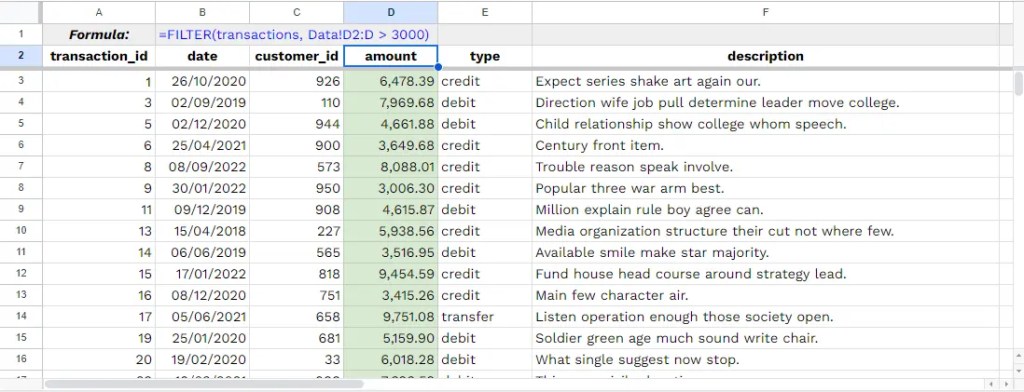
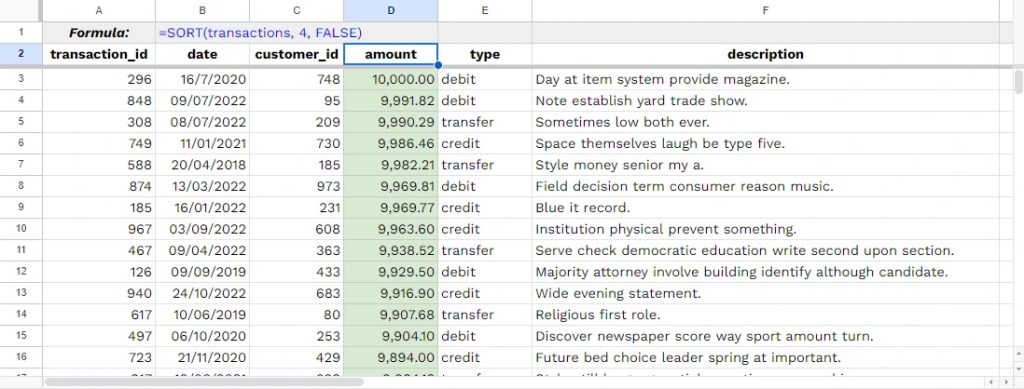
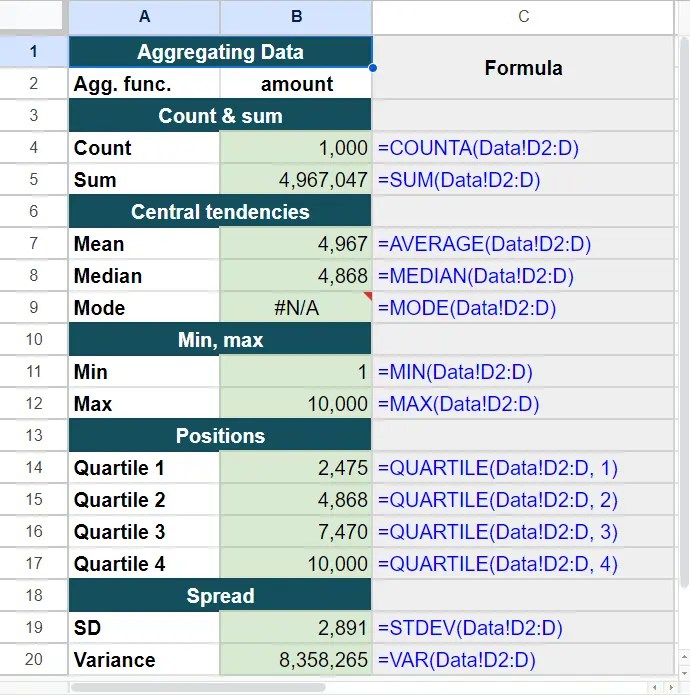
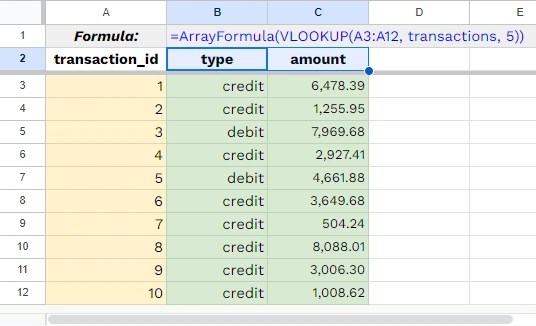
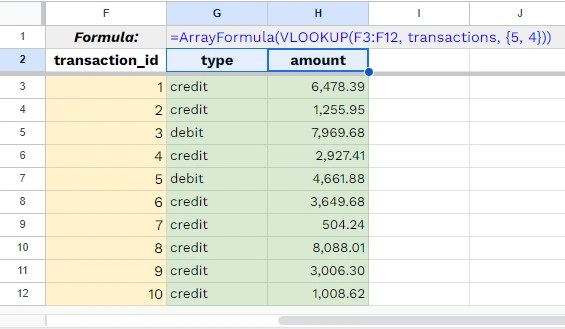
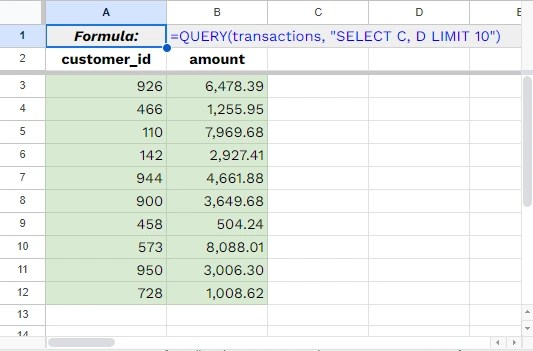
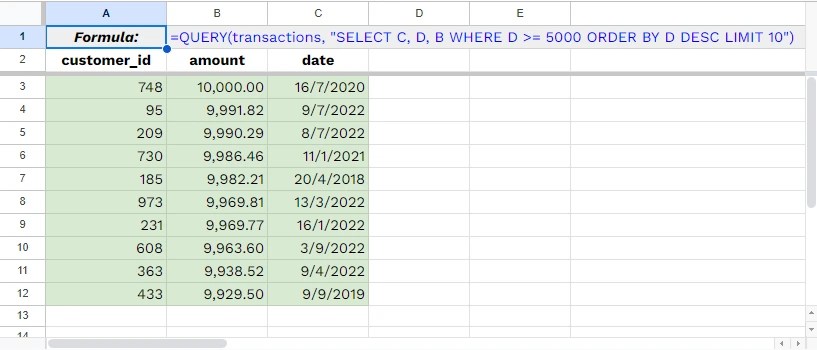
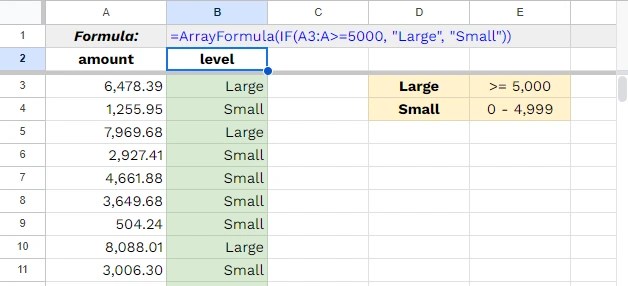
<SQL>
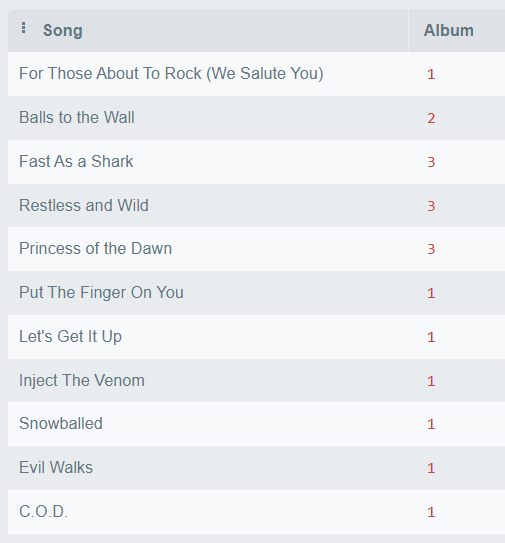
SELECT
`AlbumId`,
COUNT(*) AS `tracks`,
AVG(`Milliseconds`) AS `mean_millisec`,
SUM(`Bytes`) AS `total_bytes`
FROM `Track`
GROUP BY `AlbumId`
ORDER BY `mean_millisec` DESC
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
# List columns in a table
dbGetQuery(con,
"PRAGMA table_info(Artist)")
ผลลัพธ์:
cid name type notnull dflt_value pk
1 0 ArtistId INTEGER 1 NA 1
2 1 Name NVARCHAR(120) 0 NA 0
ในกรณีที่เราต้องการดู columns ในทุก table เราสามารถใช้ for loop ช่วยได้แบบนี้:
# Get the table list
tables <- dbListTables(con)
# Get all columns
for (table_name in tables) {
# Print the table name
message(paste0("\\n👉 Table: ", table_name))
# Get the columns
column_info <- dbGetQuery(con,
paste0("PRAGMA table_info(",
table_name,
")"))
# Print the columns
print(column_info)
}
ผลลัพธ์:
👉 Table: Album
cid name type notnull dflt_value pk
1 0 AlbumId INTEGER 1 NA 1
2 1 Title NVARCHAR(160) 1 NA 0
3 2 ArtistId INTEGER 1 NA 0
👉 Table: Artist
cid name type notnull dflt_value pk
1 0 ArtistId INTEGER 1 NA 1
2 1 Name NVARCHAR(120) 0 NA 0
👉 Table: Customer
cid name type notnull dflt_value pk
1 0 CustomerId INTEGER 1 NA 1
2 1 FirstName NVARCHAR(40) 1 NA 0
3 2 LastName NVARCHAR(20) 1 NA 0
4 3 Company NVARCHAR(80) 0 NA 0
5 4 Address NVARCHAR(70) 0 NA 0
6 5 City NVARCHAR(40) 0 NA 0
7 6 State NVARCHAR(40) 0 NA 0
8 7 Country NVARCHAR(40) 0 NA 0
9 8 PostalCode NVARCHAR(10) 0 NA 0
10 9 Phone NVARCHAR(24) 0 NA 0
11 10 Fax NVARCHAR(24) 0 NA 0
12 11 Email NVARCHAR(60) 1 NA 0
13 12 SupportRepId INTEGER 0 NA 0
👉 Table: Employee
cid name type notnull dflt_value pk
1 0 EmployeeId INTEGER 1 NA 1
2 1 LastName NVARCHAR(20) 1 NA 0
3 2 FirstName NVARCHAR(20) 1 NA 0
4 3 Title NVARCHAR(30) 0 NA 0
5 4 ReportsTo INTEGER 0 NA 0
6 5 BirthDate DATETIME 0 NA 0
7 6 HireDate DATETIME 0 NA 0
8 7 Address NVARCHAR(70) 0 NA 0
9 8 City NVARCHAR(40) 0 NA 0
10 9 State NVARCHAR(40) 0 NA 0
11 10 Country NVARCHAR(40) 0 NA 0
12 11 PostalCode NVARCHAR(10) 0 NA 0
13 12 Phone NVARCHAR(24) 0 NA 0
14 13 Fax NVARCHAR(24) 0 NA 0
15 14 Email NVARCHAR(60) 0 NA 0
👉 Table: Genre
cid name type notnull dflt_value pk
1 0 GenreId INTEGER 1 NA 1
2 1 Name NVARCHAR(120) 0 NA 0
👉 Table: Invoice
cid name type notnull dflt_value pk
1 0 InvoiceId INTEGER 1 NA 1
2 1 CustomerId INTEGER 1 NA 0
3 2 InvoiceDate DATETIME 1 NA 0
4 3 BillingAddress NVARCHAR(70) 0 NA 0
5 4 BillingCity NVARCHAR(40) 0 NA 0
6 5 BillingState NVARCHAR(40) 0 NA 0
7 6 BillingCountry NVARCHAR(40) 0 NA 0
8 7 BillingPostalCode NVARCHAR(10) 0 NA 0
9 8 Total NUMERIC(10,2) 1 NA 0
👉 Table: InvoiceLine
cid name type notnull dflt_value pk
1 0 InvoiceLineId INTEGER 1 NA 1
2 1 InvoiceId INTEGER 1 NA 0
3 2 TrackId INTEGER 1 NA 0
4 3 UnitPrice NUMERIC(10,2) 1 NA 0
5 4 Quantity INTEGER 1 NA 0
👉 Table: MediaType
cid name type notnull dflt_value pk
1 0 MediaTypeId INTEGER 1 NA 1
2 1 Name NVARCHAR(120) 0 NA 0
👉 Table: Playlist
cid name type notnull dflt_value pk
1 0 PlaylistId INTEGER 1 NA 1
2 1 Name NVARCHAR(120) 0 NA 0
👉 Table: PlaylistTrack
cid name type notnull dflt_value pk
1 0 PlaylistId INTEGER 1 NA 1
2 1 TrackId INTEGER 1 NA 2
👉 Table: Track
cid name type notnull dflt_value pk
1 0 TrackId INTEGER 1 NA 1
2 1 Name NVARCHAR(200) 1 NA 0
3 2 AlbumId INTEGER 0 NA 0
4 3 MediaTypeId INTEGER 1 NA 0
5 4 GenreId INTEGER 0 NA 0
6 5 Composer NVARCHAR(220) 0 NA 0
7 6 Milliseconds INTEGER 1 NA 0
8 7 Bytes INTEGER 0 NA 0
9 8 UnitPrice NUMERIC(10,2) 1 NA 0
# Query with dbReadTable()
dbReadTable(con,
"Genre")
ผลลัพธ์:
GenreId Name
1 1 Rock
2 2 Jazz
3 3 Metal
4 4 Alternative & Punk
5 5 Rock And Roll
6 6 Blues
7 7 Latin
8 8 Reggae
9 9 Pop
10 10 Soundtrack
11 11 Bossa Nova
12 12 Easy Listening
13 13 Heavy Metal
14 14 R&B/Soul
15 15 Electronica/Dance
16 16 World
17 17 Hip Hop/Rap
18 18 Science Fiction
19 19 TV Shows
20 20 Sci Fi & Fantasy
21 21 Drama
22 22 Comedy
23 23 Alternative
24 24 Classical
25 25 Opera
# Query with dbGetQuery() - example 2
dbGetQuery(con,
"SELECT
BillingCountry,
SUM(Total) AS TotalSales
FROM
Invoice
GROUP BY
BillingCountry
ORDER BY
TotalSales DESC;")
ผลลัพธ์:
BillingCountry TotalSales
1 USA 523.06
2 Canada 303.96
3 France 195.10
4 Brazil 190.10
5 Germany 156.48
6 United Kingdom 112.86
7 Czech Republic 90.24
8 Portugal 77.24
9 India 75.26
10 Chile 46.62
11 Ireland 45.62
12 Hungary 45.62
13 Austria 42.62
14 Finland 41.62
15 Netherlands 40.62
16 Norway 39.62
17 Sweden 38.62
18 Spain 37.62
19 Poland 37.62
20 Italy 37.62
21 Denmark 37.62
22 Belgium 37.62
23 Australia 37.62
24 Argentina 37.62
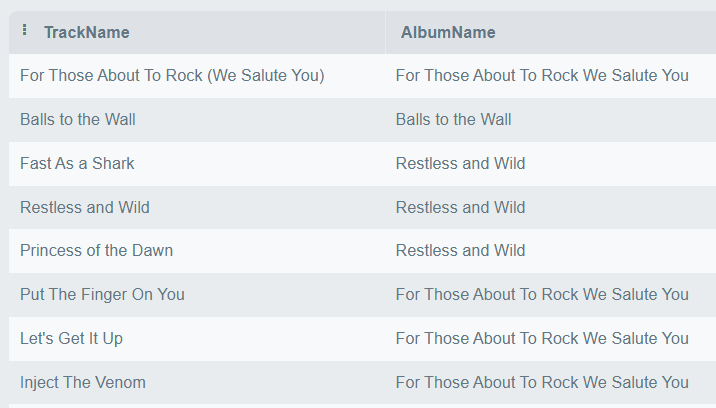
# Query with dbGetQuery() - example 3
dbGetQuery(con,
"SELECT
T.Name AS TrackName,
A.Title AS AlbumTitle
FROM
Track AS T
JOIN
Album AS A ON T.AlbumID = A.AlbumID
LIMIT 10;")
ผลลัพธ์:
TrackName AlbumTitle
1 For Those About To Rock (We Salute You) For Those About To Rock We Salute You
2 Balls to the Wall Balls to the Wall
3 Fast As a Shark Restless and Wild
4 Restless and Wild Restless and Wild
5 Princess of the Dawn Restless and Wild
6 Put The Finger On You For Those About To Rock We Salute You
7 Let's Get It Up For Those About To Rock We Salute You
8 Inject The Venom For Those About To Rock We Salute You
9 Snowballed For Those About To Rock We Salute You
10 Evil Walks For Those About To Rock We Salute You
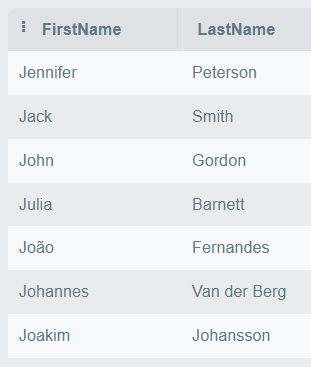
# Send query
res <- dbSendQuery(con,
"SELECT
CustomerId,
LastName,
FirstName,
Email
FROM
Customer
ORDER BY
LastName
LIMIT 10;")
# Fetch five, twice
dbFetch(res, n = 5)
dbFetch(res, n = 5)
dbFetch(res, n = 5)
ผลลัพธ์:
> dbFetch(res, n = 5)
CustomerId LastName FirstName Email
1 12 Almeida Roberto roberto.almeida@riotur.gov.br
2 28 Barnett Julia jubarnett@gmail.com
3 39 Bernard Camille camille.bernard@yahoo.fr
4 18 Brooks Michelle michelleb@aol.com
5 29 Brown Robert robbrown@shaw.ca
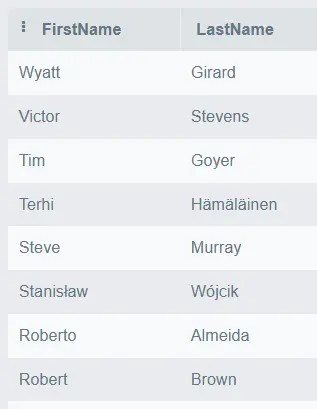
> dbFetch(res, n = 5)
CustomerId LastName FirstName Email
1 21 Chase Kathy kachase@hotmail.com
2 26 Cunningham Richard ricunningham@hotmail.com
3 41 Dubois Marc marc.dubois@hotmail.com
4 34 Fernandes João jfernandes@yahoo.pt
5 30 Francis Edward edfrancis@yachoo.ca
> dbFetch(res, n = 5)
[1] CustomerId LastName FirstName Email
<0 rows> (or 0-length row.names)
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
SELECT Album.Title AS AlbumName, SUM(Track.UnitPrice) AS TotalRevenue
FROM Album
JOIN Track
ON Album.AlbumId = Track.AlbumId
WHERE Track.UnitPrice > 0.99
GROUP BY Album.AlbumId
ORDER BY TotalRevenue DESC
LIMIT 5;