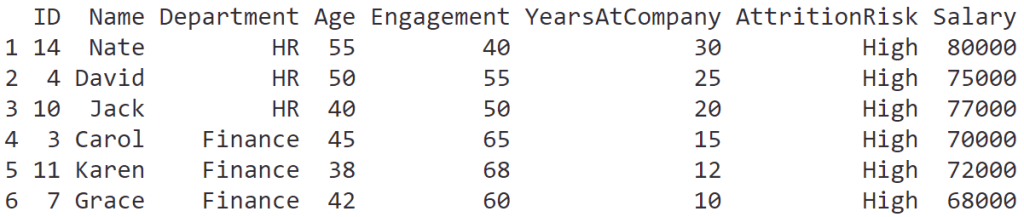ในบทความนี้ เราจะมาทำความรู้จักภาษา R กัน:
- ภาษา R คืออะไร?
- R แตกต่างกับ Python ยังไง?
- พื้นฐานการเขียนภาษา R
ถ้าพร้อมแล้วมาเริ่มกันเลย
- 😆 ภาษา R คืออะไร?
- 🐍 R vs Python: แตกต่างกันยังไง?
- 🌏 Objects & Functions: โลกทั้งใบของ R
- 🧘 Objects: Existing in R
- 👟 Functions: Happening in R
- 💪 Summary
- ⏭️ Learn More About R
- 📄 References
- ✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
😆 ภาษา R คืออะไร?
R เป็นภาษาคอมพิวเตอร์ที่ถูกพัฒนาขึ้นในช่วง ค.ศ. 1990 โดยนักสถิติ 2 ท่านจาก University of Auckland ในนิวซีแลนด์:
- Ross Ihaka
- Robert Gentleman
โดยทั้งคู่พัฒนา R เพื่อทำงานกับข้อมูลในห้องแล็บโดยเฉพาะ
และด้วยเหตุที่ R ถูกออกแบบมาเพื่อทำงานกับข้อมูล จึงได้ชื่อว่าเป็น “statistical programming language”
Note: ตัวอักษรแรกของนักพัฒนาเป็นที่มาของชื่อภาษา
.
เพราะ R เป็นภาษาสำหรับ data จึงเป็นที่นิยมในสายอาชีพ data อย่าง:
- Data analyst
- Data scientist
- Business intelligence analyst
- Statistician
- Researcher
.
ในปัจจุบัน (Jan 2025) R ได้รับความนิยมเป็นอันดับ 18 ของโลก (อ้างอิง TIOBE index):
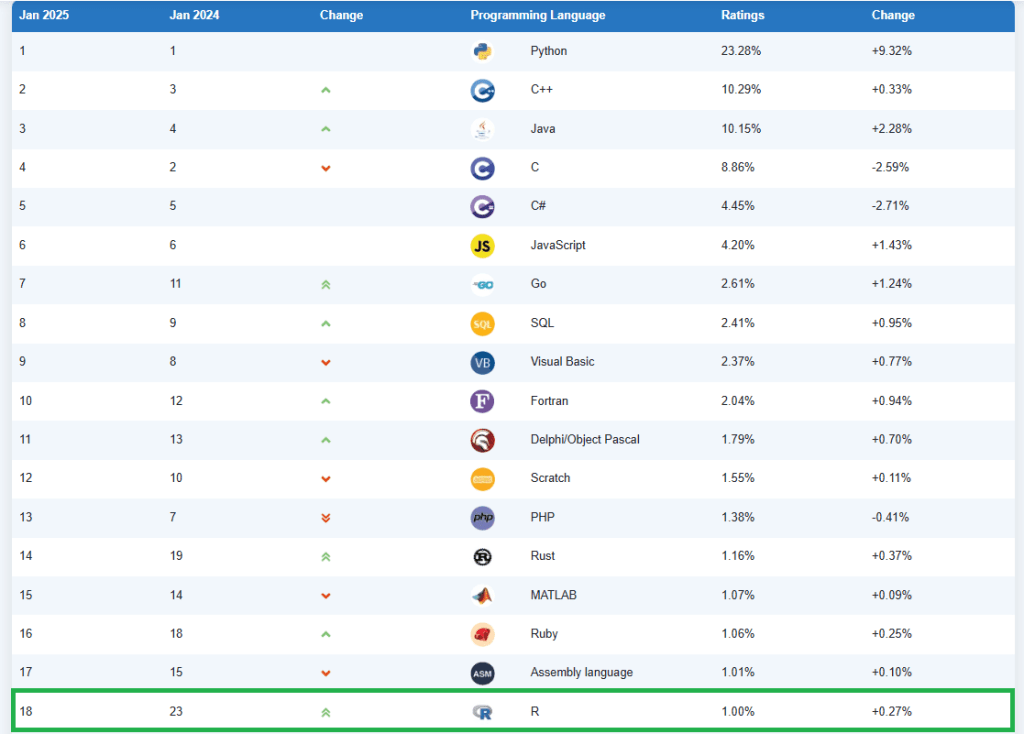
นอกจากเป็นภาษา data แล้ว R ยังได้รับความนิยม เพราะ:
- เป็นภาษา open source
- ผู้ใช้งานสามารถสร้าง package (library) ในการวิเคราะห์ข้อมูลเองได้
- ผู้ใช้สามารถใช้ package ที่คนอื่นเขียนไว้แล้ว มาวิเคราะห์ข้อมูลได้ (ในปัจจุบัย R มี package ให้เลือกใช้งานมากกว่า 17,000 packages)
- ใช้งานได้กับหลากหลาย OS เช่น Windows, MacOS, และ Linux
🐍 R vs Python: แตกต่างกันยังไง?
ทั้ง R และ Python ต่างได้เป็นที่นิยมในสายงาน data science และมีลักษณะที่คล้ายกัน คือ:
- เป็นภาษา open source
- มี community ผู้ใช้งานขนาดใหญ่
- มี packages ให้เลือกใช้จำนวนมาก
แต่ R และ Python จุดที่แตกต่างกัน คือ:
| R | Python |
|---|---|
| เหมาะกับการทำงาน data โดยเฉพาะการวิเคราะห์สถิติเชิงลึก | เป็นภาษาสำหรับงานทั่วไป (general-purpose) รองรับการใช้งานหลายประเภทกว่า R |
ดังนั้น แม้ว่า R อาจจะสามารถทำงานนอกเหนือจากงาน data ได้ (เช่น web scrapping) แต่อาจจะไม่ดีเท่ากับ Python ที่ถูกออกแบบมาให้ใช้งานทั่วไป
.
Note:
สำหรับคนที่สนใจสายงาน data ควรเลือกศึกษาทั้ง 2 ภาษา
แต่การจะหยิบมาใช้งาน ขึ้นอยู่กับงานตรงหน้า:
| R | Python |
|---|---|
| งานวิจัยและการวิเคราะห์ข้อมูลเชิงลึก เช่น สร้างโมเดลทางสถิติ รวมทั้งการสร้างกราฟจากข้อมูลอย่างง่าย | งานที่ต้องมีความยืดหยุ่น เช่น machine learning และ AI หรืองานที่ต้อง integrate กับเครื่องมืออื่น ๆ เช่น web scrapping และ software development |
🌏 Objects & Functions: โลกทั้งใบของ R
หลังจากทำความรู้จักความรู้จักกับ R เบื้องต้นแล้ว เรามาดูหลักการทำงานของ R กัน
ในการทำงานกับ R เราต้องเข้าใจก่อนว่า ทุกสิ่งที่อยู่ใน R ประกอบด้วย 2 อย่าง ได้แก่:
| Object | Function |
|---|---|
| สิ่งที่เก็บใน R | สิ่งที่เกิดขึ้นใน R |
นั่นคือ:
- ทุกสิ่งที่เราสร้างขึ้นใน R จะถูกเก็บอยู่ใน objects (เช่น ตัวแปร, ข้อมูล)
- Functions เป็นสิ่งที่เรากระทำกับ objects (เช่น การคำนวณ การสร้างกราฟ)
เมื่อเราเข้าใจแล้ว เราสามารถทำความเข้าใจ concepts อื่น ๆ ของ โดยการต่อยอดจาก 2 องค์ประกอบนี้
🧘 Objects: Existing in R

ในส่วน objects เรามี 3 สิ่งที่ต้องความเข้าใจ เพื่อทำงานกับ R:
- Variables
- Data types and classes
- Data structures
.
📦 (1) Variables: การประกาศตัวแปรใน R
Variable หรือตัวแปร เป็นเหมือนกล่องเก็บของที่เก็บข้อมูลไว้ให้เรา
เราสามารถสร้างตัวแปรด้วยการใช้ <- เช่น:
x <- 10
อย่างในตัวอย่าง เป็นการสร้างตัวแปร x ที่เก็บค่าตัวเลข 10 เอาไว้
Note: เราสามารถใช้ = แทน <- ได้ แต่ไม่เป็นที่นิยมกัน
.
🍱 (2) Data Types & Classes: ประเภทข้อมูลใน R
ตัวแปรใน R สามารถเก็บข้อมูลได้หลายประเภท (เช่น ตัวเลข ข้อความ)
เราต้องทำความเข้าใจประเภทของข้อมูล เพราะเป็นตัวกำหนด functions ที่เราสามารถใช้ทำงานกับ variable นั้นได้
ยกตัวอย่างเช่น x เก็บตัวแปรประเภทตัวเลข เราจะไม่สามารถใช้ functions ที่ทำงานกับตัวอักษรได้
.
ทั้งนี้ ประเภทข้อมูลใน R มีอยู่ 5 ประเภทที่มักใช้บ่อย ได้แก่:
| No. | Data Type | Example |
|---|---|---|
| 1 | Numeric | 100 |
| 2 | Character | "One hundred" |
| 3 | Logical | TRUE, FALSE |
| 4 | Date | 2025-01-15 |
| 5 | Factor | "male", "female", "other" |
.
ตัวอย่าง 👇
Numeric:
age <- 10
Character:
name <- "Ben Tennyson"
Logical:
is_hero <- TRUE
Date:
date_of_birth <- as.Date("1995-12-27")
Factor:
gender <- as.factor("Male")
.
Note: เราสามารถเช็กประเภทข้อมูลของตัวแปร ได้ด้วย class() เช่น:
class(age)
ผลลัพธ์:

.
🏠 (3) Data Structures: โครงสร้างข้อมูลใน R
Data structure เป็นการนำข้อมูลมาจัดเรียงเป็นโครงสร้างที่ใหญ่ขึ้น
Data structures เป็นเหมือนอิฐที่ประกอบกันเป็นบ้านหรือตึกใน R
.
โครงสร้างข้อมูลใน R มีอยู่ 5 ประเภท ซึ่งแบ่งได้เป็น 2 กลุ่มตามมิติในการเก็บข้อมูล ดังนี้:
.
กลุ่มที่ 1: เก็บข้อมูลได้ 1 ประเภทเท่านั้น
| No. | Data Structure | การเก็บข้อมูล |
|---|---|---|
| 1 | Vector | 1 มิติ |
| 2 | Matrix | 2 มิติ |
| 3 | Array | n มิติ |
.
ตัวอย่าง 👇
Vector:
v <- c(1, 3, 5, 7, 9)
ผลลัพธ์:
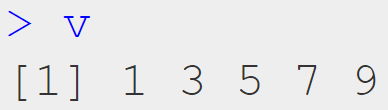
Matrix:
m <- matrix(1:9, ncol = 3)
ผลลัพธ์:
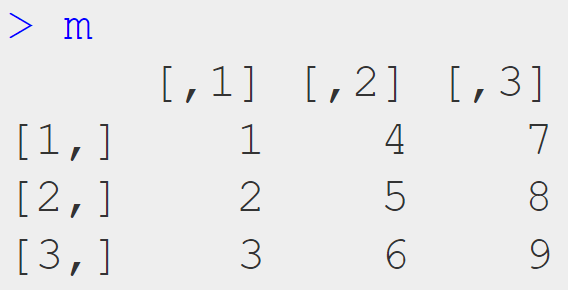
Array:
เช่น array แบบ 3 มิติ:
- 4 rows
- 3 columns
- 2 ชั้น
a <- array(1:24, dim = c(4, 3, 2))
ผลลัพธ์:

.
กลุ่มที่ 2: เก็บข้อมูลได้มากกว่า 1 ประเภท
| No. | Data Structure | การเก็บข้อมูล |
|---|---|---|
| 1 | List | 1 มิติ |
| 2 | Data frame | 2 มิติ |
.
ตัวอย่าง 👇
List:
เพราะ list สามารถเก็บข้อมูลได้หลายประเภท เราสามารถใส่อะไรลงใน list ก็ได้ (แม้แต่ data structure อื่น ๆ):
grocery_list = list("apple",
"milk",
TRUE,
250,
c(1, 3, 5, 7, 9),
list("Walmart", "Target"))
ผลลัพธ์:

Data frame:
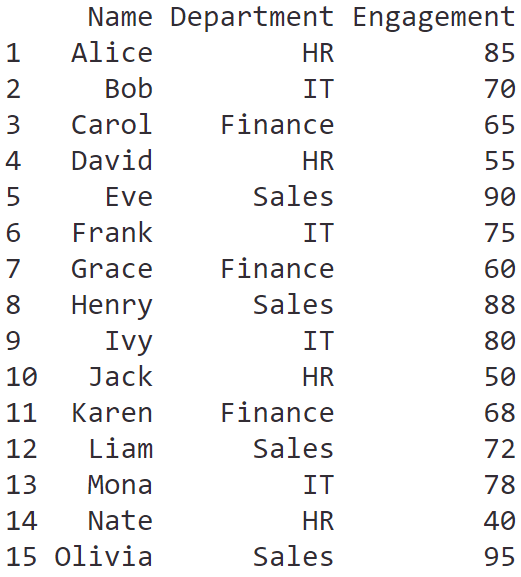
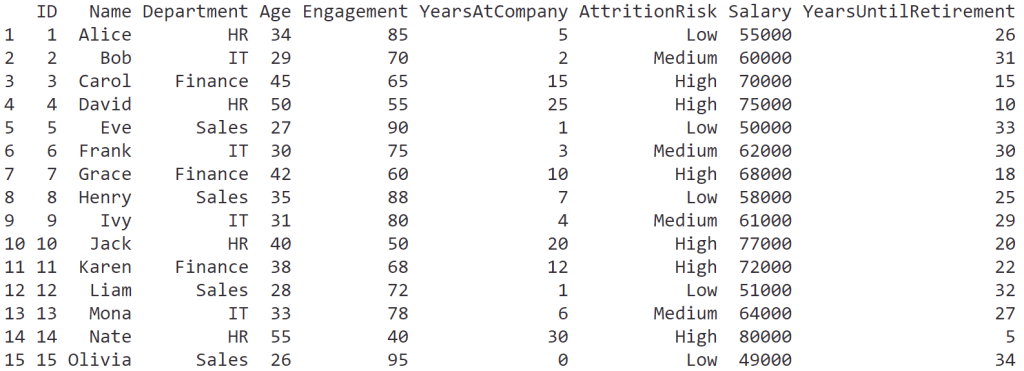
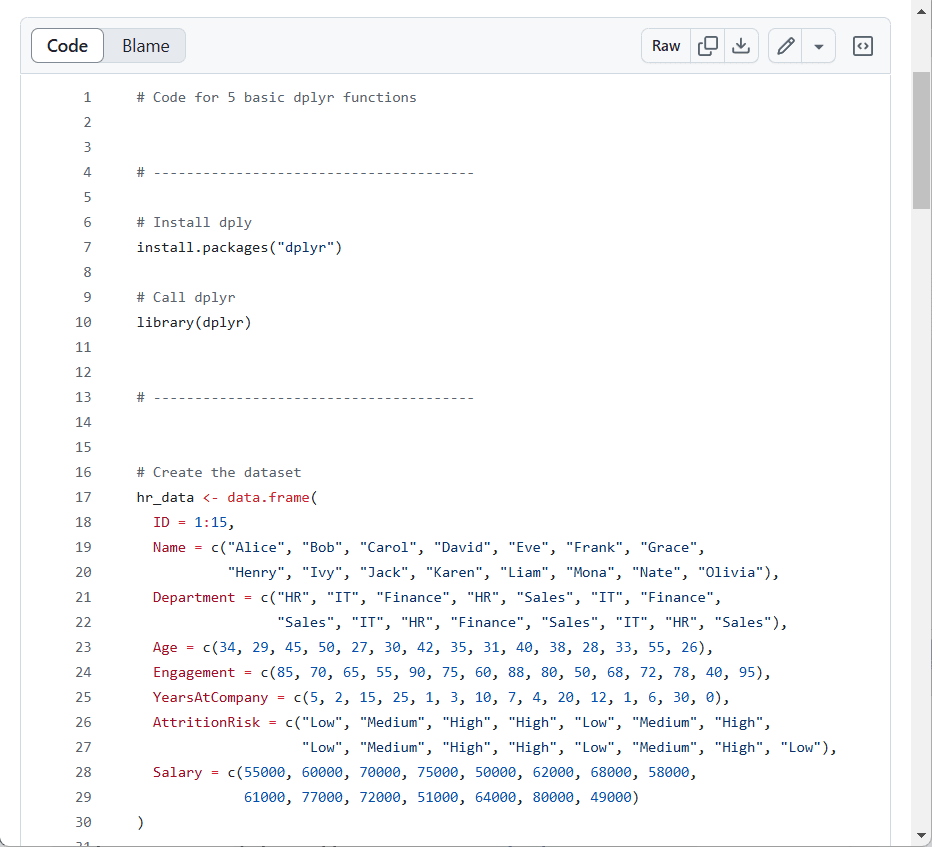
สำหรับ data frame เราสามารถสร้างได้จากเชื่อม vectors เข้าด้วยกัน:
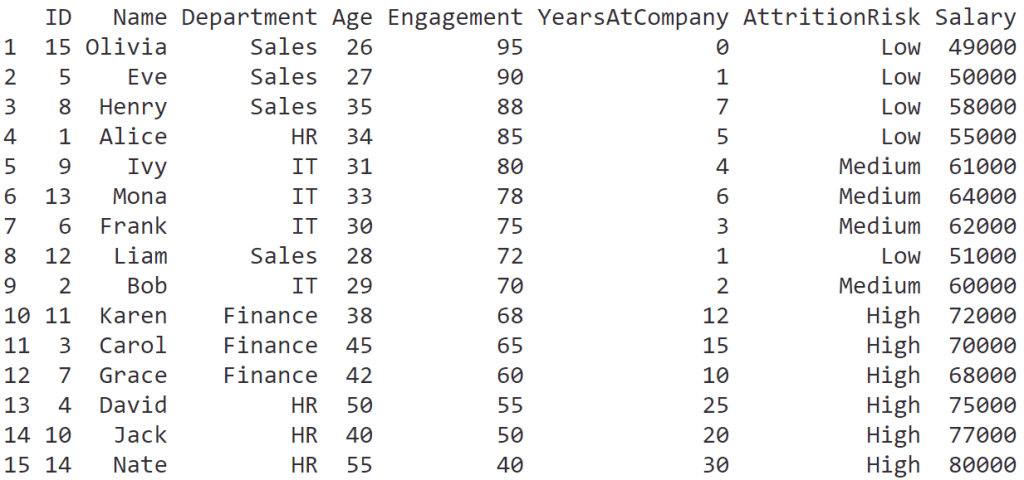
groceries <- data.frame(
Item = c("Apples", "Carrots", "Milk"),
Category = c("Fruit", "Vegetable", "Dairy"),
Quantity = c(5, 2, 1),
Price = c(1.50, 0.75, 2.50)
)
ผลลัพธ์:

.
Note: สำหรับใครที่นึกภาพโครงสร้างข้อมูลไม่ออก สามารถดู Figure 5.6 ในหนังสือ Hands-On R Programming เพื่อช่วยไขข้อสงสัยได้
👟 Functions: Happening in R

สำหรับ functions เรามี 2 สิ่งที่ต้องทำความเข้าใจ ได้แก่:
- Operators
- Functions
.
🧮 (1) Operators: เครื่องหมายใน R
Operators เป็นเครื่องหมาย เพื่อบอก R ว่าเราต้องการทำงานหรือการคำนวณอะไร
.
Operators แบ่งออกเป็น 4 ประเภท ได้แก่:
| No. | Operator | For | Symbols |
|---|---|---|---|
| 1 | Assignment | สร้าง variable | <-= |
| 2 | Arithmetic | คิดเลข | +-*/ |
| 3 | Logical | คิดตรรกะ | &|! |
| 4 | Relational | เปรียบเทียบค่า | ==!=><>=<= |
.
ตัวอย่าง 👇
Assignment
เช่น สร้างตัวแปรเก็บชื่อ “John”:
my_name <- "John"
Arithmetic
เช่น คิดเลข 3 + 4:
3 + 4
Logical
เช่น not TRUE:
!TRUE
Relational
เช่น เช็กว่า 15 มากกว่า 11 ไหม:
15 > 11
.
🔨 (2) Functions: Action ใน R
Functions คือ code ที่เราสามารถนำกลับมาใช้ใหม่ได้ (reusable)
.
Functions แบ่งออกเป็น 2 ประเภท ได้แก่:
| No. | Function | Description | Example |
|---|---|---|---|
| 1 | Built-in | Functions ที่มาพร้อม R หรือ packages ที่เราโหลดมาใช้งาน | print()sum()str() |
| 2 | User-defined | Functions ที่เราสร้างเอง | สร้าง function ชื่อ hello() เพื่อทักทาย user |
.
Note:
สำหรับ user-defined functions เราสามารถสร้างได้โดยใช้ function() เช่น:
greeting <- function(name) {
print(paste("Hello", name))
}
ถ้าเราเรียกใช้งาน greeting() โดยใส่ "John" ใน ():
greeting("John")
เราจะได้ผลลัพธ์แบบนี้:

💪 Summary
ในบทความนี้ เราได้ทำความรู้กับภาษา R กัน:
- R เป็นภาษาสำหรับงาน data
- ทั้ง R และ Python ใช้กับงาน data ได้
- R เหมาะกับการวิเคราะห์เชิงลึก
- Python เหมาะกับงานทั่วไป
- คนที่สนใจงานสาย data ควรเรียนทั้ง 2 ภาษา
- ทุกอย่างใน R แบ่งเป็น objects และ functions
- Objects: สิ่งที่เก็บใน R
- Variables: เก็บข้อมูล
- Data types and classes: กำหนด functions
- Data structures: ประกอบร่างข้อมูล
- Functions: สิ่งที่เกิดขึ้นใน R
- Operators: เครื่องหมายในการทำงาน
- Functions: code ที่นำกลับมาใช้ใหม่ได้
⏭️ Learn More About R
.
🧑💻 GitHub
สำหรับผู้ที่สนใจ สามารถดู code ตัวอย่างในบทความนี้ได้ที่ GitHub
.
🔨 Free Tool
เริ่มทดลองเขียน R ด้วยตัวเอง ผ่าน RStudio
- ติดตั้งและใช้งานบน desktop : https://posit.co/downloads/
- ใช้งาน online: https://posit.cloud/
ดาวน์โหลด R
Note: ใช้งานฟรีทั้งแบบ desktop และ online
.
📗 Free e-Books
ใครที่สนใจเรียนรู้เกี่ยวกับ R เพิ่มเติม สามารถอ่านหนังสือ e-book เหล่านี้ได้ฟรี:
- An Introduction to R
- Hands-On Programming with R
- R for Data Science
- Advanced R
- The R Researcher’s companion v. 0.01
.
🏫 Free Courses
สำหรับคนที่สนใจเรียนการเขียน R สามารถศึกษาคอร์สเรียนเหล่านี้ได้:
- R Crash Course จาก DataRockie
- HarvardX: Data Science: R Basics จาก edX
📄 References
- ภาษา R สำหรับงาน Data Science เบื้องต้น ครบจบในบทความเดียว
- อยากเขียนเป็นไวๆต้องอ่าน! สรุป 5 Concepts พื้นฐานของภาษา R
- Python vs R เรียนภาษาไหนดี สำหรับงาน Data Science
- ภาษาอาร์พื้นฐาน (Basic R Programming)
- ความแตกต่างระหว่าง ภาษา R กับ Python เรียนภาษาไหนดี ?
- What is R? – An Introduction to The Statistical Computing Powerhouse
- Python vs. R: What’s the Difference?
✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
📕 ขอฝากหนังสือเล่มแรกในชีวิตด้วยนะครับ 😆
🙋 ใครที่กำลังเรียนจิตวิทยาหรือทำงานสายจิตวิทยา และเบื่อที่ต้องใช้ software ราคาแพงอย่าง SPSS และ Excel เพื่อทำข้อมูล
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
- Correlation
- t-tests
- ANOVA
- Reliability
- Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
แล้วทุกคนจะแปลกใจว่า ทำไมภาษา R ง่ายขนาดนี้ 🙂↕️
👉 สนใจดูรายละเอียดหนังสือได้ที่ meb: