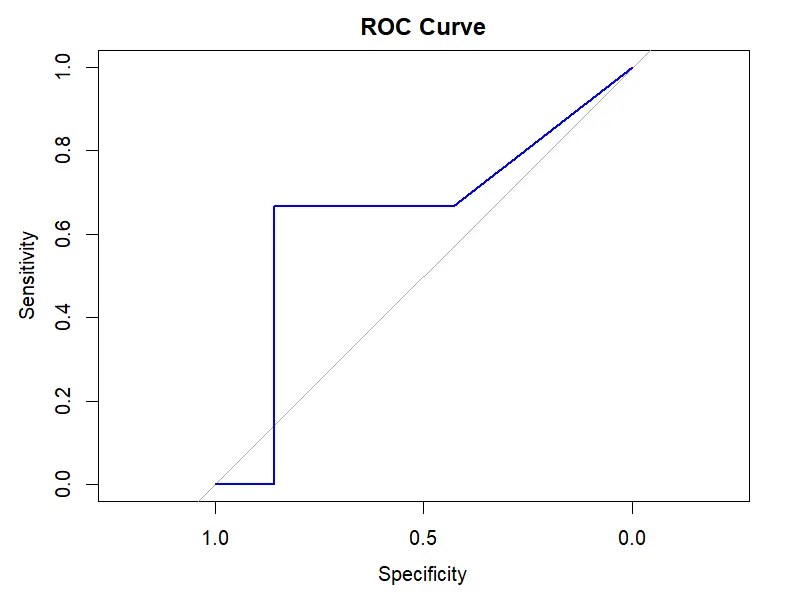
จากกราฟ ดูเหมือนว่า model ของเราอาจจะไม่ได้ทำได้ดีเท่ากับ accuracy เพราะเส้นกราฟ (สีน้ำเงิน) ไม่ได้ออกห่างจากเส้นตรงมากนัก และมีบางส่วนที่อยู่ใต้เส้นตรง
.
📉 Metric #3. AUC
สุดท้าย เรามาคำนวณพื้นที่ใต้กราฟ ด้วย auc() จาก pROC() package เพื่อดูว่า การตีความ ROC curve เป็นอย่างอย่างที่เราคิดไหม:
# Calculate AUC
AUC <- auc(ROC)
# Print AUC
print(AUC)
ผลลัพธ์:
Area under the curve: 0.6429
จะเห็นได้ว่า model ของเรายังมีประสิทธิภาพไม่ดีมาก เพราะมีค่าน้อยกว่า 1 มาก ซึ่งเป็นไปตามการอ่าน ROC curve ก่อนหน้านี้
Note: จากผลลัพธ์ เราอาจจะอยากไปปรับปรุง model ของเรา ซึ่งเราสมารถทำได้ 2 วิธี:
- เพิ่มข้อมูลใน training set
- ปรับ threshold
😺 GitHub
ดู code ทั้งหมดในบทความนี้ได้ที่ GitHub
📃 References
- Supervised Learning in R: Classification
- อธิบาย Logistic Regression พร้อมโค้ดตัวอย่างใน R
- Logistic Regression in R Tutorial
- What is logistic regression?
- Logistic Regression in R Programming
- AUC and the ROC Curve in Machine Learning
✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
📕 ขอฝากหนังสือเล่มแรกในชีวิตด้วยนะครับ 😆
🙋 ใครที่กำลังเรียนจิตวิทยาหรือทำงานสายจิตวิทยา และเบื่อที่ต้องใช้ software ราคาแพงอย่าง SPSS และ Excel เพื่อทำข้อมูล
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
- Correlation
- t-tests
- ANOVA
- Reliability
- Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
แล้วทุกคนจะแปลกใจว่า ทำไมภาษา R ง่ายขนาดนี้ 🙂↕️
👉 สนใจดูรายละเอียดหนังสือได้ที่ meb:

Leave a reply to Machine Learning in R: รวบรวม 13 บทความสอนสร้าง machine learning ในภาษา R – Shi no Shigoto Cancel reply