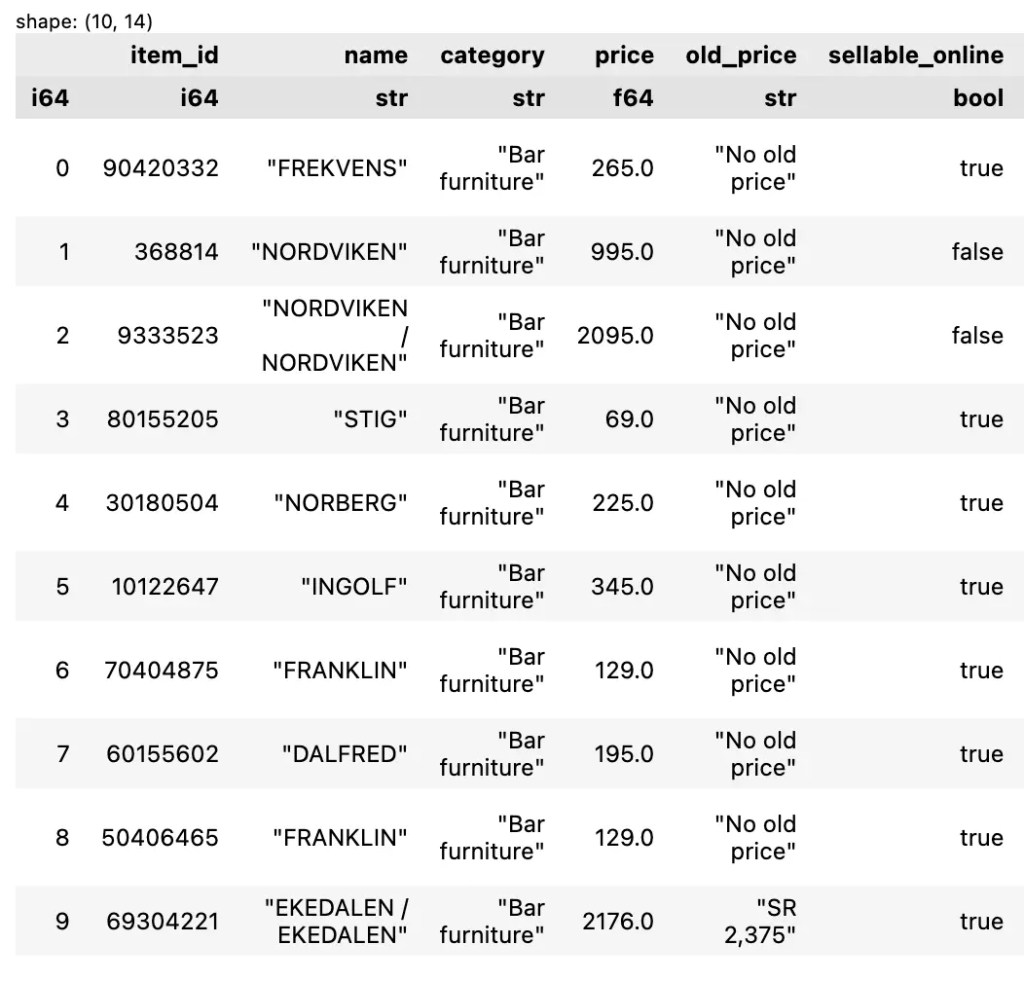
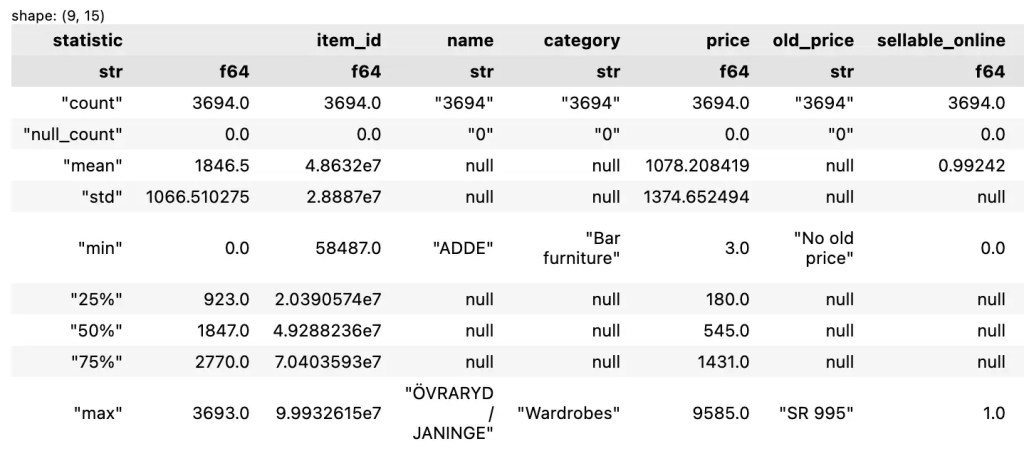
pandas เป็น Python library สำหรับทำงานกับข้อมูลในรูปแบบตาราง (tabular data) และมี functions หลากหลายสำหรับโหลดข้อมูลเข้ามาใน Python
โดยหนึ่งใน functions ที่นิยมใช้กันมากที่สุด ได้แก่ read_csv() ซึ่งใช้โหลดข้อมูล CSV (Comma-Separated Values) และมี arguments หลัก 9 อย่าง ได้แก่:
filepath_or_buffer: file path, ชื่อไฟล์, หรือ URL ของไฟล์ที่ต้องการโหลดsep: กำหนด delimiterheader: กำหนด row ที่เป็นหัวตารางskiprows: กำหนด rows ที่ไม่ต้องการโหลดnrows: เลือกจำนวน rows ที่ต้องการโหลดusecols: กำหนด columns ที่ต้องการโหลดindex_col: กำหนด column ที่จะเป็น indexnames: กำหนดชื่อของ columnsdtype: กำหนดประเภทข้อมูล (data types) ของ columns
ในบทความนี้ เราจะมาดูวิธีใช้ทั้ง 9 arguments ของ read_csv() เพื่อโหลดตัวอย่างข้อมูลการแข่งขันฟุตบอลในอังกฤษกัน
ถ้าพร้อมแล้ว ไปเริ่มกันเลย
- 🏁 Getting Started
- 🗃️ Argument #1. filepath_or_buffer
- 🤺 Argument #2. sep
- 😶🌫️ Argument #3. header
- 🛑 Argument #4. skiprows
- 📋 Argument #5. nrows
- ☑️ Argument #6. usecols
- 🔢 Argument #7. index_col
- 🔠 Argument #8. names
- ⏹️ Argument #9. dtype
- ⚡ Summary
- 😺 GitHub
- 📃 References
🏁 Getting Started
ก่อนเริ่มใช้งาน read_csv() เราต้องติดตั้งและโหลด pandas ก่อน:
# Install pandas
!pip install pandas
# Import pandas
import pandas as pd
Note: ในกรณีที่เราเคยติดตั้ง pandas แล้วให้ใช้คำสั่ง import อย่างเดียว
🗃️ Argument #1. filepath_or_buffer
filepath_or_buffer เป็น argument หลักที่เราจะต้องกำหนดทุกครั้งที่เรียกใช้ read_csv()
ยกตัวอย่างเช่น เรามีข้อมูลการแข่งขันฟุตบอล (matches_clean.csv):
MatchID,HomeTeam,AwayTeam,HomeGoals,AwayGoals,MatchDate
M001,Manchester United,Chelsea,2,1,2024-08-14
M002,Liverpool,Arsenal,1,1,2024-08-20
M003,Tottenham,Everton,3,0,2024-09-02
M004,Man City,Aston Villa,4,2,2024-09-15
M005,Newcastle,West Ham,0,0,2024-09-22
M006,Brighton,Leeds,2,3,2024-09-29
เราสามารถใช้ read_csv() ได้แบบนี้:
# Load the dataset
df1 = pd.read_csv("matches_clean.csv")
# View the result
print(df1)
ผลลัพธ์:
MatchID HomeTeam AwayTeam HomeGoals AwayGoals MatchDate
0 M001 Manchester United Chelsea 2 1 2024-08-14
1 M002 Liverpool Arsenal 1 1 2024-08-20
2 M003 Tottenham Everton 3 0 2024-09-02
3 M004 Man City Aston Villa 4 2 2024-09-15
4 M005 Newcastle West Ham 0 0 2024-09-22
5 M006 Brighton Leeds 2 3 2024-09-29
🤺 Argument #2. sep
sep ใช้กำหนด delimiter หรือเครื่องหมายในการแบ่ง columns โดย default ของ sep คือ "," ทำให้ปกติ เราไม่ต้องกำหนด sep เมื่อไฟล์เป็น CSV
เราจะใช้ sep เมื่อข้อมูลมี delimiter อื่น เช่น ";" (matches_semicolon.txt):
MatchID;HomeTeam;AwayTeam;HomeGoals;AwayGoals;MatchDate
M001;Manchester United;Chelsea;2;1;2024-08-14
M002;Liverpool;Arsenal;1;1;2024-08-20
M003;Tottenham;Everton;3;0;2024-09-02
M004;Man City;Aston Villa;4;2;2024-09-15
M005;Newcastle;West Ham;0;0;2024-09-22
M006;Brighton;Leeds;2;3;2024-09-29
เราสามารถใช้ sep ได้แบบนี้:
# Load the dataset with ";" as delim
df2 = pd.read_csv("matches_semicolon.csv", sep=";")
# View the result
print(df2)
ผลลัพธ์:
MatchID HomeTeam AwayTeam HomeGoals AwayGoals MatchDate
0 M001 Manchester United Chelsea 2 1 2024-08-14
1 M002 Liverpool Arsenal 1 1 2024-08-20
2 M003 Tottenham Everton 3 0 2024-09-02
3 M004 Man City Aston Villa 4 2 2024-09-15
4 M005 Newcastle West Ham 0 0 2024-09-22
5 M006 Brighton Leeds 2 3 2024-09-29
header ใช้กำหนด row ที่จะเป็นหัวตาราง
เราจะใช้ header เมื่อ rows แรกของข้อมูลมีข้อมูลอื่น เช่น metadata (matches_with_metadata.txt):
# UK Football Matches Data
# Created for practice with pd.read_csv()
MatchID,HomeTeam,AwayTeam,HomeGoals,AwayGoals,MatchDate
M001,Manchester United,Chelsea,2,1,2024-08-14
M002,Liverpool,Arsenal,1,1,2024-08-20
M003,Tottenham,Everton,3,0,2024-09-02
M004,Man City,Aston Villa,4,2,2024-09-15
M005,Newcastle,West Ham,0,0,2024-09-22
M006,Brighton,Leeds,2,3,2024-09-29
เราสามารถใช้ header ได้แบบนี้:
# Load the dataset where the header is the 3rd row
df3 = pd.read_csv("matches_with_metadata.txt", header=2)
# View the result
print(df3)
ผลลัพธ์:
MatchID HomeTeam AwayTeam HomeGoals AwayGoals MatchDate
0 M001 Manchester United Chelsea 2 1 2024-08-14
1 M002 Liverpool Arsenal 1 1 2024-08-20
2 M003 Tottenham Everton 3 0 2024-09-02
3 M004 Man City Aston Villa 4 2 2024-09-15
4 M005 Newcastle West Ham 0 0 2024-09-22
5 M006 Brighton Leeds 2 3 2024-09-29
จะสังเกตว่า metadata จะไม่ถูกโหลดเข้ามาด้วย
Note: เราสามารถกำหนด header=None ในกรณีที่ข้อมูลไม่มีหัวตาราง เช่น matches_no_header.csv:
M001,Manchester United,Chelsea,2,1,2024-08-14
M002,Liverpool,Arsenal,1,1,2024-08-20
M003,Tottenham,Everton,3,0,2024-09-02
M004,Man City,Aston Villa,4,2,2024-09-15
M005,Newcastle,West Ham,0,0,2024-09-22
M006,Brighton,Leeds,2,3,2024-09-29
🛑 Argument #4. skiprows
skiprows ใช้เลือก rows ที่เราไม่ต้องการโหลดเข้ามาใน Python ซึ่งเราสามารถกำหนดได้ 2 แบบ:
- กำหนดเป็น
int (เช่น 2) ในกรณีที่ต้องการข้าม row เดียว
- กำหนดเป็น
list (เช่น [0, 1, 2]) ในกรณีที่ต้องการข้ามมากกว่า 1 rows
ยกตัวอย่างเช่น เราต้องการข้าม 2 บรรทัดแรกซึ่งเป็น metadata:
# UK Football Matches Data
# Created for practice with pd.read_csv()
MatchID,HomeTeam,AwayTeam,HomeGoals,AwayGoals,MatchDate
M001,Manchester United,Chelsea,2,1,2024-08-14
M002,Liverpool,Arsenal,1,1,2024-08-20
M003,Tottenham,Everton,3,0,2024-09-02
M004,Man City,Aston Villa,4,2,2024-09-15
M005,Newcastle,West Ham,0,0,2024-09-22
M006,Brighton,Leeds,2,3,2024-09-29
เราสามารถใช้ skiprows ได้แบบนี้:
# Load the dataset, skipping the metadata
df4 = pd.read_csv("matches_with_metadata.txt", skiprows=[0, 1])
# View the result
print(df4)
ผลลัพธ์:
MatchID HomeTeam AwayTeam HomeGoals AwayGoals MatchDate
0 M001 Manchester United Chelsea 2 1 2024-08-14
1 M002 Liverpool Arsenal 1 1 2024-08-20
2 M003 Tottenham Everton 3 0 2024-09-02
3 M004 Man City Aston Villa 4 2 2024-09-15
4 M005 Newcastle West Ham 0 0 2024-09-22
5 M006 Brighton Leeds 2 3 2024-09-29
📋 Argument #5. nrows
nrows ใช้เลือก rows ที่เราต้องการโหลดเข้ามาใน Python
เช่น แทนที่จะโหลดข้อมูลทั้งหมด:
MatchID,HomeTeam,AwayTeam,HomeGoals,AwayGoals,MatchDate
M001,Manchester United,Chelsea,2,1,2024-08-14
M002,Liverpool,Arsenal,1,1,2024-08-20
M003,Tottenham,Everton,3,0,2024-09-02
M004,Man City,Aston Villa,4,2,2024-09-15
M005,Newcastle,West Ham,0,0,2024-09-22
M006,Brighton,Leeds,2,3,2024-09-29
เราจะโหลดข้อมูล 3 rows แรกด้วย nrows แบบนี้:
# Load the first 3 rows
df5 = pd.read_csv("matches_clean.csv", nrows=3)
# View the result
print(df5)
ผลลัพธ์:
MatchID HomeTeam AwayTeam HomeGoals AwayGoals MatchDate
0 M001 Manchester United Chelsea 2 1 2024-08-14
1 M002 Liverpool Arsenal 1 1 2024-08-20
2 M003 Tottenham Everton 3 0 2024-09-02
☑️ Argument #6. usecols
usecols ใช้กำหนด columns ที่เราต้องการโหลดเข้ามาใน Python
ยกตัวอย่างเช่น เลือกเฉพาะ HomeTeam และ HomeGoals จาก:
MatchID,HomeTeam,AwayTeam,HomeGoals,AwayGoals,MatchDate
M001,Manchester United,Chelsea,2,1,2024-08-14
M002,Liverpool,Arsenal,1,1,2024-08-20
M003,Tottenham,Everton,3,0,2024-09-02
M004,Man City,Aston Villa,4,2,2024-09-15
M005,Newcastle,West Ham,0,0,2024-09-22
M006,Brighton,Leeds,2,3,2024-09-29
เราสามารถใช้ usecols ได้แบบนี้:
# Load only HomeTeam and HomeGoals
df6 = pd.read_csv("matches_clean.csv", usecols=["HomeTeam", "HomeGoals"])
# View the result
print(df6)
ผลลัพธ์:
HomeTeam HomeGoals
0 Manchester United 2
1 Liverpool 1
2 Tottenham 3
3 Man City 4
4 Newcastle 0
5 Brighton 2
🔢 Argument #7. index_col
index_col ใช้กำหนด column ที่เป็น index ของข้อมูล เช่น MatchID:
MatchID,HomeTeam,AwayTeam,HomeGoals,AwayGoals,MatchDate
M001,Manchester United,Chelsea,2,1,2024-08-14
M002,Liverpool,Arsenal,1,1,2024-08-20
M003,Tottenham,Everton,3,0,2024-09-02
M004,Man City,Aston Villa,4,2,2024-09-15
M005,Newcastle,West Ham,0,0,2024-09-22
M006,Brighton,Leeds,2,3,2024-09-29
เราจะใช้ index_col แบบนี้:
# Load the dataset with MatchID as index col
df7 = pd.read_csv("matches_clean.csv", index_col="MatchID")
# View the result
print(df7)
ผลลัพธ์:
HomeTeam AwayTeam HomeGoals AwayGoals MatchDate
MatchID
M001 Manchester United Chelsea 2 1 2024-08-14
M002 Liverpool Arsenal 1 1 2024-08-20
M003 Tottenham Everton 3 0 2024-09-02
M004 Man City Aston Villa 4 2 2024-09-15
M005 Newcastle West Ham 0 0 2024-09-22
M006 Brighton Leeds 2 3 2024-09-29
🔠 Argument #8. names
names ใช้กำหนดชื่อ columns ซึ่งเราจะใช้เมื่อ:
- ข้อมูลไม่มีหัวตาราง
- ต้องการเปลี่ยนชื่อ columns
ยกตัวอย่างเช่น ใส่ชื่อ columns ให้กับ matches_no_header.csv:
M001,Manchester United,Chelsea,2,1,2024-08-14
M002,Liverpool,Arsenal,1,1,2024-08-20
M003,Tottenham,Everton,3,0,2024-09-02
M004,Man City,Aston Villa,4,2,2024-09-15
M005,Newcastle,West Ham,0,0,2024-09-22
M006,Brighton,Leeds,2,3,2024-09-29
เราสามารถใช้ names ได้แบบนี้:
# Set col names
col_names = [
"id",
"home",
"away",
"home_goals",
"away_goals",
"date"
]
# Load the dataset with custom col names
df8 = pd.read_csv("matches_no_header.csv", names=col_names)
# View the result
print(df8)
ผลลัพธ์:
id home away home_goals away_goals date
0 M001 Manchester United Chelsea 2 1 2024-08-14
1 M002 Liverpool Arsenal 1 1 2024-08-20
2 M003 Tottenham Everton 3 0 2024-09-02
3 M004 Man City Aston Villa 4 2 2024-09-15
4 M005 Newcastle West Ham 0 0 2024-09-22
5 M006 Brighton Leeds 2 3 2024-09-29
⏹️ Argument #9. dtype
dtype ใช้กำหนดประเภทข้อมูลของ columns
ยกตัวอย่างเช่น กำหนด ประเภทข้อมูลของ MatchID, HomeGoals, และ AwayGoals จาก matches_clean.csv:
MatchID,HomeTeam,AwayTeam,HomeGoals,AwayGoals,MatchDate
M001,Manchester United,Chelsea,2,1,2024-08-14
M002,Liverpool,Arsenal,1,1,2024-08-20
M003,Tottenham,Everton,3,0,2024-09-02
M004,Man City,Aston Villa,4,2,2024-09-15
M005,Newcastle,West Ham,0,0,2024-09-22
M006,Brighton,Leeds,2,3,2024-09-29
เราสามารถใช้ dtype ได้แบบนี้:
# Set col data types
col_dtypes = {
"MatchID": str,
"HomeGoals": "int32",
"AwayGoals": "int32"
}
# Load the dataset, specifying data types for MatchID, HomeGoals, and AwayGoals
df9 = pd.read_csv("matches_clean.csv", dtype=col_dtypes)
# View the result
df9.info()
ผลลัพธ์:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 MatchID 6 non-null object
1 HomeTeam 6 non-null object
2 AwayTeam 6 non-null object
3 HomeGoals 6 non-null int32
4 AwayGoals 6 non-null int32
5 MatchDate 6 non-null object
dtypes: int32(2), object(4)
memory usage: 372.0+ bytes
⚡ Summary
ในบทความนี้ เราได้ไปดูวิธีการใช้ 9 arguments ของ read_csv() จาก pandas เพื่อโหลดข้อมูลใน Python กัน:
filepath_or_buffer: ไฟล์ที่ต้องการโหลดsep: delimiter ในไฟล์header: row ที่เป็นหัวตารางskiprows: rows ที่ไม่ต้องการโหลดnrows: จำนวน rows ที่ต้องการโหลดusecols: columns ที่ต้องการโหลดindex_col: column ที่จะเป็น indexnames: ชื่อของ columnsdtype: ประเภทข้อมูล (data types) ของ columns
😺 GitHub
ดูตัวอย่าง code และ datasets ในบทความนี้ได้ที่ GitHub
📃 References