
- 💻 ภาษา R
- 🔢 dplyr: Library สำหรับหมุนข้อมูล
- 🧑💼 ตัวอย่างข้อมูล HR
- ✍️ Pattern การเขียน Function
- 1️⃣ Function #1: select()
- 2️⃣ Function #2: filter()
- 3️⃣ Function #3: arrange()
- 4️⃣ Function #4: summarise()
- 5️⃣ Function #5: mutate()
- 🫂 Put Everything Together: Pipe Operator
- 🔥 สรุป 5 Functions จาก dplyr
- 💪 Try It Yourself
- 📚 อ่านเพิ่มเติมเกี่ยวกับ dplyr
- ✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
💻 ภาษา R
R เป็นภาษาคอมพิวเตอร์ที่ออกแบบมาเพื่อทำงานกับ data เหมาะกับสายงานที่ต้องทำงานกับ data เช่น
- Researcher ที่ต้องการวิเคราะห์ลักษณะกลุ่มตัวอย่าง เช่น จำนวนตัวอย่างแบ่งตามเพศ หรือช่วงอายุ
- Data analyst ที่ต้องการหา insight จากข้อมูลขององค์กร เช่น วิเคราะห์แนวโน้มทางธุรกิจ
- Sale ที่ต้องการวิเคราะห์ข้อมูลการขาย เช่น จำนวนลูกค้า ยอดขาย และกำไร
- หรือแม้แต่ HR ที่ต้องการทำข้อมูลพนักงาน เช่น วิเคราะห์ performance, engagement, และ job satisfaction
🔢 dplyr: Library สำหรับหมุนข้อมูล
R มี built-in functions และ libraries หลากหลายที่รองรับการทำงานกับ data ในรูปแบบต่าง ๆ ซึ่งหนึ่งใน libraries ที่นิยมใช้กัน ได้แก่ dplyr
dplyr เป็น library ที่ออกแบบมาเพื่อ data transformation หรือการแปลงข้อมูล ช่วยให้การทำงานกับ data ง่ายขึ้น เมื่อเทียบกับ built-in functions
Use case ของ dplyr เช่น:
- สำรวจข้อมูล (data exploration)
- ทำความสะอาดข้อมูล (data cleaning)
- วิเคราะห์ข้อมูล (data analysis)
.
ในบทความนี้ เราจะไปทำความรู้จักกับ 5 functions พื้นฐานของ dplyr ที่ใช้ทำงานกับข้อมูลกัน ซึ่งได้แก่:
select()filter()arrange()summarise()หรือsummarize()(เขียนได้ทั้งสองแบบ)mutate()

🧑💼 ตัวอย่างข้อมูล HR
ในบทความนี้ เราจะใช้ชุดข้อมูลจำลอง hr_data เพื่อช่วยอธิบายการใช้งาน 5 functions ของ dplyr
hr_data ช่วยจำลองสถานการณ์ของ HR ที่ต้องวิเคราะห์ข้อมูลพนักงาน เพื่อหาวิธีแก้ปัญหาพนักงานลาออก (attrition)
โดย hr_data ประกอบด้วย 8 ตัวแปร:
| No. | Column | Data |
|---|---|---|
| 1 | ID | รหัสพนักงาน |
| 2 | Name | ชื่อพนักงาน |
| 3 | Department | แผนก |
| 4 | Age | อายุ |
| 5 | Engagement | คะแนนการมีส่วนร่วม (1 ถึง 100) |
| 6 | YearsAtCompany | อายุงาน |
| 7 | AttritionRisk | ความเสี่ยงที่จะลาออก (Low, Medium, High) |
| 8 | Salary | เงินเดือน |
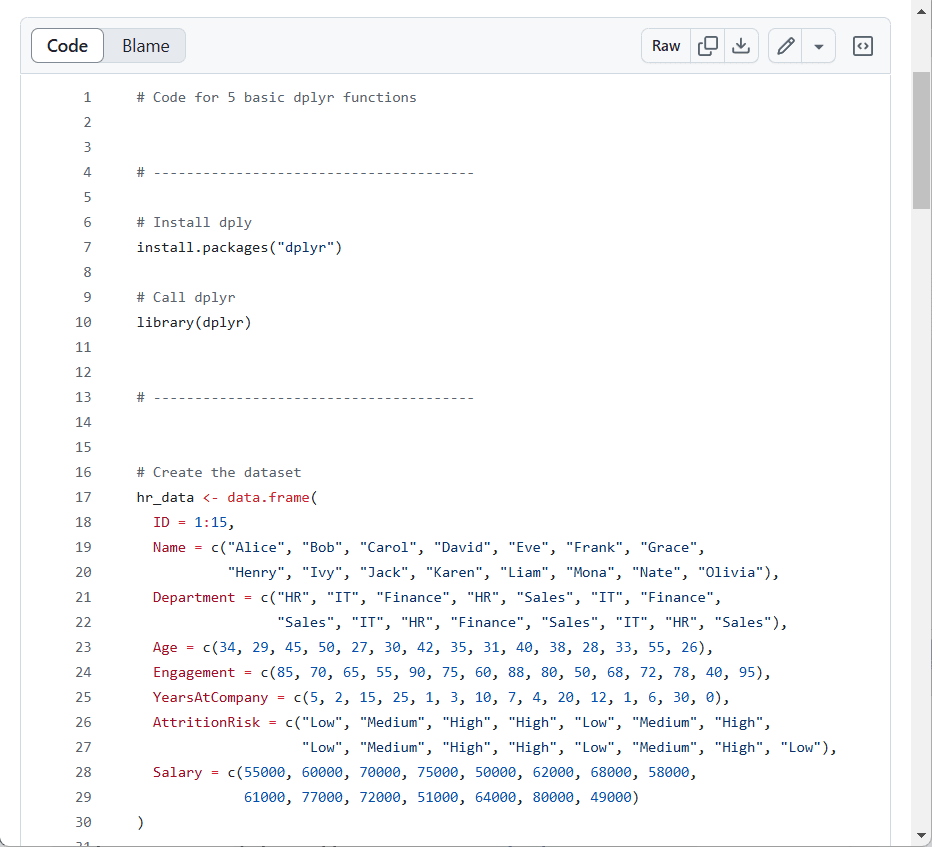
Code ในการสร้างและเรียกดู hr_data:
# Create the dataset
hr_data <- data.frame(
ID = 1:15,
Name = c("Alice", "Bob", "Carol", "David", "Eve", "Frank", "Grace",
"Henry", "Ivy", "Jack", "Karen", "Liam", "Mona", "Nate", "Olivia"),
Department = c("HR", "IT", "Finance", "HR", "Sales", "IT", "Finance",
"Sales", "IT", "HR", "Finance", "Sales", "IT", "HR", "Sales"),
Age = c(34, 29, 45, 50, 27, 30, 42, 35, 31, 40, 38, 28, 33, 55, 26),
Engagement = c(85, 70, 65, 55, 90, 75, 60, 88, 80, 50, 68, 72, 78, 40, 95),
YearsAtCompany = c(5, 2, 15, 25, 1, 3, 10, 7, 4, 20, 12, 1, 6, 30, 0),
AttritionRisk = c("Low", "Medium", "High", "High", "Low", "Medium", "High",
"Low", "Medium", "High", "High", "Low", "Medium", "High", "Low"),
Salary = c(55000, 60000, 70000, 75000, 50000, 62000, 68000, 58000,
61000, 77000, 72000, 51000, 64000, 80000, 49000)
)
# View the dataset
hr_data
ผลลัพธ์:

✍️ Pattern การเขียน Function
แม้ว่าทั้ง 5 functions จะมีหน้าที่แตกต่างกัน แต่มีการเรียกใช้งานที่เหมือนกัน:
func(dataset, condition)
func= ชื่อ function เช่น select, filter, arrangedataset= ชุดข้อมูลที่เป็น inputcondition= เงื่อนไขในการใช้งานทำงานของ function
1️⃣ Function #1: select()
select() ใช้เลือก column ข้อมูลที่ต้องการ
ตัวอย่าง:
ผู้บริหารต้องการข้อมูลที่มีแค่รายชื่อพนักงาน แผนก และคะแนนการมีส่วนร่วม
เราสามารถใช้ select() เลือกเฉพาะ column ที่ต้องการได้:
# Select only desired columns
select(hr_data,
Name,
Department,
Engagement)
ผลลัพธ์:
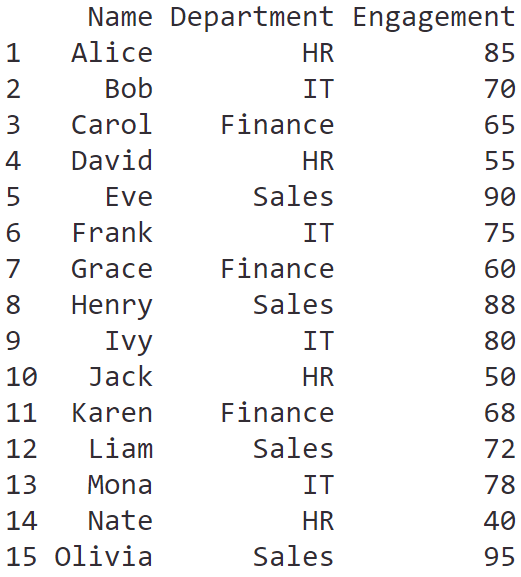
.
Note:
เวลาเลือก column ด้วย select() เราสามารถกำหนดลำดับของ column ที่จะมาแสดงได้ เช่น ต้องการแสดง Department ก่อน Name ก็ให้เขียน Department, Name
.
dplyr มี helper function ที่ช่วยในการเลือก column ให้ง่ายขึ้น เช่น:
| Function | Meaning |
|---|---|
starts_with() | เลือก column ที่เริ่มด้วย x |
ends_with() | เลือก column ที่ลงท้ายด้วย x |
contains() | เลือก column ที่มีคำว่า x |
matches() | เลือก column ที่ตรงกับ regular expression |
last_col() | เลือก column สุดท้ายในชุดข้อมูล |
~ | เลือกทุก column ยกเว้น column ที่ระบุ |
.
เราสามารถตั้งชื่อ column ใหม่ได้ ด้วยใช้ = เช่น FullName = Name เพื่อให้หัว column แสดงคำว่า Fullname แทน Name
2️⃣ Function #2: filter()
filter() ใช้เลือก row ที่ตรงกับเงื่อนไขที่กำหนดมาแสดง
ตัวอย่าง:
ผู้บริหารต้องการข้อมูลพนักงานที่ความเสี่ยงที่จะลาออกสูง
เราสามารถใช้ filter() เพื่อกำหนดเงื่อนไขเพื่อกรองข้อมูลออกมาได้:
# Filter for high attrition risk
filter(hr_data,
AttritionRisk == "High")
ผลลัพธ์:
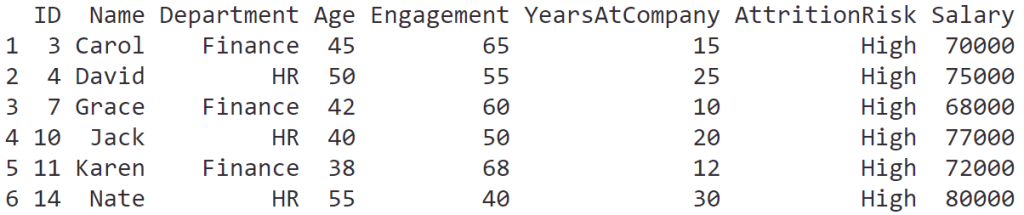
.
Note:
เราสามารถใช้ boolean operator และ comparison operator ร่วมได้:
| Operator | Meaning |
|---|---|
== | เท่ากับ |
!= | ไม่เท่ากับ |
> | มากกว่า |
< | น้อยกว่า |
& | and |
| | or |
! | not |
เช่น:
ผู้บริหารต้องการข้อมูลพนักงานที่ความเสี่ยงที่จะลาออกสูง ในแผนกการเงิน (Finance)
# Filter for high attrition risk in Finance
filter(hr_data,
AttritionRisk == "High" & Department == "Finance")
ผลลัพธ์:
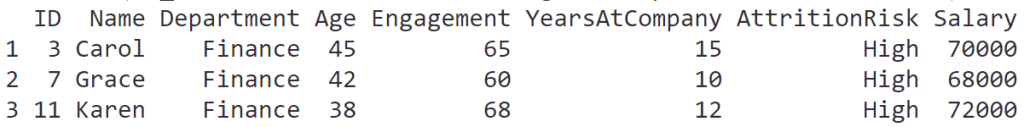
3️⃣ Function #3: arrange()
arrange() ใช้เรียงข้อมูลตามเงื่อนไข
ตัวอย่าง:
ผู้บริหารอยากได้ข้อมูลพนักงานเรียงจากคะแนนการมีส่วนร่วม
เราสามารถใช้ arrange() จัดลำดับตาม column ที่ต้องการได้:
# Sort employees by engagement
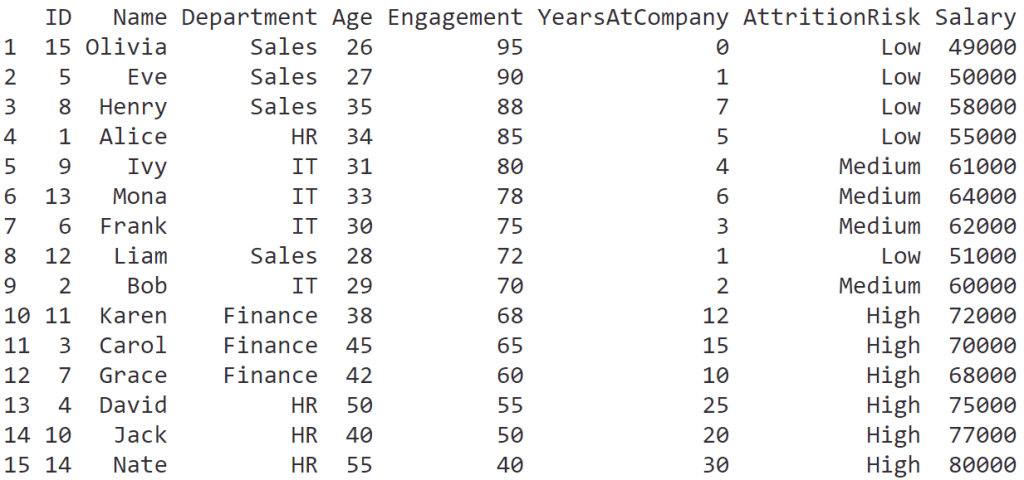
arrange(hr_data,
Engagement)
ผลลัพธ์:
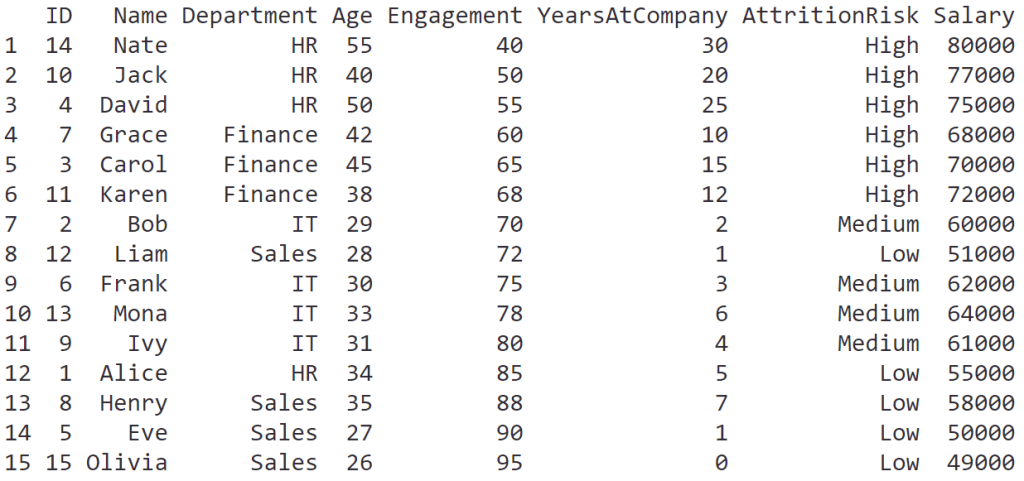
.
Note:
Default ของ arrange() เป็นเรียงจากน้อยไปมาก (A-Z)
ถ้าต้องการเรียงจากน้อยไปมาก (Z-A) ให้ใช้ desc() เช่น:
# Sort employees by engagement, from high to low
arrange(hr_data,
desc(Engagement))
ผลลัพธ์:
4️⃣ Function #4: summarise()
summarise() ใช้ย่อยข้อมูลให้น้อยลง ช่วยให้เข้าใจข้อมูลได้ง่ายขึ้น
ตัวอย่าง:
ผู้บริการต้องการรู้ค่าเฉลี่ยคะแนนการมีส่วนร่วม
เราสามารถใช้ summarise() เพื่อหาค่าเฉลี่ยได้:
# Calculate mean engagement
summarise(hr_data,
mean(Engagement))
ผลลัพธ์:

.
Note:
Functions ที่มักใช้กับ summarise() ได้แก่:
| Function | Meaning |
|---|---|
mean() | หาค่าเฉลี่ย |
min() | หาค่าต่ำสุด |
max() | หาค่าสูงสุด |
sd() | หาค่าเบี่ยงเบนมาตรฐาน (standard deviation) |
n() | นับจำนวนข้อมูล |
.
summarise() มักใช้กับ group_by() เพื่อหาค่าสถิติตามกลุ่มข้อมูล เช่น หาค่าเฉลี่ยคะแนนการทำงานตามระดับความเสี่ยงในการลาออก:
# Calculate mean engagement by attrition risk
summarise(group_by(hr_data, AttritionRisk),
mean(Engagement))
ผลลัพธ์:

.
นอกจากนี้ เราสามารถตั้งชื่อ column ของค่าสถิติได้โดยใช้ = ได้ เช่น:
# Naming the output
summarise(group_by(hr_data, AttritionRisk),
AvgEng = mean(Engagement))
ผลลัพธ์:

5️⃣ Function #5: mutate()
mutate() ใช้สำหรับสร้างข้อมูลใหม่จากข้อมูลที่มีอยู่แล้ว
ตัวอย่าง:
ผู้บริหารอยากรู้ว่า พนักงานแต่ละคนเหลือเวลาก่อนเกษียณอายุเท่าไร
เราสามารถใช้ mutate() เพื่อสร้าง column ใหม่ที่แสดงจำนวนปีก่อนเกษียณได้:
# Add a new column
mutate(hr_data,
YearsUntilRetirement = 60 - Age)
ผลลัพธ์:
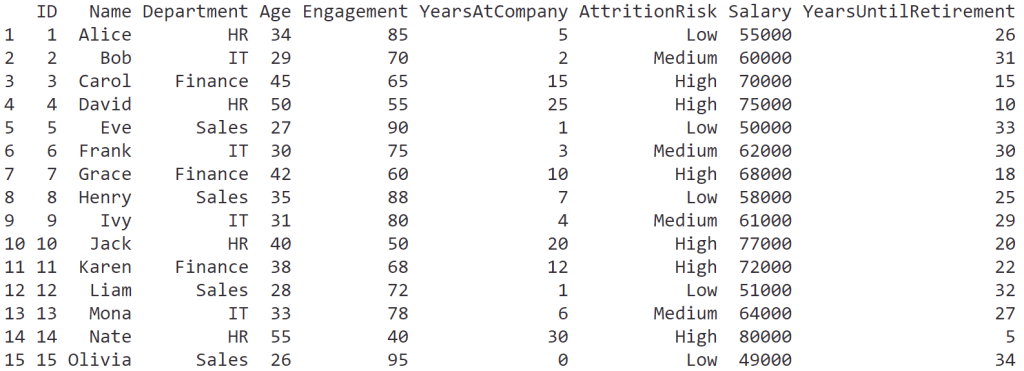
จากผลลัพธ์ จะเห็นได้ว่า column ใหม่จะต่อท้ายสุด (ด้านขวาสุด)
.
Note:
ถ้าต้องการเห็นแค่ข้อมูลใหม่ เราสามารถเปลี่ยน mutate() เป็น transmute() ได้
โดยหลังจากได้ข้อมูลใหม่แล้ว transmute() จะทิ้งข้อมูลตั้งต้น และเก็บเฉพาะข้อมูลใหม่ไว้
🫂 Put Everything Together: Pipe Operator
เราจะเห็นความสามารถที่แท้จริงของ dplyr ได้เมื่อใช้งานทั้ง 5 functions ร่วมกัน โดยใช้ pipe operator: %>% หรือ |>
Pipe operator เป็นสิ่งที่ช่วยส่ง output จาก function หนึ่งไปเป็น input ของ function ต่อไป
เช่น จาก code หาค่าเฉลี่ยคะแนนการทำงานตามระดับความเสี่ยงในการลาออก ก่อนหน้านี้:
# Calculate mean engagement by attrition risk
summarise(group_by(hr_data, AttritionRisk),
AvgEng = mean(Engagement))
ถ้าใช้ pipe operator แล้ว จะเขียนได้แบบนี้:
# Calculate mean engagement by attrition risk
hr_data |>
# Group by AttritionRisk
group_by(AttritionRisk) |>
# Calculate mean
summarise(AvgEng = mean(Engagement))
ซึ่ง code ทั้งสองชุดให้ผลลัพธ์ที่เหมือนกัน:

แต่จะเห็นได้ว่า code ที่ใช้ pipe operator มีความชัดเจนและอ่านง่ายกว่า เพราะไม่จำเป็นต้องเขียน code ที่ซ้อนกันเป็นชั้น ๆ
.
ทีนี้ ถ้าเราใช้ pipe operator เพื่อรวมทั้ง 5 functions เข้าด้วยกันแล้ว จะทำให้เราใช้ข้อมูลเพื่อตอบคำถามที่ซับซ้อนขึ้นได้
ตัวอย่าง:
ผู้บริหารอยากได้รายชื่อพนักงานในกลุ่มเสี่ยงลาออกสูง โดยเรียงตามอายุงานและเงินเดือน จากมากไปน้อย
เราสามารถใช้ pipe operator ร่วมกัน group_by() + summarise() + arrange() เพื่อตอบโจทย์ได้:
# Find employees with high attrition risk
# and sort by tenure and salary
hr_data |>
# Filter for high attrition risk
filter(AttritionRisk == "High") |>
# Sort descending by tenure and salary
arrange(desc(YearsAtCompany),
desc(Salary))
ผลลัพธ์:
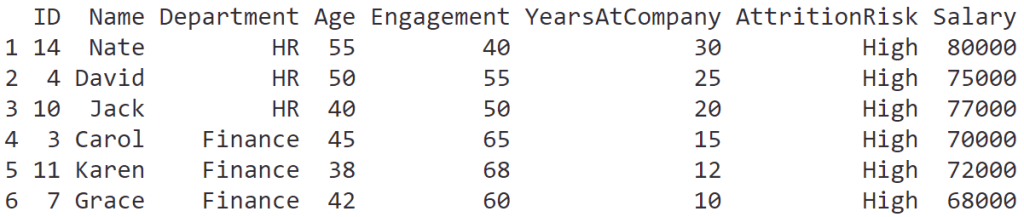
.
หรือ
ผู้บริหารต้องการรู้ว่า จำนวนพนักงานและค่าเฉลี่ยคะแนนการมีส่วนร่วมของแต่ละแผนก โดยเรียงแผนกจากค่าเฉลี่ยมากไปน้อย
hr_data |>
# Group by department
group_by(Department) |>
# Calculate mean and count the number of employees
summarise(AvgEng = mean(Engagement),
EmpCount = n()) |>
# Sort descending by average engagement
arrange(desc(AvgEng))
ผลลัพธ์:

.
หรือ
ผู้บริหารต้องการรู้สัดส่วนพนักงานในกลุ่มความเสี่ยงสูงในแต่ละแผนก โดยเรียงจากมากไปน้อย และขอให้เรียงข้อมูลดังนี้: แผนก สัดส่วนเสี่ยงสูง จำนวนพนักงานทั้งหมด จำนวนพนักงานในกลุ่มเสี่ยงสูง
hr_data |>
# Group by department
group_by(Department) |>
# Count high attrition risk and find attrition risk ratio
summarise(HighRiskCount = sum(AttritionRisk == "High"),
TotalEmp = n(),
HighRiskRatio = (HighRiskCount / TotalEmp) * 100) |>
# Select desired columns
select(Department, HighRiskRatio, TotalEmp, HighRiskCount) |>
# Sort descending by high rish ratio
arrange(desc(HighRiskRatio))
ผลลัพธ์:

🔥 สรุป 5 Functions จาก dplyr
5 functions พื้นฐาน ของ dplyr เป็น functions ที่สามารถใช้ร่วมกันเพื่อทำงานกับข้อมูลต่าง ๆ เช่น ข้อมูลพนักงาน ได้อย่างมีประสิทธิภาพ
| No. | Function | Explain |
|---|---|---|
| 1 | select() | เลือก column ที่ต้องการ |
| 2 | filter() | เลือก row ที่ต้องการ |
| 3 | arrange() | จัดลำดับข้อมูล |
| 4 | sumamrise() | สรุปข้อมูล |
| 5 | mutate() | แปลงข้อมูล |
Note: ใช้ %>% หรือ |> เพื่อเชื่อม functions เข้าด้วยกัน
💪 Try It Yourself
สำหรับใครที่อยากลองเล่นใช้ R เล่นกับข้อมูล HR สามารถดาวน์โหลด code ตัวอย่างในบทความได้ที่ GitHub
📚 อ่านเพิ่มเติมเกี่ยวกับ dplyr
- หนังสือ R for Data Science – สอนใช้ 5 functions ของ
dplyrด้วยชุดข้อมูลnycflights13พร้อมแบบฝึกหัด: https://r4ds.hadley.nz/data-transform.html - Posit Cheatsheets – สรุปการใช้งาน 5 functions ของ
dplyr: https://rstudio.github.io/cheatsheets/html/data-transformation.html - Official dplyr Documentation – คู่มืออย่างเป็นทางการในการใช้ 5 functions ของ
dplyr: https://dplyr.tidyverse.org/
✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
📕 ขอฝากหนังสือเล่มแรกในชีวิตด้วยนะครับ 😆
🙋 ใครที่กำลังเรียนจิตวิทยาหรือทำงานสายจิตวิทยา และเบื่อที่ต้องใช้ software ราคาแพงอย่าง SPSS และ Excel เพื่อทำข้อมูล
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
- Correlation
- t-tests
- ANOVA
- Reliability
- Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
แล้วทุกคนจะแปลกใจว่า ทำไมภาษา R ง่ายขนาดนี้ 🙂↕️
👉 สนใจดูรายละเอียดหนังสือได้ที่ meb:
