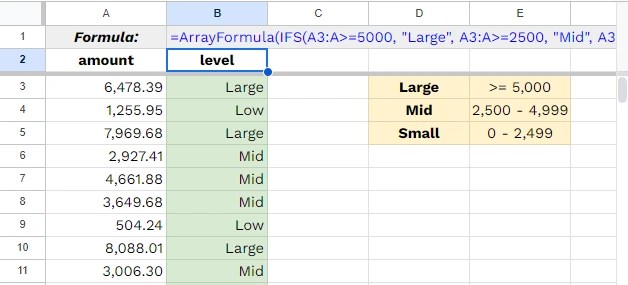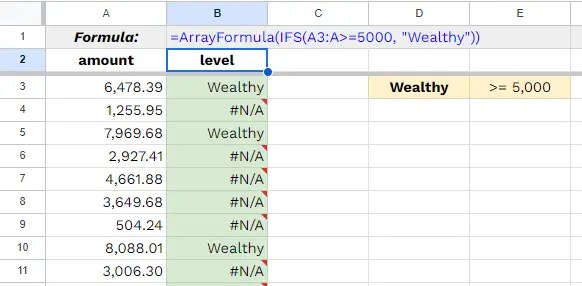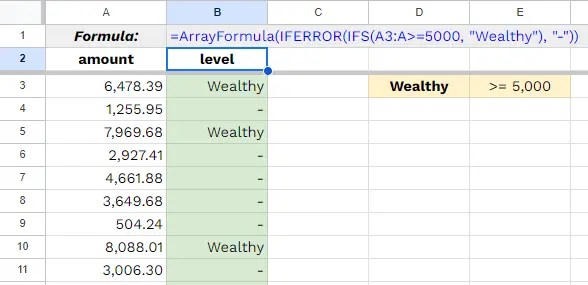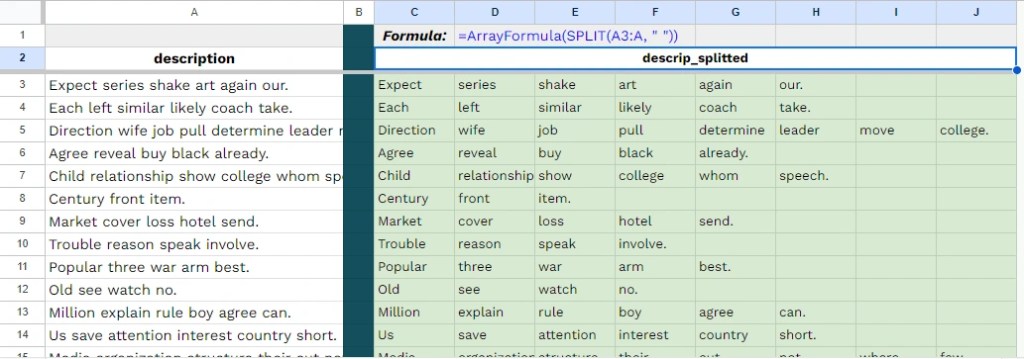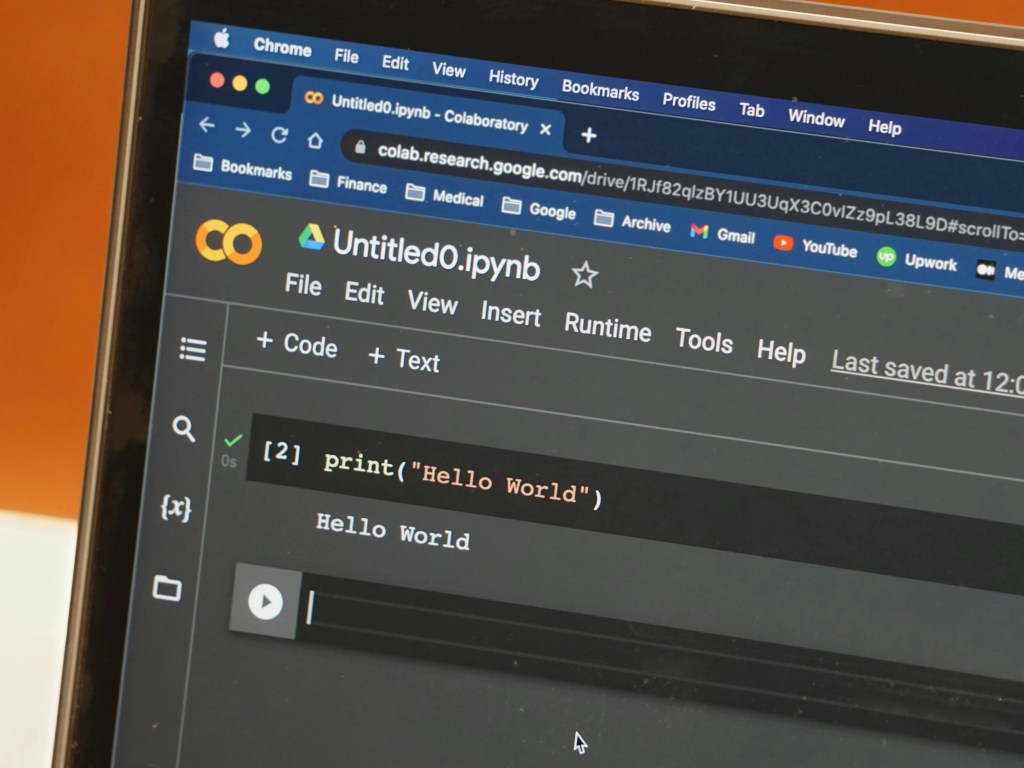
ในบทความนี้ เราจะไปทำความรู้จักกับภาษา Python กัน:
- Python คืออะไร?
- วิธีเขียน Python เบื้องต้น
- Data types ใน Python
- การทำงานกับ data types ใน Python
ถ้าพร้อมแล้ว ไปเริ่มกันเลย
- 🐍 Python คืออะไร?
- 🏁 Getting Started With Python
- 👶 Baby Steps
- 🍞 Data Types
- 👉 Integre & Float
- 👉 String
- 👉 Boolean
- 👉 List
- 👉 Dictionary
🐍 Python คืออะไร?
Python เป็น high-level programming language ที่พัฒนาโดย programmer ชาวดัชต์ Guido van Rossum ในช่วง ปี ค.ศ. 1980-1990 เพื่อทำให้การเขียน programme เป็นเรื่องง่าย
van Rossum เรียกภาษาที่คิดขึ้นมาว่า Python ตามชื่อกลุ่มนักแสดงตลกจากประเทศอังกฤษ Monty Python หรือ The Pythons เพราะคำว่า Python สั้น จำง่าย และดูลึกลับ (ไม่มีความเกี่ยวข้องกับชนิดงู Python แต่อย่างใด)
.
เนื่องจาก Python เป็น high-level language หรือมีความใกล้เคียงกับภาษามนุษย์ (มากกว่าภาษาคอมพิวเตอร์) จึงเป็นภาษาที่ใช้งานและทำความเข้าใจง่าย และเป็นที่นิยมของนักพัฒนาทั่วโลก
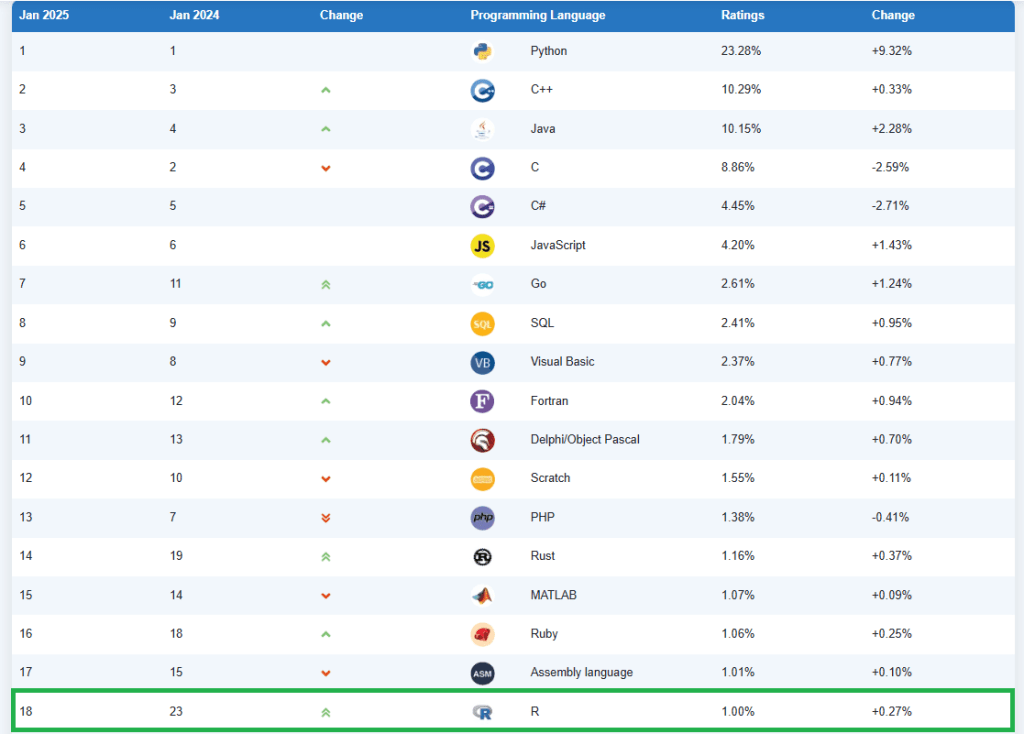
ในปัจจุบัน (2025) Python ครองอันดับในฐานะ programming language ที่เป็นที่นิยมมากที่สุด (อ้างอิง TIOBE):

นอกจากใช้งานง่ายแล้ว Python ยังมีข้อดีอื่น ๆ อีก ได้แก่:
- เป็น open source
- มี libraries รองรับการใช้งานที่มากมายและหลากหลาย
- แก้ bug ได้ง่าย
- ใช้ได้กับหลายระบบปฏิบัติการ ทั้ง Windows, macOS, และ Linux
.
การใช้งาน Python มีตั้งแต่:
- เขียน programme
- เขียน web application
- ทำ web scraping
- ทำ data analysis
- พัฒนา AI และ machine learning
🏁 Getting Started With Python
สำหรับการเริ่มใช้งาน Python เราสามารถติดตั้ง Python บนคอมพิวเตอร์ของเรา โดยดาวน์โหลด Python จาก https://www.python.org/downloads/:
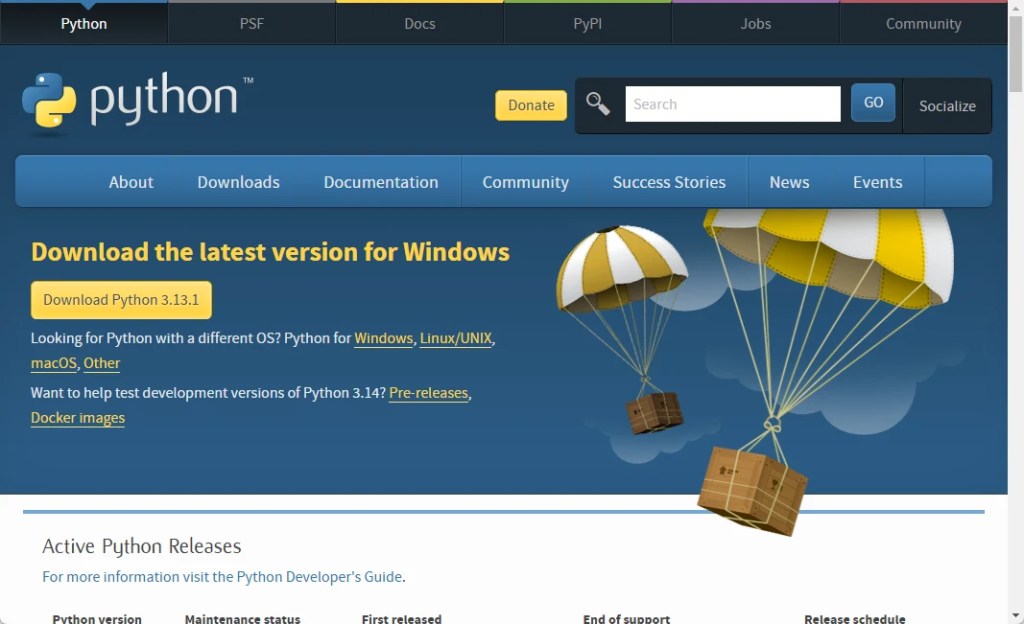
หรือใช้งานผ่าน online services ฟรี เช่น:
Note: บทความนี้มีตัวอย่าง code ใน Google Colab สามารถกดเข้าไปดูได้
👶 Baby Steps
หลังจากเตรียมตัวให้พร้อมแล้ว เรามาดูวิธีเขียน Python เบื้องต้นกัน
.
🔢 (1) Basic Arithmetic
สำหรับก้าวแรกในการเขียน Python เรามาเริ่มจากการคิดเลขง่าย ๆ กัน เช่น:
บวก:
# Addition
3 + 4
ลบ:
# Subtraction
10 - 7
คูณ:
# Multiplication
2 * 2
หาร:
# Division
9 / 3
เราจะเห็นได้ว่า Python สามารถคิดเลขให้ได้อย่างรวดเร็ว:

.
📦 (2) Variables
ในการทำงานกับ Python เราสามารถสร้าง variable เพื่อช่วยเก็บข้อมูลได้ (แทนที่การเขียน code เรียกใช้ข้อมูลเองทุกครั้ง)
เช่น เราสามารถเก็บเงินค่าขนม:
# Create allowance variable
allowance = 100
และค่าใช้จ่าย:
# Create expense variable
expense = 40
แล้วเรียกใช้งานทั้งสองค่า เช่น ดูว่าเดือนนี้เราเหลือเงินเท่าไร:
# Calculate remaining balance
allowance - expense
ผลลัพธ์:
60.
เราสามารถ update ค่าใน variable ได้ เช่น update expense จาก 40 เป็น 70:
# Update expense
expense = 70
ถ้าเราคำนวณเงินคงเหลือ:
# Calculate remaining balance
allowance - expense
เราจะได้ค่าที่ต่างไปจากเดิม:
30.
สุดท้าย เราสามารถเก็บผลลัพธ์ที่ได้ ไว้ใน variable ตัวใหม่ เพื่อเรียกใช้งานในภายหลังได้:
# Store remaining balance in a variable
remain = allowance - expense
# Check remaining balance
remain
ผลลัพธ์:
30Note: เราสามารถลบ variable ได้ด้วย del() เช่น del(remain) จะลบ remain จาก Python
🍞 Data Types
ตอนนี้ เรารู้วิธีการทำงานกับ Python เบื้องต้นแล้ว
เรามาทำความรู้จักกับ data type หรือประเภทข้อมูล ซึ่งเป็นตัวกำหนด action ที่เราสามารถกระทำใช้กับข้อมูลได้
.
โดย Python มี 6 data types ที่เราใช้บ่อย ได้แก่:
| No. | Type | Meaning | Example |
|---|---|---|---|
| 1 | Integre | เลขจำนวนเต็ม | 11 |
| 2 | Float | เลขทศนิยม | 3.78104 |
| 3 | String | ข้อความ | "Python" |
| 4 | Boolean | จริง/ไม่จริง | True |
| 5 | List | เก็บข้อมูลได้หลายประเภท | [”John”, 34, True] |
| 6 | Dictionary | เก็บ key-value pair | {"name": "John", "age": 34, "is_male": True} |
เราไปดูกันว่า แต่ละ data type สามารถทำอะไรได้บ้าง
👉 Integre & Float
.
1️⃣ Arithmetic
จากที่ได้เห็นก่อนหน้านี้ เราสามารถใช้ integre และ float ในการคำนวณเลขได้ เช่น:
3 * 7
และ
7.3915 - 3.2914
.
2️⃣ Type Casting
ทั้งนี้ เราสามารถเปลี่ยนข้อมูลบางประเภท ให้เป็น integre และ float ได้ดังนี้
เปลี่ยนให้เป็น integre:
# Convert to integre
int(100.50)
ผลลัพธ์:
100เปลี่ยนให้เป็น float:
# Convert to float
float("100")
ผลลัพธ์:
100.0👉 String
.
1️⃣ Markers of String
String ใน Python จะอยู่ใน "" หรือ '' เสมอ เช่น
# Single-line string
"John"
หรือ
# Single-line string
'John'
ถ้าเรามีข้อความหลายบรรทัด ให้ใช้ """ หรือ ''':
# Multiple-line string
"""
My name is Wick.
John Wick.
I'm looking for my dog.
"""
หรือ
# Multiple-line string
'''
My name is Wick.
John Wick.
I'm looking for my dog.
'''
.
2️⃣ Type Casting
เราสามารถเปลี่ยนข้อมูลต่าง ๆ ให้เป็น string ได้โดยใช้ str() เช่น:
str(100)
ผลลัพธ์:
'100'สังเกตว่า ตอนนี้ 100 อยู่ใน '' แสดงว่า 100 เป็น string และไม่ใช่ integre แล้ว
ถ้าเราเอา 100 นี้ไปคิดเลข ระบบจะส่ง error กลับมา เพราะเราไม่สามารถคำนวณเลขด้วย string ได้:
TypeError Traceback (most recent call last)
<ipython-input-49-efc4e6e83db0> in <cell line: 0>()
1 # String cannot be used in arithmetic operation
----> 2 str(100) + 100
TypeError: can only concatenate str (not "int") to str.
3️⃣ Concatenate
แม้ว่าเราจะไม่สามารถบวกลบ string ได้ แต่เราสามารถใช้ + เพื่อรวม string เข้าด้วยกันได้ เช่น:
"I have " + str(100) + " THB."
ผลลัพธ์:
'I have 100 THB.'.
4️⃣ String Methods
นอกจากการรวม string แล้ว เรายังมีอย่างอื่นที่ใช้กับ string ได้อีก เช่น:
| No. | Method | Explain |
|---|---|---|
| 1 | upper() | เปลี่ยนให้เป็นพิมพ์ใหญ่ทั้งหมด |
| 2 | lower() | เปลี่ยนให้เป็นพิมพ์เล็กทั้งหมด |
| 3 | capitalize() | เปลี่ยนอักษรแรกให้เป็นพิมพ์ใหญ่ |
| 4 | title() | เปลี่ยนอักษรแรกของทุกคำให้เป็นพิมพ์ใหญ่ |
| 5 | strip() | ลบ space ออกจากก่อนและหลังคำ |
| 6 | replace() | แทนที่คำ |
| 7 | split() | แยกคำ |
| 8 | join(iterable) | รวมคำ |
| 9 | find(substring) | หาตำแหน่งของคำ |
| 10 | count() | นับตัวอักษรที่ต้องการ |
👉 Boolean
Boolean เป็นเหมือนกับค่า on (True) และ off (False) ของ switch ซึ่งเป็นพื้นฐานของการทำงานของคอมพิวเตอร์
.
1️⃣ Check for True & False
เราสามารถใช้ bool() เพื่อเช็กว่า ข้อมูลเราเป็น True หรือ False เช่น:
bool("John")
ผลลัพธ์:
True.
bool() จะส่ง True กลับมาทุกครั้ง ยกเว้นในกรณีเหล่านี้:
| Type | False | Explain |
|---|---|---|
| Integre | bool(0) | เลขเป็น 0 |
| String | bool("") | String ที่เป็นค่าว่าง |
| Boolean | bool(False) | Boolean ที่เป็นค่า False |
| List | bool([]) | List ที่เป็นค่าว่าง |
| Dictionary | bool({}) | Dictionary ที่เป็นค่าว่าง |
.
2️⃣ Comparison
Python จะส่งค่า boolean กลับมา เมื่อเราทำการเปรียบเทียบ เช่น:
10 > 5
ผลลัพธ์:
True.
หรือ
10 < 5
ผลลัพธ์:
False👉 List
.
1️⃣ Purpose
List ใช้เก็บข้อมูลหลาย ๆ ค่า เช่น:
- Integre
- Float
- String
- Boolean
- List
- Dictionary
- etc.
เช่น:
# List can store data of different types
a_list = [10, 15.94, "ok", True, ["egg", "milk"], {"store": "Walmart"}]
.
2️⃣ Indexing & Slicing
เราสามารถดึงข้อมูลที่อยู่ใน list ได้ โดยการใช้ []:
| Syntax | Explain |
|---|---|
| list[x] | ดึงข้อมูลในตำแหน่งที่ x |
| list[-x] | ดึงข้อมูลในตำแหน่งที่ -x (นับจากหลังมาหน้า) |
| list[x:y] | ดึงข้อมูลในตำแหน่งระหว่าง x และ y-1 (ข้อมูลที่ y จะไม่ถูกดึงมาด้วย) |
| list[-x:-y] | ดึงข้อมูลในตำแหน่งระหว่าง -x และ -y-1 (ข้อมูลที่ -y จะไม่ถูกดึงมาด้วย) |
.
เช่น เรามี list ผลไม้:
# A list
my_list = ["apple", "banana", "cherry"]
เราสามารถดึง “apple” ออกได้โดยใช้:
# Get "apple"
my_list[0]
ผลลัพธ์:
'apple'Note: เราใช้ 0 เพราะใน Python เราจะเริ่มนับตำแหน่งที่ 1 เป็น 0
.
หรือเลือก “apple” ถึง “cherry”:
# Get "apple" to "cherry"
my_list[0:3]
ผลลัพธ์:
['apple', 'banana', 'cherry'].
3️⃣ Check Length
เราสามารถหาความยาวของ list ได้ด้วย len() เช่น:
# Check length
len(my_list)
ผลลัพธ์:
3.
4️⃣ Add to List
เราสามารถเพิ่มข้อมูลลงใน list ได้ด้วย 2 วิธี:
| No. | Way | Example |
|---|---|---|
| 1 | .append() | เพิ่มข้อมูล 1 ค่า |
| 2 | .extend() | เพิ่มข้อมูลจาก list หรือ string |
.
ตัวอย่าง .append():
# append()
my_list.append("orange")
my_list
ผลลัพธ์:
['apple', 'banana', 'cherry', 'orange'].
ตัวอย่าง .extend():
เรามี 2 lists ที่ต้องการรวมกัน:
# Lists to merge
list_1 = [1, 2, 3]
list_2 = [4, 5, 6]
ให้เราใช้ .extend() แบบนี้:
# extend()
list_1.extend(list_2)
ผลลัพธ์:
[1, 2, 3, 4, 5, 6].
5️⃣ Update List
เราสามารถ update ข้อมูลใน list ได้ โดยการระบุตำแหน่งข้อมูลที่เราต้องการ update
เช่น เราต้องการเปลี่ยน “orange” เป็น “kiwi”:
# Update list
my_list[3] = "kiwi"
my_list
เมื่อเราเรียกดู my_list เราจะเห็นว่า “orange” เปลี่ยนเป็น “kiwi”:
['apple', 'banana', 'cherry', 'kiwi'].
6️⃣ Delete From List
เราสามารถลบข้อมูลออกจาก list ได้ด้วย .remove()
เช่น ลบ “kiwi” ออกจาก my_list:
# Delete from list
my_list.remove("kiwi")
my_list
ผลลัพธ์:
['apple', 'banana', 'cherry']👉 Dictionary
.
1️⃣ Purpose
Dictionary มีไว้เก็บ key-value pair เช่น:
# A dictionary
cities = {"Thailand": "Bangkok",
"Japan": "Tokyo",
"Brazil": "Brasilia"}
.
2️⃣ Extract Values
เราสามารถดึงข้อมูลออกจาก dictionary ได้ด้วยการระบุ key ของข้อมูล
เช่น ต้องการดึง “Tokyo” ให้เราระบุ “Japan”:
# Extract values from list
cities["Japan"]
ผลลัพธ์:
'Tokyo'.
3️⃣ Get Keys & Values
เราสามารถดู keys และ values ทั้งหมดใน dictionary ได้ด้วย .keys() และ .values() เช่น:
# Get keys
cities.keys()
ผลลัพธ์:
dict_keys(['Thailand', 'Japan', 'Brazil']).
และ
# Get values
cities.values()
ผลลัพธ์:
dict_values(['Bangkok', 'Tokyo', 'Brasilia']).
4️⃣ Add to Dictionary
เราสามารถเพิ่มข้อมูลลงใน dictionary ได้ โดยการใส่ key และ value ใหม่ เช่น:
# Add to dictionary
cities["US"] = "New York"
cities
ผลลัพธ์:
{'Thailand': 'Bangkok',
'Japan': 'Tokyo',
'Brazil': 'Brasilia',
'US': 'New York'}.
5️⃣ Update Dictionary
เราสามารถ update ข้อมูลใน dictionary ได้ด้วยเรียก key และใส่ value ใหม่ เช่น:
# Update dictionary
cities["US"] = "Washington DC"
cities
ผลลัพธ์:
{'Thailand': 'Bangkok',
'Japan': 'Tokyo',
'Brazil': 'Brasilia',
'US': 'Washington DC'}.
6️⃣ Delete From Dictionary
เราสามารถลบข้อมูลออกจาก dictionary ได้ด้วย del
เช่น ลบ “US”: “Washington DC” ออก:
# Delete from dictionary
del cities["US"]
cities
ผลลัพธ์:
{'Thailand': 'Bangkok', 'Japan': 'Tokyo', 'Brazil': 'Brasilia'}