ก่อนนำ mtcars ไปใช้สร้าง classification tree เราจะต้องทำ 2 อย่างก่อน:
อย่างที่ #1. ปรับ column am ให้เป็น factor เพราะสิ่งที่เราต้องการทำนายเป็น categorical data:
# Convert `am` to factor
mtcars$am <- factor(mtcars$am,
levels = c(0, 1),
labels = c("automatic", "manual"))
# Check the result
class(mtcars$am)
ผลลัพธ์:
[1] "factor"
อย่างที่ #2. Split ข้อมูลเป็น 2 ชุด:
Training set สำหรับสร้าง model
Test set สำหรับประเมิน model
# Set seed for reproducibility
set.seed(500)
# Get training index
train_index <- sample(nrow(mtcars),
nrow(mtcars) * 0.7)
# Split the data
train_set <- mtcars[train_index, ]
test_set <- mtcars[-train_index, ]
.
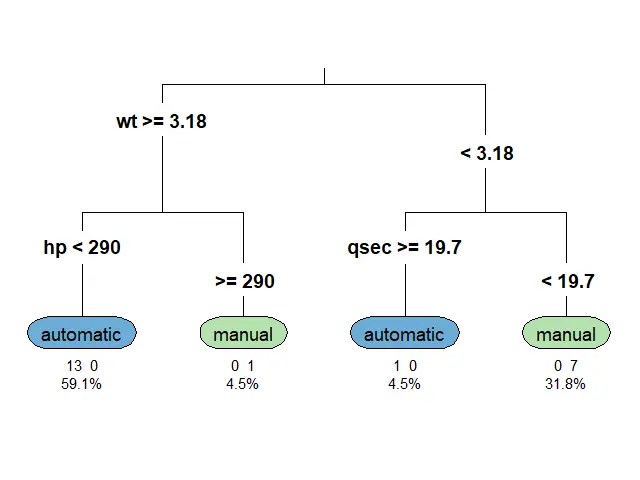
🪴 Train the Model
ตอนนี้ เราพร้อมที่จะสร้าง classification tree ด้วย rpart() แล้ว
สำหรับ classification tree ในบทความนี้ เราจะลองตั้งเงื่อนไขในการปลูกต้นไม้ (control) ดังนี้:
Random forest เป็น tree-based algorithm ที่ช่วยเพิ่มความแม่นยำในการทำนาย โดยสุ่มสร้าง decision trees ต้นเล็กขึ้นมาเป็นกลุ่ม (forest) แทนการปลูก decision tree ต้นเดียว
Decision tree แต่ละต้นใน random forest มีความสามารถในการทำนายแตกต่างกัน ซึ่งบางต้นอาจมีความสามารถที่น้อยมาก
แต่จุดแข็งของ random forest อยู่ที่จำนวน โดย random forest ทำนายผลลัพธ์โดยดูจากผลลัพธ์ในภาพรวม ดังนี้:
Task
Predict by
Regression
ค่าเฉลี่ยของผลลัพธ์การทำนายของทุกต้น
Classification
เสียงส่วนมาก (majority vote)
ดังนั้น แม้ว่า decision tree บางต้นอาจทำนายผิดพลาด แต่โดยรวมแล้ว random forest มีโอกาสที่จะทำนายได้ดีกว่า decision tree ต้นเดียว
ในภาษา R เราสามารถสร้าง random forest ได้ด้วย randomForest() จาก randomForest package ซึ่งต้องการ 3 arguments:
randomFrest(formula, data, ntree)
formula = สูตรในการวิเคราะห์ (ตัวแปรตาม ~ ตัวแปรต้น)
data = dataset ที่ใช้สร้าง model
ntree = จำนวน decision trees ที่ต้องการสร้าง
Note:
เราไม่ต้องกำหนดว่า จะทำ classification หรือ regression model เพราะ randomForest() จะเลือก model ให้อัตโนมัติตามข้อมูลที่เราใส่เข้าไป
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ