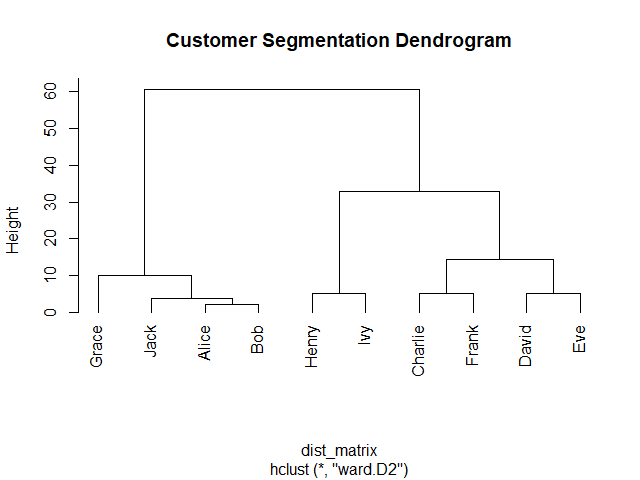
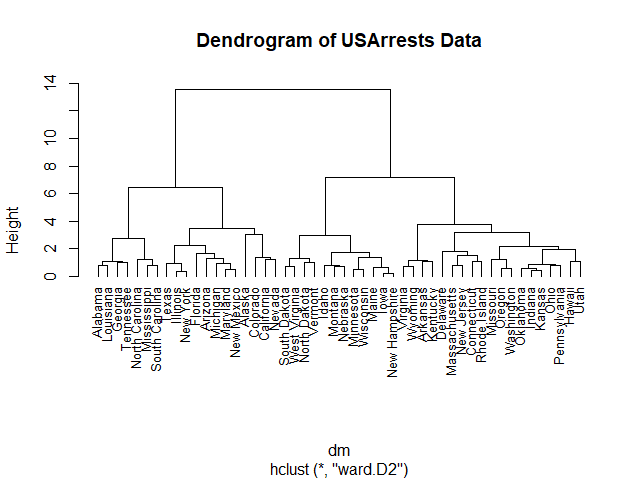
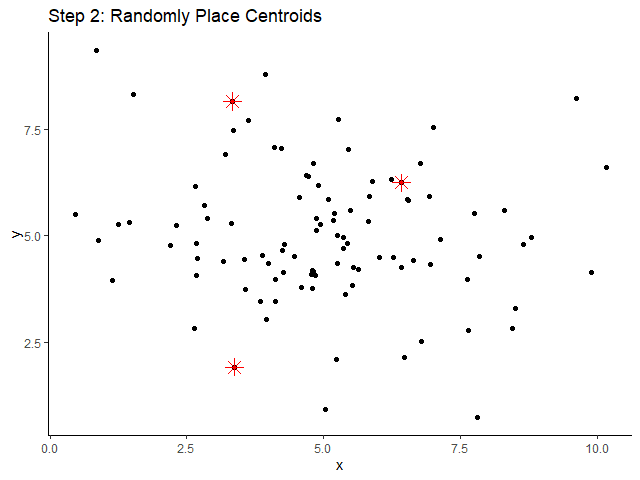
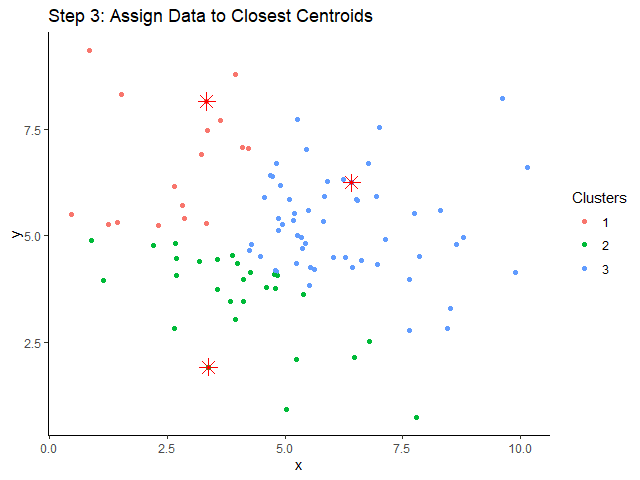
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
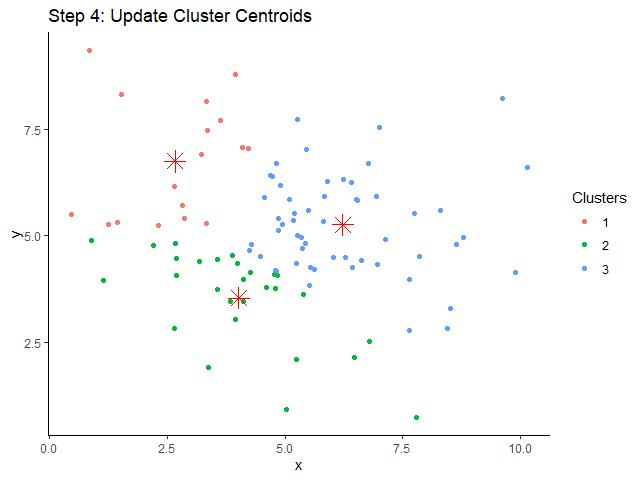
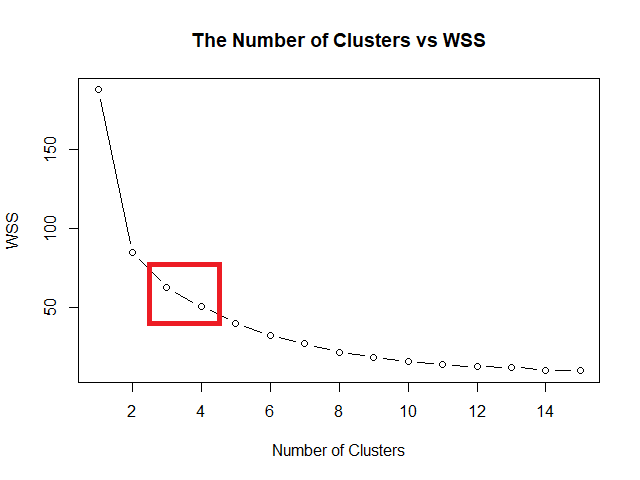
Elbow method หาค่า k ที่ดีที่สุด โดยสร้างกราฟระหว่างค่า k และ within-cluster sum of squares (WSS) หรือระยะห่างระหว่างข้อมูลในกลุ่ม ค่า k ที่ดีที่สุด คือ ค่า k ที่ WSS เริ่มไม่ลดลง
ในภาษา R เราสามารถเริ่มสร้างกราฟได้ โดยเริ่มจากใช้ for loop หา WSS สำหรับช่วงค่า k ที่เราต้องการ
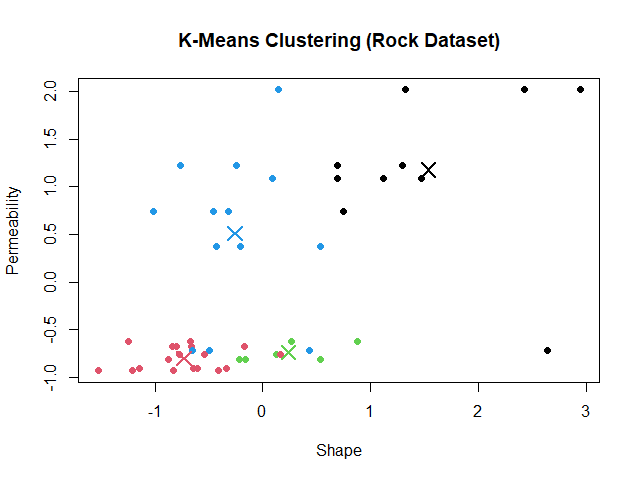
ในตัวอย่าง rock dataset เราจะใช้ช่วงค่า k ระหว่าง 1 ถึง 15:
# Initialise a vector for within cluster sum of squares (wss)
wss <- numeric(15)
# For-loop through the wss
for (k in 1:15) {
## Try the k
km <- kmeans(rock_scaled,
centers = k,
nstart = 20)
## Get WSS for the k
wss[k] <- km$tot.withinss
}
จากนั้น ใช้ plot() สร้างกราฟความสัมพันธ์ระหว่างค่า k และ WSS:
# Plot the wss
plot(1:15,
wss,
type = "b",
main = "The Number of Clusters vs WSS",
xlab = "Number of Clusters",
ylab = "WSS")
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ