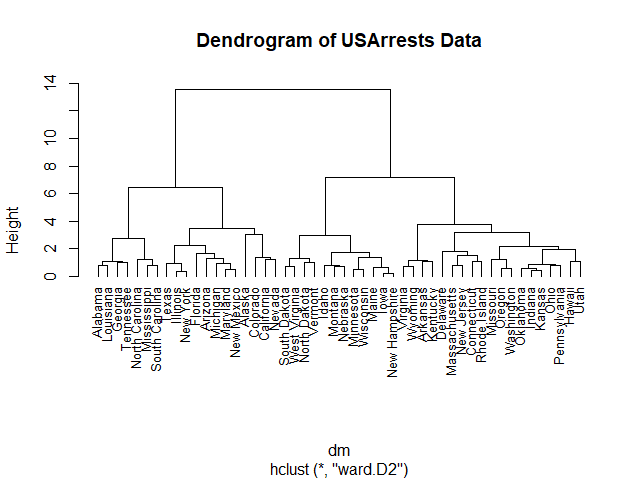
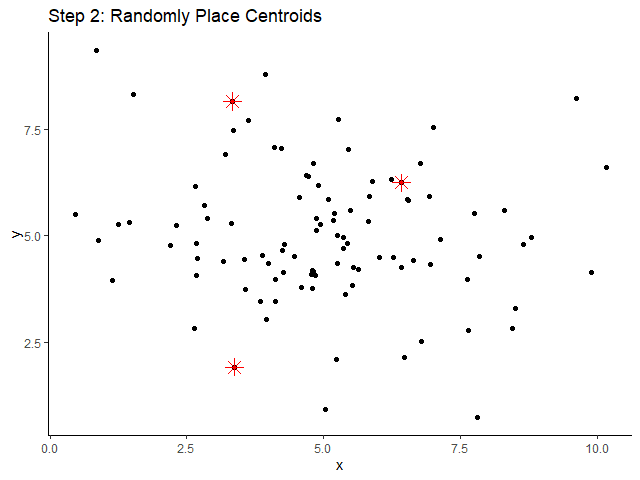
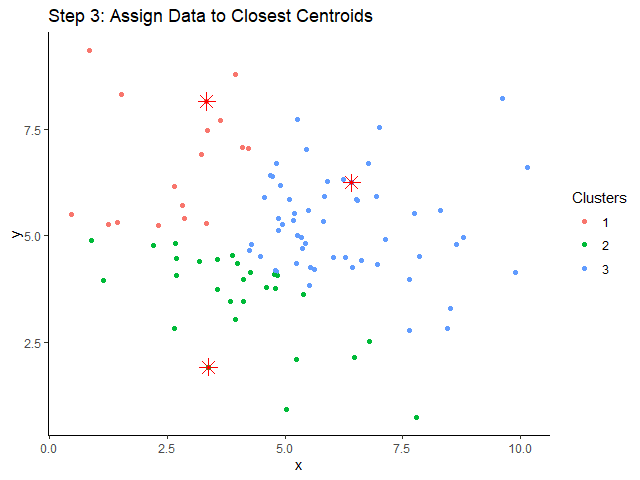
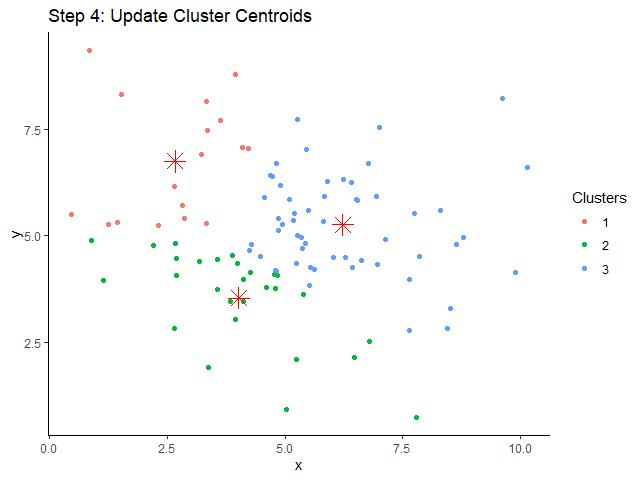
XGBoost เป็น machine learning model ที่จัดอยู่ในกลุ่ม tree-based models หรือ models ที่ทำนายข้อมูลด้วย decision tree อย่าง single decision tree และ random forest
ใน XGBoost, decision trees จะถูกสร้างขึ้นมาเป็นรอบ ๆ โดยในแต่ละรอบ decision trees ใหม่จะเรียนรู้จากความผิดพลาดของรอบก่อน ซึ่งจะทำให้ decision trees ใหม่มีความสามารถที่ดีขึ้นเรื่อย ๆ
เมื่อสิ้นสุดการสร้าง XGBoost ใช้ผลรวมของ decision trees ทุกต้นในการทำนายข้อมูล ดังนี้:
# A tibble: 6 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compact
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compact
3 audi a4 2 2008 4 manual(m6) f 20 31 p compact
4 audi a4 2 2008 4 auto(av) f 21 30 p compact
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compact
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compact
จากผลลัพธ์ เราจะเห็นได้ว่า mpg มี columns ที่เราต้องปรับจาก character เป็น factor อยู่ เช่น manufacturer, model ซึ่งเราสามารถปรับได้ดังนี้:
# Convert character columns to factor
## Get character columns
chr_cols <- c("manufacturer",
"model",
"trans",
"drv",
"fl",
"class")
## For-loop through the character columns
for (col in chr_cols) {
mpg[[col]] <- as.factor(mpg[[col]])
}
## Check the results
str(mpg)
# Separate the features from the outcome
## Get the features
x <- mpg[, !names(mpg) %in% "hwy"]
## One-hot encode the features
x <- model.matrix(~ . - 1,
data = x)
## Get the outcome
y <- mpg$hwy
ข้อที่ 2. จากนั้น เราจะแบ่ง dataset เป็น training (80%) และ test sets (20%) ดังนี้:
# Split the data
## Set seed for reproducibility
set.seed(360)
## Get training index
train_index <- sample(1:nrow(x),
nrow(x) * 0.8)
## Create x, y train
x_train <- x[train_index, ]
y_train <- y[train_index]
## Create x, y test
x_test <- x[-train_index, ]
y_test <- y[-train_index]
## Check the results
cat("TRAIN SET", "\\n")
cat("1. Data in x_train:", nrow(x_train), "\\n")
cat("2. Data in y_train:", length(y_train), "\\n")
cat("---", "\\n", "TEST SET", "\\n")
cat("1. Data in x_test:", nrow(x_test), "\\n")
cat("2. Data in y_test:", length(y_test), "\\n")
ผลลัพธ์:
TRAIN SET
1. Data in x_train: 187
2. Data in y_train: 187
---
TEST SET
1. Data in x_test: 47
2. Data in y_test: 47
.
ข้อที่ 3. สุดท้าย เราจะแปลง x, y เป็น DMatrix ซึ่งเป็น object ที่ xgboost ใช้ในการสร้าง XGboost model ดังนี้:
# Convert to DMatrix
## Training set
train_set <- xgb.DMatrix(data = x_train,
label = y_train)
## Test set
test_set <- xgb.DMatrix(data = x_test,
label = y_test)
## Check the results
train_set
test_set
ผลลัพธ์:
TRAIN SET
xgb.DMatrix dim: 187 x 77 info: label colnames: yes
---
TEST SET
xgb.DMatrix dim: 47 x 77 info: label colnames: yes
4️⃣ Train the Model
ในขั้นที่สี่ เราจะสร้าง XGBoost model ด้วย xgb.train() ซึ่งต้องการ 5 arguments ดังนี้:
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
ในการทำ machine learning (ML) ในภาษา R เรามี packages และ functions ที่หลากหลายให้เลือกใช้งาน ซึ่งแต่ละ package และ function มีวิธีใช้งานที่แตกต่างกันไป
ยกตัวอย่างเช่น:
glm() จาก base R สำหรับสร้าง regression models ต้องการ input 3 อย่าง คือ formula, data, และ family:
glm(formula, data, family)
knn() จาก class package สำหรับสร้าง KNN model ต้องการ input 4 อย่าง คือ ตัวแปรต้นของ training set, ตัวแปรต้นของ test set, ตัวแปรตามของ training set, และค่า k:
knn(train_x, test_x, train_y, k)
rpart() จาก rpart package สำหรับสร้าง decision tree model ต้องการ input 2 อย่าง คือ formula และ data:
rpart(formula, data)
…
การใช้งาน function ที่แตกต่างกันทำให้การสร้าง ML models เกิดความซับซ้อนโดยไม่จำเป็น และทำให้เกิดความผิดพลาดในการทำงานได้ง่าย
# Set seed for reproducibility
set.seed(2025)
# Define the training set index
bt_split <- initial_split(data = bt,
prop = 0.8,
strata = medv)
# Create the training set
bt_train <- training(bt_split)
# Create the test set
bt_test <- testing(bt_split)
# Prepare the recipe
rec_prep <- prep(rec,
data = bt_train)
# Bake the training set
bt_train_baked <- bake(rec_prep,
new_data = NULL)
# Bake the test set
bt_test_baked <- bake(rec_prep,
new_data = bt_test)
.
4️⃣ Instantiate a Model
ในขั้นที่ 4 เราจะเรียกใช้ algorithm สำหรับ model ของเรา โดยในตัวอย่าง เราจะลองสร้าง decision tree กัน
ในขั้นนี้ เรามี 3 functions จะเรียกใช้งาน ได้แก่:
No.
Function
For
1
decision_tree()
สร้าง decision tree *
2
set_engine()
กำหนด engine หรือ package ที่ใช้สร้าง model
3
set_mode()
กำหนดประเภท model (classification หรือ regression)
ในขั้นแรก เราจะแบ่ง dataset ออกเป็น 2 ชุด (เหมือนกับ standard flow):
# Set seed for reproducibility
set.seed(2025)
# Define the training set index
bt_split <- initial_split(data = bt,
prop = 0.8,
strata = medv)
# Create the training set
bt_train <- training(bt_split)
จะสังเกตว่า เราจะไม่ได้สร้าง test set ในครั้งนี้
.
2️⃣ Create a Recipe
ในขั้นที่ 2 เราจะสร้าง recipe (เหมือนกับ standard flow):
# Set seed for reproducibility
set.seed(2025)
# Define the training set index
bt_split <- initial_split(data = bt,
prop = 0.8,
strata = medv)
# Create the training set
bt_train <- training(bt_split)
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
caret เป็น package ยอดนิยมในภาษา R ในทำ machine learning (ML)
caret ย่อมาจาก Classification And REgression Training และเป็น package ที่ถูกออกแบบมาช่วยให้การทำ ML เป็นเรื่องง่ายโดยมี functions สำหรับทำงานกับ ML workflow เบ็ดเสร็จใน package เดียว
p = สัดส่วนข้อมูลที่เราต้องการแบ่งให้กับ training set
list = ต้องการผลลัพธ์เป็น list (TRUE) หรือ matrix (FALSE)
สำหรับ BostonHousing เราจะแบ่ง 70% เป็น training set และ 30% เป็น test set แบบนี้:
# Set seed for reproducibility
set.seed(888)
# Get train index
train_index <- createDataPartition(BostonHousing$medv, # Specify the outcome
p = 0.7, # Set aside 70% for training set
list = FALSE) # Return as matrix
# Create training set
bt_train <- BostonHousing[train_index, ]
# Create test set
bt_test <- BostonHousing[-train_index, ]
เราสามารถดูจำนวนข้อมลใน training และ test sets ได้ด้วย nrow():
# Check the results
cat("Rows in training set:", nrow(bt_train), "\\n")
cat("Rows in test set:", nrow(bt_test))
ผลลัพธ์:
Rows in training set: 356
Rows in test set: 150
.
🍳 Step 2. Preprocess the Data
ในขั้นที่ 2 เราจะเตรียมข้อมูลเพื่อใช้ในการสร้าง model
# Learn preprocessing on training set
ppc <- preProcess(bt_train[, -14], # Select all predictors
method = c("center", "scale")) # Centre and scale
ตอนนี้ เราจะได้วิธีการเตรียมข้อมูลมาแล้ว ซึ่งเราจะต้องนำไปปรับใช้กับ training และ test sets ด้วย predict() และ cbind() แบบนี้:
Training set:
# Apply preprocessing to training set
bt_train_processed <- predict(ppc,
bt_train[, -14])
# Combine the preprocessed training set with outcome
bt_train_processed <- cbind(bt_train_processed,
medv = bt_train$medv)
Test set:
# Apply preprocessing to test set
bt_test_processed <- predict(ppc,
bt_test[, -14])
# Combine the preprocessed test set with outcome
bt_test_processed <- cbind(bt_test_processed,
medv = bt_test$medv)
ตอนนี้ training และ test sets ก็พร้อมที่จะใช้ในการสร้าง model แล้ว
.
👟 Step 3. Train the Model
ในขั้นที่ 3 เราจะสร้าง model กัน
โดยในตัวอย่าง เราจะลองสร้าง k-nearest neighbor (KNN) model ซึ่งทำนายข้อมูลด้วยการดูข้อมูลที่อยู่ใกล้เคียง
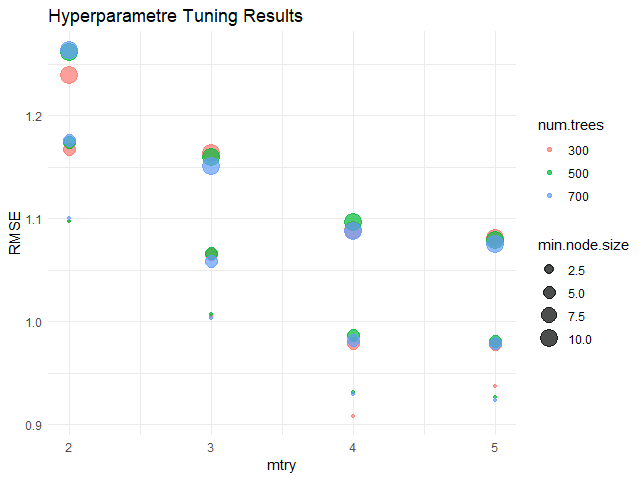
trControl = ค่าที่กำหนดการสร้าง model (ต้องใช้ function ชื่อ trainControl() ในการกำหนด)
tuneGrid = data frame ที่กำหนดค่า hyperparametre เพื่อทำ model tuning และหา model ที่ดีที่สุด
เราสามารถใช้ train() เพื่อสร้าง KNN model ในการทำนายราคาบ้านได้แบบนี้:
# Define training control:
# use k-fold cross-validation where k = 5
trc <- trainControl(method = "cv",
number = 5)
# Define grid:
# set k as odd numbers between 3 and 13
grid <- data.frame(k = seq(from = 3,
to = 13,
by = 2))
# Train the model
knn_model <- train(medv ~ ., # Specify the formula
data = bt_train_processed, # Use training set
method = "kknn", # Use knn engine
trControl = trc, # Specify training control
tuneGrid = grid) # Use grid to tune the model
เราสามารถดูรายละเอียดของ model ได้ดังนี้:
# Print the model
knn_model
ผลลัพธ์:
k-Nearest Neighbors
356 samples
13 predictor
No pre-processing
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 284, 286, 286, 284, 284
Resampling results across tuning parameters:
k RMSE Rsquared MAE
3 4.357333 0.7770080 2.840630
5 4.438162 0.7760085 2.849984
7 4.607954 0.7610468 2.941034
9 4.683062 0.7577702 2.972661
11 4.771317 0.7508908 3.043617
13 4.815444 0.7524266 3.053415
RMSE was used to select the optimal model using the smallest value.
The final value used for the model was k = 3.
.
📈 Step 4. Evaluate the Model
ในขั้นสุดท้าย เราจะประเมินความสามารถของ model ในการทำนายราคาบ้านกัน
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
# A tibble: 6 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compact
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compact
3 audi a4 2 2008 4 manual(m6) f 20 31 p compact
4 audi a4 2 2008 4 auto(av) f 21 30 p compact
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compact
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compact
จากผลลัพธ์จะเห็นว่า บาง columns (เช่น manufacturer, model) มีข้อมูลประเภท character ซึ่งเราควระเปลี่ยนเป็น factor เพื่อช่วยให้การสร้าง model มีประสิทธิภาพมากขึ้น:
# Convert character columns to factor
## Get character columns
chr_cols <- c("manufacturer", "model",
"trans", "drv",
"fl", "class")
## For-loop through the character columns
for (col in chr_cols) {
mpg[[col]] <- as.factor(mpg[[col]])
}
## Check the results
str(mpg)
# Split the data
## Set seed for reproducibility
set.seed(123)
## Get training rows
train_rows <- sample(nrow(mpg),
nrow(mpg) * 0.7)
## Create a training set
train <- mpg[train_rows, ]
## Create a test set
test <- mpg[-train_rows, ]
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
# Check the distribution of `price`
ggplot(dm,
aes(x = price)) +
## Instantiate a histogram
geom_histogram(binwidth = 100,
fill = "skyblue3") +
## Add text elements
labs(title = "Distribution of Price",
x = "Price",
y = "Count") +
## Set theme to minimal
theme_minimal()
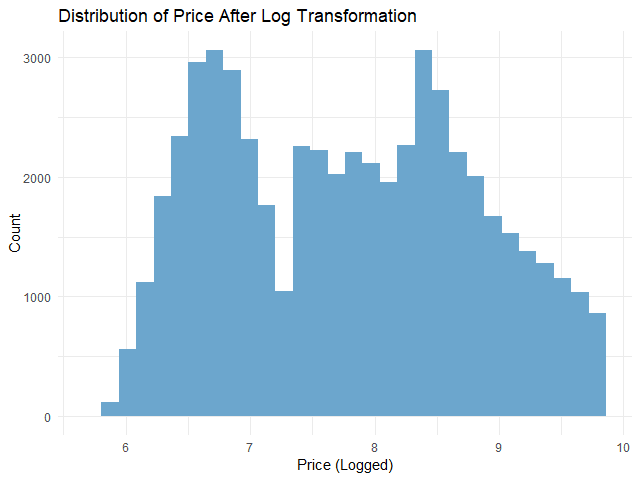
# Check the distribution of logged `price`
ggplot(dm,
aes(x = price_log)) +
## Instantiate a histogram
geom_histogram(fill = "skyblue3") +
## Add text elements
labs(title = "Distribution of Price After Log Transformation",
x = "Price (Logged)",
y = "Count") +
## Set theme to minimal
theme_minimal()
ในขั้นสุดท้ายก่อนใช้ linear regression เราจะแบ่งข้อมูลออกเป็น 2 ชุด:
Training set สำหรับสร้าง linear regression model
Test set สำหรับประเมินความสามารถของ linear regression model
ในบทความนี้ เราจะแบ่ง 80% ของ dataset เป็น training set และ 20% เป็น test set:
# Split the data
## Set seed for reproducibility
set.seed(181)
## Training index
train_index <- sample(nrow(dm),
0.8 * nrow(dm))
## Create training set
train_set <- dm[train_index, ]
## Create test set
test_set <- dm[-train_index, ]
ตอนนี้ เราพร้อมที่จะสร้าง linear regression model กันแล้ว
🏷️ Linear Regression Modelling
การสร้าง linear regression model มีอยู่ 3 ขั้นตอน ได้แก่:
Fit the model
Make predictions
Evaluate the model performance
.
💪 Step 1. Fit the Model
ในขั้นแรก เราจะสร้าง model ด้วย lm() ซึ่งต้องการ input 2 อย่าง:
lm(formula, data)
formula = สูตรการทำนาย โดยเราต้องกำหนดตัวแปรต้นและตัวแปรตาม
data = ชุดข้อมูลที่ใช้สร้าง model
ในการทำนายราคาเพชร เราจะใช้ lm() แบบนี้:
# Fit the model
linear_reg <- lm(price_log ~ .,
data = train_set)
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
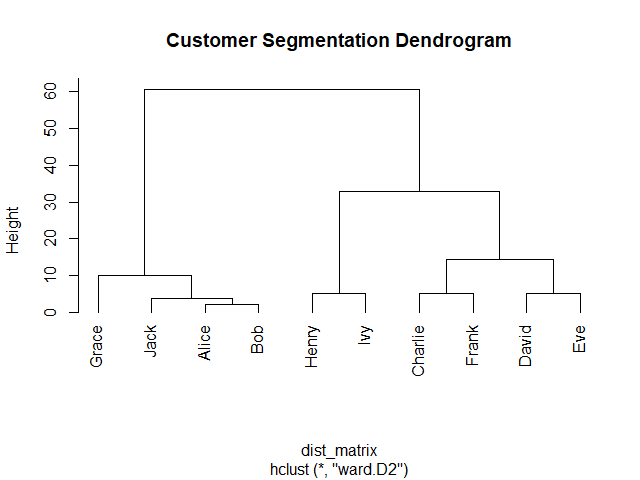
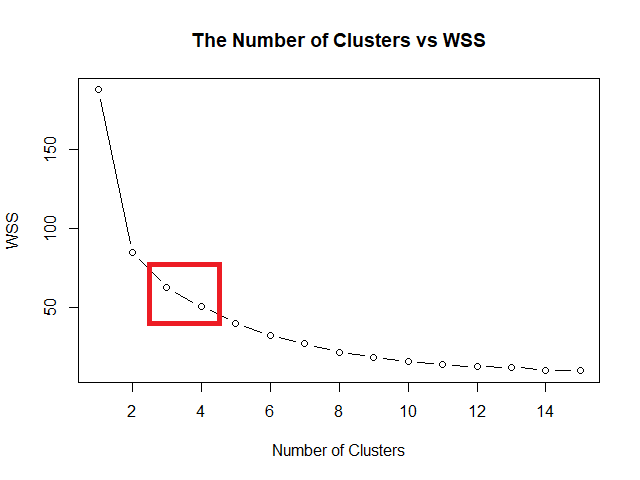
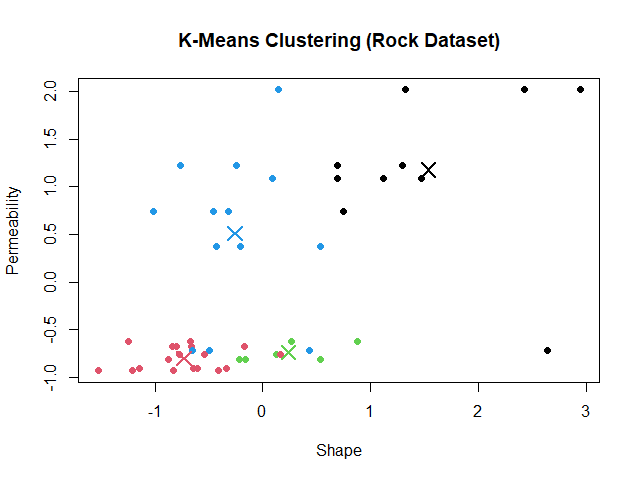
Elbow method หาค่า k ที่ดีที่สุด โดยสร้างกราฟระหว่างค่า k และ within-cluster sum of squares (WSS) หรือระยะห่างระหว่างข้อมูลในกลุ่ม ค่า k ที่ดีที่สุด คือ ค่า k ที่ WSS เริ่มไม่ลดลง
ในภาษา R เราสามารถเริ่มสร้างกราฟได้ โดยเริ่มจากใช้ for loop หา WSS สำหรับช่วงค่า k ที่เราต้องการ
ในตัวอย่าง rock dataset เราจะใช้ช่วงค่า k ระหว่าง 1 ถึง 15:
# Initialise a vector for within cluster sum of squares (wss)
wss <- numeric(15)
# For-loop through the wss
for (k in 1:15) {
## Try the k
km <- kmeans(rock_scaled,
centers = k,
nstart = 20)
## Get WSS for the k
wss[k] <- km$tot.withinss
}
จากนั้น ใช้ plot() สร้างกราฟความสัมพันธ์ระหว่างค่า k และ WSS:
# Plot the wss
plot(1:15,
wss,
type = "b",
main = "The Number of Clusters vs WSS",
xlab = "Number of Clusters",
ylab = "WSS")
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
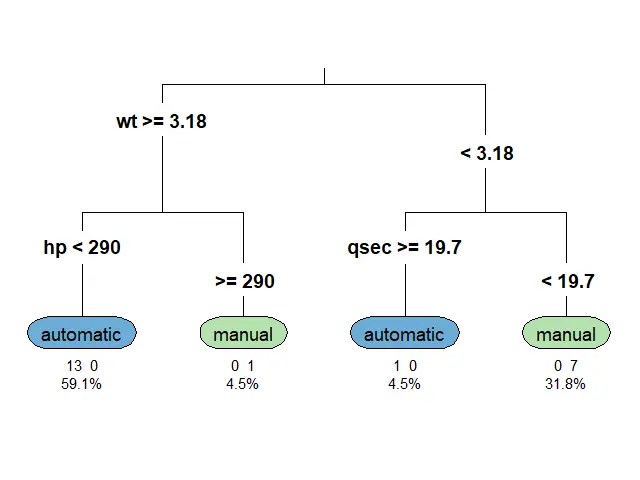
ก่อนนำ mtcars ไปใช้สร้าง classification tree เราจะต้องทำ 2 อย่างก่อน:
อย่างที่ #1. ปรับ column am ให้เป็น factor เพราะสิ่งที่เราต้องการทำนายเป็น categorical data:
# Convert `am` to factor
mtcars$am <- factor(mtcars$am,
levels = c(0, 1),
labels = c("automatic", "manual"))
# Check the result
class(mtcars$am)
ผลลัพธ์:
[1] "factor"
อย่างที่ #2. Split ข้อมูลเป็น 2 ชุด:
Training set สำหรับสร้าง model
Test set สำหรับประเมิน model
# Set seed for reproducibility
set.seed(500)
# Get training index
train_index <- sample(nrow(mtcars),
nrow(mtcars) * 0.7)
# Split the data
train_set <- mtcars[train_index, ]
test_set <- mtcars[-train_index, ]
.
🪴 Train the Model
ตอนนี้ เราพร้อมที่จะสร้าง classification tree ด้วย rpart() แล้ว
สำหรับ classification tree ในบทความนี้ เราจะลองตั้งเงื่อนไขในการปลูกต้นไม้ (control) ดังนี้:
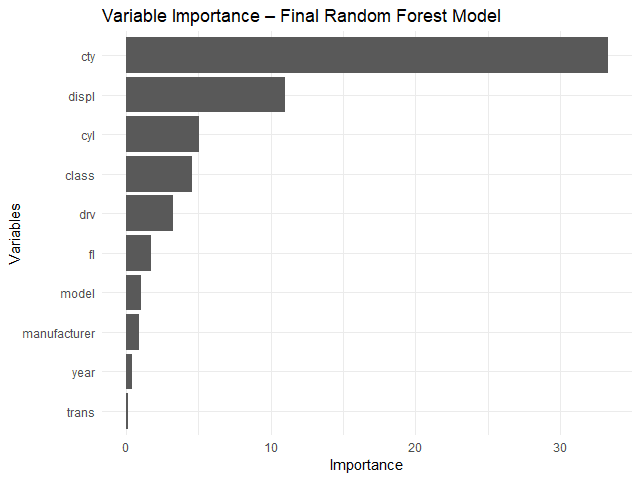
Random forest เป็น tree-based algorithm ที่ช่วยเพิ่มความแม่นยำในการทำนาย โดยสุ่มสร้าง decision trees ต้นเล็กขึ้นมาเป็นกลุ่ม (forest) แทนการปลูก decision tree ต้นเดียว
Decision tree แต่ละต้นใน random forest มีความสามารถในการทำนายแตกต่างกัน ซึ่งบางต้นอาจมีความสามารถที่น้อยมาก
แต่จุดแข็งของ random forest อยู่ที่จำนวน โดย random forest ทำนายผลลัพธ์โดยดูจากผลลัพธ์ในภาพรวม ดังนี้:
Task
Predict by
Regression
ค่าเฉลี่ยของผลลัพธ์การทำนายของทุกต้น
Classification
เสียงส่วนมาก (majority vote)
ดังนั้น แม้ว่า decision tree บางต้นอาจทำนายผิดพลาด แต่โดยรวมแล้ว random forest มีโอกาสที่จะทำนายได้ดีกว่า decision tree ต้นเดียว
ในภาษา R เราสามารถสร้าง random forest ได้ด้วย randomForest() จาก randomForest package ซึ่งต้องการ 3 arguments:
randomFrest(formula, data, ntree)
formula = สูตรในการวิเคราะห์ (ตัวแปรตาม ~ ตัวแปรต้น)
data = dataset ที่ใช้สร้าง model
ntree = จำนวน decision trees ที่ต้องการสร้าง
Note:
เราไม่ต้องกำหนดว่า จะทำ classification หรือ regression model เพราะ randomForest() จะเลือก model ให้อัตโนมัติตามข้อมูลที่เราใส่เข้าไป
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
Correlation
t-tests
ANOVA
Reliability
Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ