
Statistics เป็น 1 ใน 3 ทักษะที่สำคัญในการทำงานกับ data
(อีก 2 ทักษะ คือ programming และ domain expertise)
โดย statistics ช่วยให้เรา …
- ค้นพบรูปแบบและความสัมพันธ์ในข้อมูล
- วิเคราะห์และรับมือกับความไม่แน่นอน (uncertainty)
- Get insights จาก data
- ช่วยตัดสินใจเกี่ยวกับอนาคต
- แก้ปัญหาที่ซับซ้อน
ในบทความนี้ เราจะมาดู 10 statistical concepts ที่คนทำงานสาย data ควรรู้กัน โดยสรุปเนื้อหาจาก 3 คอร์ส data analytics:
- Google’s The Power of Statistics
- DataCamp’s Introduction to Statistics
- DataRockie’s Data Science Bootcamp 10
ถ้าพร้อมแล้ว มาเริ่มกันเลย
- 1️⃣ What Is Statistics?
- 2️⃣ Central Tendency
- 3️⃣ Spread
- 4️⃣ Position
- 5️⃣ Probability
- 6️⃣ Sampling
- 7️⃣ Distributions & Central Limit Theorem (CLT)
- 8️⃣ Confidence Interval
- 9️⃣ Hypothesis Testing
- 🔟 Experimental Designs
- 📄 References
1️⃣ What Is Statistics?
👉 Statistics เป็นศาสตร์ของการเก็บรวบรวม (collect) และวิเคราะห์ (analyse) ข้อมูล
เมื่อเราต้องการศึกษา population หรือกลุ่มที่เราสนใจ (เช่น คนไทย) เราต้องเก็บข้อมูลและนำมาวิเคราะห์ เพื่อหาข้อสรุป
แต่เพราะเราไม่สามารถเก็บข้อมูลของ population ได้ทั้งหมด (เช่น เก็บข้อมูลจากคนไทยทั้งประเทศ) ทำให้เราต้องเลือกเก็บข้อมูลจาก sample หรือกลุ่มตัวอย่างที่เป็นตัวแทนของ population แทน
การที่เรามี population และ sample ทำให้เราแบ่ง statistics ได้เป็น 2 สาขา:
| No. | Type | Description |
|---|---|---|
| 1 | Descriptive statistics | สรุปลักษณะของชุดข้อมูล (sample และ popilation) |
| 2 | Inferential statistics | อนุมานลักษณะของ population จากลักษณะของ sample |
ตัวอย่างหัวข้อของ descriptive statistics:
- Central tendency
- Spread
- Position
ตัวอย่างหัวข้อของ inferential statistics:
- Confidence level
- Significance level
- Hypothesis testing
2️⃣ Central Tendency
👉 Central tendency คือ ค่ากลางของชุดข้อมูล และมี 3 ค่า ได้แก่:
| No. | Measure | Definition |
|---|---|---|
| 1 | Mean | ค่าเฉลี่ย (average) |
| 2 | Median | ข้อมูลที่อยู่กลางชุดข้อมูล (middle value) |
| 3 | Mode | ข้อมูลที่เกิดขึ้นบ่อยที่สุดในชุดข้อมูล (most frequent value) |
Note:
- Central tendency ที่เรานิยมใช้ คือ mean
- เราควรใช้ median ในกรณีที่ชุดข้อมูลมี outlier เพราะ mean มีความอ่อนไหวต่อ outlier
- Mean และ median มีได้ 1 ค่า แต่ mode มีได้มากกว่า 1 ค่า
อ่านเพิ่มเติมเกี่ยวกับ central tendency: บทความจาก Australian Bureau of Statistics
3️⃣ Spread
👉 Spread คือ การวัดความหลากหลายของข้อมูล และมี 4 ค่า ได้แก่:
| No. | Measure | Definition |
|---|---|---|
| 1 | Range | ค่าความต่างระหว่าง ค่าที่น้อยที่สุด (min) และค่าที่มากที่สุด (max) |
| 2 | Standard deviation (SD) | ค่าความห่างโดยเฉลี่ยระหว่างข้อมูลและ mean ของชุดข้อมูล |
| 3 | Variance | SD กำลังสอง |
| 4 | Interquartile range | ค่าความต่างระหว่าง quartile ที่ 1 (Q1) และ quartile ที่ 3 (Q3) |
อ่านเพิ่มเติมเกี่ยวกับ spread: บทความจาก Australian Bureau of Statistics
4️⃣ Position
👉 Position หมายถึง ตำแหน่งของข้อมูลในชุดข้อมูล และมี 2 ค่าหลัก ได้แก่:
| No. | Measure | Definition |
|---|---|---|
| 1 | Percentile | ระบุตำแหน่งจาก % ข้อมูลที่มีค่าน้อยกว่าข้อมูลนั้น (เช่น ข้อมูลที่ P70 หมายถึง มีข้อมูลที่อยู่ต่ำกว่าข้อมูลนี้ 70%) |
| 2 | Quartile | ระบุตำแหน่งโดยแบ่งข้อมูลเป็น 4 ส่วนเท่า ๆ กัน (quartile) |
5️⃣ Probability
👉 Probability (ความน่าจะเป็น) คือ การศึกษาความไม่แน่นอน (uncertainty) และแบ่งได้เป็น 2 ประเภทหลัก ตามลักษณะ event (เหตุการณ์) ที่เราสนใจ:
- Independent probability
- Conditional probability
.
ประเภทที่ 1. Independent probability
👉 Probability ของเหตุการณ์ที่ไม่ขึ้นอยู่กับเหตุการณ์อื่น (independent events) เช่น:
- การฟังเพลงรัก กับ พระอาทิตย์ขึ้น
- การดื่มกาแฟ กับ ฝนตก
- การใส่เสื้อสีฟ้า กับ ราคาหุ้นขึ้น
🧮 วิธีคำนวณ:
P(A) = Outcome A / Total outcomes
- P(A) คือ probability ของ event A
- Outcome A คือ จำนวนครั้งที่เกิด event A
- Total outcomes คือ จำนวนครั้งที่เกิด events ทั้งหมด
.
ประเภทที่ 2. Conditional probability
👉 Probability ของเหตุการณ์ที่ขึ้นอยู่กับเหตุการณ์อื่น (dependent events) เช่น:
- การสอบเข้ามหาวิทยาลัย กับ การเรียนจบ ป.ตรี (จะเรียนไม่จบ ถ้าไม่ได้สอบ)
- การซื้อหวย กับ การถูกหวย (จะถูกหวยไม่ได้ ถ้าไม่ได้ซื้อ)
- การออมเงิน และ การมีเงินหลังเกษียณ (อาจไม่มีเงินใช้ ถ้าไม่ออมเงิน)
🧮 วิธีคำนวณ:
P(A | B) = P(A ∩ B) / P(B)
- P(A | B) คือ probability ของ event A ถ้าเกิด event B
- P(A ∩ B) คือ probability ของ event A และ B
- P(B) คือ probability ของ event B
6️⃣ Sampling
👉 Sampling คือ การสร้าง sample จาก population และมี 2 ประเภท ได้แก่
- Non-probability sampling: การสร้าง sample ที่สมาชิกของ population มีโอกาสถูกเลือกไม่เท่ากัน
- Probability sampling: การสร้าง sample ที่สมาชิกของ population มีโอกาสถูกเลือกเท่า ๆ กัน
โดยแต่ละประเภทมีประเภทย่อยดังนี้:
.
🍀 Non-probability sampling มี 4 ประเภทย่อย:
| No. | Type | Meaning |
|---|---|---|
| 1 | Voluntary response | กลุ่มตัวอย่างสมัครใจเข้าร่วมเอง |
| 2 | Convenience sampling | กลุ่มตัวอย่างมาจากคนที่เข้าถึงได้ง่าย (เช่น เพื่อน คนในครอบครัว) |
| 3 | Purposive sampling | สร้างกลุ่มตัวอย่างตามเกณฑ์ที่กำหนด (เช่น เลือกคนอายุ 20 ปีเท่านั้น) |
| 4 | Snowball sampling | กลุ่มตัวอย่างที่ได้จากการให้ผู้เข้าร่วมชวนกันต่อเป็นลูกโซ่ |
.
🍀 Probability sampling มี 4 ประเภทย่อย:
| No. | Type | Meaning |
|---|---|---|
| 1 | Simple random sampling | สุ่มกลุ่มตัวอย่างจากประชากรโดยตรง |
| 2 | Stratified random sampling | แบ่งประชากรออกเป็นกลุ่ม ๆ แล้วสุ่มตัวอย่างจากแต่ละกลุ่มตามสัดส่วน |
| 3 | Cluster random sampling | แบ่งประชากรเป็นกลุ่ม ๆ แล้วเลือกสุ่มกลุ่มมาเป็นตัวอย่าง |
| 4 | Systematic random sampling | จัดลำดับสมาชิกแล้วสุ่มเลือกทุก ๆ nth คน เช่น คนที่ 5, 10, 15, … |
7️⃣ Distributions & Central Limit Theorem (CLT)
👉 Distribution คือ การกระจายตัวของข้อมูล
แม้ว่า distribution จะมีหลายประเภท แต่มี 2 ประเภท ที่เรามักพบบ่อย ได้แก่:
- Normal distribution
- Sampling distribution
.
ประเภทที่ 1. Normal distribution
👉 Normal distribution คือ การกระจายตัวแบบระฆังคว่ำ (bell shape) เพราะมีข้อมูลส่วนใหญ่กระจุกตัวอย่างตรงกลาง และกระจายตัวออกด้านข้าง
นอกจากทรงระฆังคว่ำที่เป็นจุดเด่น normal distribution ยังมีลักษณะอื่น ๆ อีก คือ:
- สมมาตร (symmetrical)
- พื้นที่ใต้กราฟ = 1
- หางทั้งสองข้างจะเข้าใกล้ 0 แต่ไม่แตะ 0
- เรารู้ว่า ในแต่ละส่วนของ normal distribution มีข้อมูลอยู่กี่เปอร์เซ็นต์:

| Zone | % |
|---|---|
| -/+1 SD | 68 |
| -/+2 SD | 95 |
| -/+3 SD | 99 |
Normal distribution เป็น distribution ที่มีความสำคัญ เพราะ:
- เป็น distribution ที่พบได้ทั่วไปในธรรมชาติ เช่น ส่วนสูง ความดันเลือด IQ
- เป็นพื้นฐานของการวิเคราะห์ทางสถิติอื่น ๆ เช่น hypothesis testing
.
ประเภทที่ 2. Sampling distribution
👉 Sampling distribution เป็น distribution ที่เกิดจากการเอา mean ของหลาย ๆ samples มาสร้างกราฟ
ยกตัวอย่างเช่น sampling distribution จาก 10 samples, 100 samples, และ 1,000 samples (แต่ละ sample มีขนาด 30 คน):
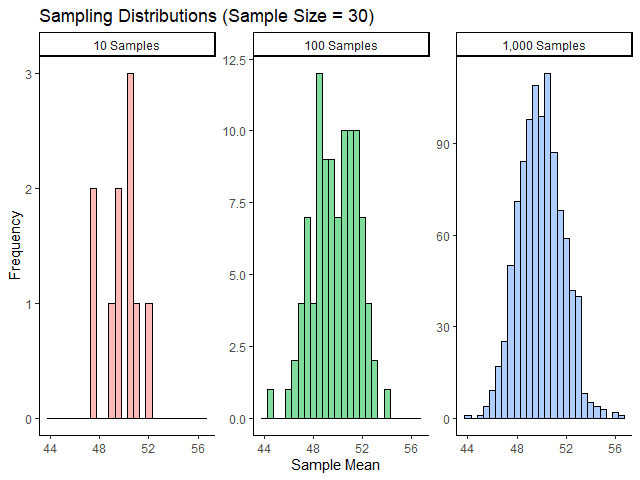
.
📊 Central limit theorem (CLT)
CLT ระบุว่า ยิ่งเรามี sample มากขึ้นเท่าไร sampling distribution ก็จะยิ่งเหมือน normal distribution เข้าไปเท่านั้น
เราสามารถสังเกตเห็นได้จากตัวอย่างกราฟด้านบน ในขณะที่เราเพิ่ม samples จาก 10 เป็น 100 เป็น 1,000 การกระจายตัวก็ดูเหมือน normal distribution เข้าไปเรื่อย ๆ
ทั้งนี้ CLT จะเป็นจริงได้ ถ้าเงื่อนไข 3 ข้อนี้เป็นจริง:
| No. | Assumption | Description |
|---|---|---|
| 1 | Randomisation | samples ได้มาจากการสุ่ม |
| 2 | Independence | การสุ่มแต่ละครั้งไม่ขึ้นกับการสุ่มครั้งก่อน |
| 3 | Sample size | กลุ่มตัวอย่างมีขนาดใหญ่พอ (อย่างน้อย 30 ตัวอย่าง ตาม rule of thumb) |
8️⃣ Confidence Interval
👉 Confidence interval คือ การประมาณการ (estimate) โดยใช้ช่วง (interval) แทนค่าเดี่ยว ๆ (point)
ยกตัวอย่างเช่น แทนที่เราจะเดาว่า คนคนหนึ่งมีอายุ 20 ปี (point) เราสามารถเดาเป็นช่วงได้ เช่น อายุ 18-22 ปี (interval)
ทั้งนี้ confidence interval ประกอบด้วย 3 ส่วน:
| No. | Component | Example |
|---|---|---|
| 1 | Sample statistic | เรารู้ว่า คนคนนี้อยู่ในกลุ่มคนที่มีค่าเฉลี่ยอายุ 20 ปี |
| 2 | Margin of error | เราเชื่อว่า อายุจริงของคนคนนี้จะต่างจากค่าเฉลี่ย -/+ 2 ปี |
| 3 | Confidence level | เราเชื่อว่า การเดาของเรามีโอกาสถูก 95% |
Note:
- 95% เป็น confidence level ที่นิยมใช้มากที่สุด
- ยิ่ง confidence level สูง, confidence interval ก็ยิ่งกว้าง เพราะต้องมีความครอบคลุมเพิ่ม
9️⃣ Hypothesis Testing
👉 Hypothesis testing คือ การทดสอบว่า สิ่งที่เราเชื่อเกี่ยวกับ population เป็นจริงไหม
ตัวอย่างเช่น:
- คนไทยมีความสูงเฉลี่ย 170 cm
- ผู้หญิงทำข้อสอบเลขได้ดีกว่าผู้ชาย
- กาแฟช่วยให้ทำงานได้ดีขึ้น
.
👉 4 ขั้นตอนในการทำ hypothesis testing:
- ตั้ง null hypothesis (H0) และ alternate hypothesis (H1)
- เลือก significance level
- หา p-value
- ตัดสินใจว่า จะ reject หรือ fail to reject H0
.
🤔 H0 vs H1
| Hypothesis | Description | Example |
|---|---|---|
| H0 | สมมุติฐานที่ถือว่าเป็นจริง จนกว่าจะมีหลักฐานมาหักล้าง | ความสูงเฉลี่ยของคนไทย เท่ากับ 170 cm |
| H1 | สมมุติฐานที่ถือว่าเป็นจริง ต่อเมื่อมีหลักฐานสนับสนุน | ความสูงเฉลี่ยของคนไทย ไม่เท่ากับ 170 cm |
ตัวอย่างเช่น:
| Example | H0 | H1 |
|---|---|---|
| คนไทยมีความสูงเฉลี่ย 170 cm | ความสูงเฉลี่ยของคนไทย เท่ากับ 170 cm | ความสูงเฉลี่ยของคนไทย ไม่เท่ากับ 170 cm |
| ผู้หญิงทำข้อสอบเลขได้ดีกว่าผู้ชาย | คะแนนสอบเลขของผู้หญิงและผู้ชายเท่ากัน | คะแนนสอบเลขของผู้หญิงและผู้ชายไม่เท่าเท่ากัน |
| กาแฟช่วยให้ทำงานได้ดีขึ้น | ดื่มกาแฟแล้ว จะทำงานได้แค่ 8 ชม. | ดื่มกาแฟแล้ว จะทำงานได้นานกว่า 8 ชม. |
.
🤔 Significance level vs p-value
| Term | Description |
|---|---|
| Significance level | ความเป็นไปได้ที่จะ reject H0 เมื่อ H0 เป็นจริง |
| P-value | ความเป็นไปได้ที่จะเห็นผลลัพธ์ที่แตกต่างจาก H0 เมื่อ H0 เป็นจริง |
.
🤔 Reject H0 vs fail to reject H0
เราจะ reject H0 (ยอมรับ H1) เมื่อ significance level และ p-value มีค่าดังนี้:
| Action | When |
|---|---|
| Reject H0 | p-value < significance level |
| Fail to reject H0 | p-value > significance level |
🔟 Experimental Designs
การเก็บข้อมูลทางสถิติทำได้ 3 แบบหลัก ๆ ได้แก่:
- Observational study
- A/B testing
- Randomised controlled trial (RCT)
.
👉 Observational study เป็นการเก็บข้อมูล ผ่านการสังเกตการณ์ เช่น:
- สังเกตพฤติกรรมการซื้อของในร้านค้า
- สังเกตพฤติกรรมการเล่นของเด็ก
- สังเกตพฤติกรรมการหาคู่ของนก
ใน observational study เราไม่ได้เปลี่ยนแปลงตัวแปรต้น (independent variable) ทำให้:
- เราสามารถบอกได้ว่า อะไรเกิดขึ้นกับอะไร (correlation)
- แต่ไม่สามารถบอกได้ว่า อะไรทำให้เกิดอะไร (causation) เท่านั้น
.
👉 A/B testing เป็นการทดสอบที่นิยมใช้ใน business เพื่อทดสอบผลิตภัณฑ์/บริการ
ใน A/B testing เรามีของ 2 versions (A vs B) และกลุ่มตัวอย่างจะถูกสุ่มให้เห็น version ที่ไม่เหมือนกัน
เช่น เรามีเว็บไซต์แบบเก่า (A) และแบบใหม่ (B) และเราอยากรู้ว่า แบบไหนกระตุ้นยอดขายดีที่สุด
เราเปิดใช้งานเว็บไซต์ 2 versions โดยลูกค้าแต่ละคนจะเห็นเว็บไซต์ไม่เหมือนกัน (บางคนเห็นแบบเก่า และบางคนเห็นแบบใหม่)
หลังจากเวลาผ่านไปสักพัก เราเอาข้อมูลการขายมาดูว่า ลูกค้าที่เห็นเว็บไซต์แบบไหนที่มียอดซื้อมากที่สุด
ดูตัวอย่าง A/B testing ในโลกจริง: 10 real-world examples of A/B testing that made an impact
.
👉 RCT เป็น “gold standard” ของ experimental design เพราะ:
- มีการควบคุมตัวแปรต้น ทำให้เราอนุมานถึง cause และ effect ได้
- ลดความลำเอียง (bias) และอิทธิพลของตัวแปรที่สาม (confounding variables)
RCT มีลักษณะเด่น 2 อย่าง:
| No. | Characteristic | Description |
|---|---|---|
| 1 | Randomisation | กลุ่มตัวอย่างถูกสุ่มเข้าเงื่อนไข |
| 2 | Control group | มีกลุ่มที่เป็น baseline เพื่อเปรียบเทียบกับกลุ่มที่ได้รับเงื่อนไขบางอย่าง |
ตัวอย่างการทำ RCT เช่น การทดสอบผลของยาลดความดัน:
- เราใช้การสุ่มผู้เข้าร่วมให้เป็น 2 กลุ่ม
- กลุ่มแรกให้รับยาปลอมที่ไม่ส่งผลต่อร่างกาย (control group)
- กลุ่มที่สองได้รับยาจริงที่เราต้องการทดสอบผล (treatment)
- หลังรับยา เราวัดความดันของทั้งสองกลุ่ม
📄 References
- The Power of Statistics
- Introduction to Statistics
- Z-Score: Definition, Formula, Calculation & Interpretation
- รู้จัก Central Limit Theorem ขุมพลังแห่งโลกสถิติ
- Central Limit Theorem: A Beginner’s Guide
- ทดสอบสมมติฐานทางสถิติด้วย Confidence Interval ไม่ง้อ p-value
- สถิติที่ใช้ในงานวิจัย
- Measures of central tendency
- Measures of spread
- Statistics – Quartiles and Percentiles

Leave a comment