ในการทำ machine learning (ML) ในภาษา R เรามี packages และ functions ที่หลากหลายให้เลือกใช้งาน ซึ่งแต่ละ package และ function มีวิธีใช้งานที่แตกต่างกันไป
ยกตัวอย่างเช่น:
glm() จาก base R สำหรับสร้าง regression models ต้องการ input 3 อย่าง คือ formula, data, และ family:
glm(formula, data, family)knn() จาก class package สำหรับสร้าง KNN model ต้องการ input 4 อย่าง คือ ตัวแปรต้นของ training set, ตัวแปรต้นของ test set, ตัวแปรตามของ training set, และค่า k:
knn(train_x, test_x, train_y, k)rpart() จาก rpart package สำหรับสร้าง decision tree model ต้องการ input 2 อย่าง คือ formula และ data:
rpart(formula, data)…
การใช้งาน function ที่แตกต่างกันทำให้การสร้าง ML models เกิดความซับซ้อนโดยไม่จำเป็น และทำให้เกิดความผิดพลาดในการทำงานได้ง่าย
tidymodels เป็น package ที่ถูกออกแบบมาเพื่อแก้ปัญหานี้โดยเฉพาะ
tidymodels เป็น meta-package หรือ package ที่รวบรวม packages อื่นเอาไว้ เมื่อเราโหลด tidymodels เราจะสามารถใช้งาน 8 packages ที่ออกแบบมาให้ทำงานร่วมกัน ช่วยให้เราทำงาน ML ได้ครบ loop
ทั้ง 8 packages ใน tidymodels ได้แก่:
| No. | Package | ML Phase | For |
|---|---|---|---|
| 1 | rsample | Pre-processing | Data resampling |
| 2 | recipes | Pre-processing | Feature engineering |
| 3 | parsnip | Modelling | Model fitting |
| 4 | tune | Post-processing | Hyperparameter tuning |
| 5 | dials | Post-processing | Hyperparameter tuning |
| 6 | yardstick | Post-processing | Model evaluation |
| 7 | broom | Post-processing | Format ผลลัพธ์ให้ดูง่าย |
| 8 | workflow | All | รวม pre-processing, modeling, and post-processing ให้เป็น pipeline เดียวกัน |
ในบทความนี้ เราจะมาดูวิธีใช้ tidymodels เพื่อสร้าง ML models กัน
ถ้าพร้อมแล้ว ไปเริ่มกันเลย
- 🔢 Dataset
- 🛩️ tidymodels
- 🥐 Method #1. Standard Flow
- 🍰 Method #2. Workflow
- 🍩 Bonus: Hyperparametre Tuning
- 😎 Summary
- 📚 Further Reading
- 💪 Example Project
- 😺 GitHub
- 📃 References
- ✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
🔢 Dataset
.
🏠 Boston
ในบทความนี้ เราจะใช้ Boston dataset จาก MASS package เป็นตัวอย่างในการทำงานกับ tidymodels กัน
Boston เป็นชุดข้อมูลบ้านในเมืองบอสตัน รัฐแมสซาชูเซส ประเทศอเมริกา และมีข้อมูลทั้งหมด 14 columns ดังนี้:
| No. | Column | Description |
|---|---|---|
| 1 | crim | ระดับอาชญากรรมในแต่ละเขต |
| 2 | zn | สัดส่วนพื้นที่อาศัย |
| 3 | indus | สัดส่วนธุรกิจที่เป็น non-retail ในแต่ละเขต |
| 4 | chas | เป็นพื้นที่ติดกับ Charles River ไหม (1 = ติด, 0 = ไม่ติด) |
| 5 | nox | ระดับ nitrogen oxide |
| 6 | rm | จำนวนห้องโดยเฉลี่ย |
| 7 | age | สัดส่วย unit ที่มีคนเข้าอยู่ ซึ่งถูกสร้างก่อนปี ค.ศ. 1940 |
| 8 | dis | ระยะทางจากพื้นที่ทำงานในเมืองบอสตัน |
| 9 | rad | ระดับการเข้าถึง radial highways |
| 10 | tax | ภาษีโรงเรือน |
| 11 | ptratio | สัดส่วนนักเรียนต่อครูในแต่ละเขต |
| 12 | black | สัดส่วนผู้อยู่อาศัยที่เป็นคนผิวดำ |
| 13 | lstat | สัดส่วนของประชากรที่มีฐานะยากจน |
| 14 | medv | ราคากลางของบ้านที่มีผู้อยู่อาศัย |
Note: อ่านรายละเอียดเพิ่มเติมเกี่ยวกับ Boston dataset ได้ที่ A Complete Guide to the Boston Dataset in R
จุดประสงค์ของเราในการทำงานกับ Boston dataset คือ ทำนายราคาบ้าน (medv)
.
⬇️ Get Boston
ในการใช้งาน Boston เราสามารถเรียกใช้งานได้ผ่าน MASS package ดังนี้:
- ติดตั้ง MASS package
- โหลด MASS package
- โหลด Boston
# Install package
install.packages("MASS")
# Load package
library(MASS)
# Load dataset
data(Boston)
.
🧹 Prepare Boston
ก่อนเริ่มใช้งาน Boston เราจะต้องปรับประเภทข้อมูลของ chas จาก numeric เป็น factor ก่อน ดังนี้:
# Create a new dataset
bt <- Boston
# Convert `chas` to factor
bt$chas <- factor(bt$chas,
levels = c(1, 0),
labels = c("tract bounds river", "otherwise"))
# Preview
head(Boston)
ผลลัพธ์:
crim zn indus chas nox rm age dis rad tax ptratio black lstat medv
1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98 24.0
2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14 21.6
3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03 34.7
4 0.03237 0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94 33.4
5 0.06905 0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 396.90 5.33 36.2
6 0.02985 0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21 28.7
เราสามารถเช็กผลลัพธ์ได้ด้วย str():
# Check results
str(bt)
ผลลัพธ์:
'data.frame': 506 obs. of 14 variables:
$ crim : num 0.00632 0.02731 0.02729 0.03237 0.06905 ...
$ zn : num 18 0 0 0 0 0 12.5 12.5 12.5 12.5 ...
$ indus : num 2.31 7.07 7.07 2.18 2.18 2.18 7.87 7.87 7.87 7.87 ...
$ chas : Factor w/ 2 levels "tract bounds river",..: 2 2 2 2 2 2 2 2 2 2 ...
$ nox : num 0.538 0.469 0.469 0.458 0.458 0.458 0.524 0.524 0.524 0.524 ...
$ rm : num 6.58 6.42 7.18 7 7.15 ...
$ age : num 65.2 78.9 61.1 45.8 54.2 58.7 66.6 96.1 100 85.9 ...
$ dis : num 4.09 4.97 4.97 6.06 6.06 ...
$ rad : int 1 2 2 3 3 3 5 5 5 5 ...
$ tax : num 296 242 242 222 222 222 311 311 311 311 ...
$ ptratio: num 15.3 17.8 17.8 18.7 18.7 18.7 15.2 15.2 15.2 15.2 ...
$ black : num 397 397 393 395 397 ...
$ lstat : num 4.98 9.14 4.03 2.94 5.33 ...
$ medv : num 24 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 ...
ตอนนี้ ทุก column มีข้อมูลถูกประเภทแล้ว เราพร้อมที่จะใช้ Boston กับ tidymodels แล้ว
🛩️ tidymodels
.
🏁 Getting Started
ในการเริ่มใช้งาน tidymodels เราต้องติดตั้งและโหลด package ก่อน
ติดตั้ง (ทำครั้งแรกครั้งเดียว):
# Install
install.packages("tidymodels")
โหลด (ทำทุกครั้งที่เริ่ม session ใหม่):
# Load
library(tidymodels)
.
🌊 Flows
การใช้งาน tidymodels แบ่งเป็น 2 แบบ:
- Standard flow: เขียน code ยาวกว่า เหมาะกับการทำงานที่เราต้องการควบคุมการทำงานแต่ละขั้นด้วยตัวเอง
- Workflow: เขียน code สั้นกว่า เหมาะกับการสร้าง ML model อย่างรวดเร็ว
เราไปดูวิธีเขียนแต่ละแบบกัน
🥐 Method #1. Standard Flow

สำหรับการใช้งาน tidymodels แบบ standard flow มีทั้งหมด 7 ขั้นตอน ได้แก่:
- Split the data
- Create a recipe
- Prep and bake
- Instantiate a model
- Fit the model
- Make predictions
- Evaluate the model
.
1️⃣ Split the Data
ในขั้นแรก เราจะแบ่ง dataset ออกเป็น 2 ชุด ได้แก่:
- Training set สำหรับสร้าง model
- Test set สำหรับทดสอบ model
โดยเราจะใช้ 3 functions จาก tidymodels ช่วย ได้แก่:
| No. | Function | For |
|---|---|---|
| 1 | initial_split() | กำหนดการแบ่ง dataset |
| 2 | training() | สร้าง training set |
| 3 | testing() | สร้าง test set |
ซึ่งเราเรียกใช้งานได้ดังนี้:
# Set seed for reproducibility
set.seed(2025)
# Define the training set index
bt_split <- initial_split(data = bt,
prop = 0.8,
strata = medv)
# Create the training set
bt_train <- training(bt_split)
# Create the test set
bt_test <- testing(bt_split)
.
2️⃣ Create a Recipe
ในขั้นที่สอง เราจะสร้าง recipe หรือสูตรในการเตรียมข้อมูลกัน
ในขั้นนี้ tidymodels มี 2 functions หลักให้เราใช้งาน ได้แก่:
| No. | Function | For |
|---|---|---|
| 1 | recipe() | กำหนดความสัมพันธ์ระหว่างตัวแปรต้นและตัวแปรตาม |
| 2 | step_*() | data cleaning และ feature engineering |
ซึ่งเราเรียกใช้งานได้ดังนี้:
# Create a recipe
rec <- recipe(medv ~ .,
data = bt_train) |>
## Remove near-zero variance predictors
step_nzv(all_numeric_predictors()) |>
## Handle multicollinearity
step_corr(all_numeric_predictors(),
threshold = 0.8)
ในตัวอย่าง เราใช้:
recipe()กำหนดตัวแปรตาม (medv) และตัวแปรต้น (ตัวแปรที่เหลือทั้งหมด)step_nzv()ลบตัวแปรต้นที่มี variance เข้าใกล้ 0step_corr()จัดการกับ multicollinearity
ศึกษาการใช้งาน step_*() อื่น ๆ ในการเตรียมข้อมูลได้ที่ tidymodels.org – Search recipe steps
.
3️⃣ Prep & Bake
ในขั้นที่ 3 เราจะจัดเตรียมข้อมูลตาม recipe ที่กำหนด โดยเราจะใช้งาน 2 functions ได้แก่:
| No. | Function | For |
|---|---|---|
| 1 | prep() | เตรียม recipe |
| 2 | bake() | เตรียมข้อมูลตาม recipe |
โดยเราแบ่งการทำงานเป็น 3 ขั้นตอน คือ:
- เตรียม recipe ด้วย
prep() - เตรียม training data ด้วย
bake() - เตรียม test data ด้วย
bake()
# Prepare the recipe
rec_prep <- prep(rec,
data = bt_train)
# Bake the training set
bt_train_baked <- bake(rec_prep,
new_data = NULL)
# Bake the test set
bt_test_baked <- bake(rec_prep,
new_data = bt_test)
.
4️⃣ Instantiate a Model
ในขั้นที่ 4 เราจะเรียกใช้ algorithm สำหรับ model ของเรา โดยในตัวอย่าง เราจะลองสร้าง decision tree กัน
ในขั้นนี้ เรามี 3 functions จะเรียกใช้งาน ได้แก่:
| No. | Function | For |
|---|---|---|
| 1 | decision_tree() | สร้าง decision tree * |
| 2 | set_engine() | กำหนด engine หรือ package ที่ใช้สร้าง model |
| 3 | set_mode() | กำหนดประเภท model (classification หรือ regression) |
- Function นี้จะเปลี่ยนตาม model ที่ต้องการ โดยเราสามารถค้นหา model ที่ต้องการได้ที่ tidymodels.org – Search parsnip models
# Instantiate the model
dt_mod <- decision_tree() |>
# Set the engine
set_engine("rpart") |>
# Set the mode
set_mode("regression")
ในตัวอย่าง เราใช้:
set_engine()เลือกrpartเป็น engine ในการสร้าง decision treeset_mode()กำหนด mode เป็น regression เพราะเราต้องการทำนายราคาบ้านซึ่งเป็น continuous variable
.
5️⃣ Fit the Model
ในขั้นที่ 5 เราจะ train model ด้วย training set ผ่าน fit():
dt_mod_fit <- fit(dt_mod,
medv ~ .,
data = bt_train_baked)
ตอนนี้ เราก็จะได้ model ที่พร้อมใช้งานมาแล้ว
.
6️⃣ Make Predictions
ในขั้นที่ 6 เราจะใช้ model ทำนายข้อมูลเพื่อนำไปทดสอบความสามารถในขั้นที่ 7 ต่อไป
ในขั้นนี้ เราจะใช้ predict() ร่วมกับ bind_cols() เพื่อเก็บผลลัพธ์การทำนายเอาไว้:
# Make predictions
dt_results <- predict(dt_mod_fit,
new_data = bt_test_baked,
type = "numeric") |>
bind_cols(actual = bt_test_baked$medv)
# Print the results
dt_results
ผลลัพธ์:
# A tibble: 103 × 2
.pred actual
<dbl> <dbl>
1 34.6 34.7
2 34.6 33.4
3 11.8 16.5
4 17.2 15.6
5 27.3 30.8
6 21.7 25
7 34.6 35.4
8 21.7 21.2
9 27.3 23.9
10 44.3 43.8
# ℹ 93 more rows
# ℹ Use `print(n = ...)` to see more rows
.
7️⃣ Evaluate the Model
ในขั้นสุดท้าย เราจะวิเคราะห์ความสามารถของ model กัน
tidymodels มี functions สำหรับคำนวณค่าตัวชี้วัดต่าง ๆ เช่น:
| Function | For |
|---|---|
accuracy() | ความแม่นยำในการทำนาย |
roc_auc() | ความสมดุลในการทำนาย |
Note: ศึกษา functions ทั้งหมดได้ที่ tidymodels.org – Metric types
สำหรับบทความนี้ เราจะเลือกใช้ 2 functions ได้แก่:
| No. | Function | For |
|---|---|---|
| 1 | mae() | Mean absolute error |
| 2 | rmse() | Root mean squared error |
โดยเราเรียกใช้งาน functions ได้ 2 แบบ ดังนี้:
แบบที่ 1. เรียกใช้ด้วยตัวเอง:
# Calculate MAE
dt_mae <- mae(dt_results,
truth = actual,
estimate = .pred)
# Calculate RMSE
dt_rmse <- rmse(dt_results,
truth = actual,
estimate = .pred)
# Print MAE and RMSE
cat("MAE:", round(dt_mae$.estimate, 2), "\\n")
cat("RMSE:", round(dt_rmse$.estimate, 2), "\\n")
ผลลัพธ์:
MAE:
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 mae standard 3.70
------------------------------------------
RMSE:
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 5.13
.
แบบที่ 2. เรียกใช้ผ่าน metric_set() ที่จะรวม functions ไว้ด้วยกัน:
# Define a custom metrics
dt_metrics <- metric_set(mae,
rmse)
# Evaluate the model
dt_eva_results <- dt_metrics(dt_results,
truth = actual,
estimate = .pred)
# Print the results
dt_eva_results
ผลลัพธ์:
# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 mae standard 3.70
2 rmse standard 5.13
จะเห็นได้ว่า แบบที่ 2 สะดวกกว่า เพราะเราสามารถคำนวณค่าตัวชี้วัดหลายตัวได้ในครั้งเดียวกัน
🍰 Method #2. Workflow

เราได้ดูวิธีใช้งานแบบ standard flow ไปแล้ว เรามาดูวิธีใช้ tidymodels แบบ workflow ซึ่งมี 6 ขั้นตอน ดังนี้กัน:
- Split the data
- Create a recipe
- Instantiate the model
- Bundle the recipe and the model
- Fit the model
- Evaluate the model
.
1️⃣ Split the Data
ในขั้นแรก เราจะแบ่ง dataset ออกเป็น 2 ชุด (เหมือนกับ standard flow):
# Set seed for reproducibility
set.seed(2025)
# Define the training set index
bt_split <- initial_split(data = bt,
prop = 0.8,
strata = medv)
# Create the training set
bt_train <- training(bt_split)
จะสังเกตว่า เราจะไม่ได้สร้าง test set ในครั้งนี้
.
2️⃣ Create a Recipe
ในขั้นที่ 2 เราจะสร้าง recipe (เหมือนกับ standard flow):
# Create a recipe
rec <- recipe(medv ~ .,
data = bt_train) |>
## Remove near-zero variance predictors
step_nzv(all_numeric_predictors()) |>
## Handle multicollinearity
step_corr(all_numeric_predictors(),
threshold = 0.8)
.
3️⃣ Instantiate the Model
ในขั้นที่ 3 ของ standard flow เราจะเตรียม recipe และข้อมูลกัน
แต่ใน workflow เราจะสร้าง model (ซึ่งเป็นขั้นที่ 4 ของ standard flow) แทน:
# Instantiate the model
dt_mod <- decision_tree() |>
## Set the engine
set_engine("rpart") |>
## Set the mode
set_mode("regression")
.
4️⃣ Bundle the Recipe and the Model
ในขั้นที่ 4 เราจะรวม recipe และ model เข้าด้วยกัน เพื่อทำให้การทำงานต่อจากนี้ง่ายขึ้น ผ่านการใช้ 3 functions ดังนี้:
| No. | Function | For |
|---|---|---|
| 1 | workflow() | สร้าง workflow object |
| 2 | add_recipe() | เพิ่ม recipe ใน workflow object |
| 3 | add_model() | เพิ่ม model ใน workflow object |
Note: อ่านเพิ่มเติมเกี่ยวกับ workflow object ได้ที่ tidymodels.org – workflows และ Tidy Modeling with R – A Model Workflow
# Bundle the recipe and the model
dt_wfl <- workflow() |>
## Add recipe
add_recipe(rec) |>
## Add model
add_model(dt_mod)
.
5️⃣ Fit the Model
ในขั้นที่ 5 เราจะ train model ด้วย training set โดยเราจะใช้ last_fit() แทน fit()
ทั้งนี้ last_fit() ต้องการ input 3 อย่าง ได้แก่:
| No. | Input | Description |
|---|---|---|
| 1 | object | workflow object |
| 2 | split | object ที่ได้จาก initial_split() |
| 3 | metrics | ตัวชี้วัดที่เก็บไว้ใน metric_set() |
# Fit the model
dt_last_fit <- last_fit(dt_wfl,
split = bt_split,
metrics = metric_set(mae, rmse))
.
6️⃣ Evaluate the Model
นอกจาก train model แล้ว last_fit() ยังทำหน้าที่อีก 2 อย่าง ได้แก่:
- ทำนายข้อมูลจาก model ที่ได้
- ประเมิน model ตามตัวชี้วัดที่กำหนดใน
metric_set()
นั่นหมายคงามว่า last_fit() ได้ให้ผลลัพธ์ในการประเมิน model มาแล้ว เราเพียงแค่ต้องเรียกผลลัพธ์ออกมาแสดงเท่านั้น ซึ่งเราสามารถทำได้ด้วย 2 functions นี้:
| No. | Function | For |
|---|---|---|
| 1 | collect_predictions() | ดึงข้อมูลที่ model ทำนาย |
| 2 | collect_metrics() | ดึงค่าตัวชี้วัดความสามารถของ model |
ดึงผลลัพธ์ในการทำนายได้ด้วย collect_predictions():
# Collect predictions
dt_predictions <- collect_predictions(dt_last_fit)
# Print predictions
dt_predictions
ผลลัพธ์:
# A tibble: 103 × 5
.pred id .row medv .config
<dbl> <chr> <int> <dbl> <chr>
1 34.6 train/test split 3 34.7 Preprocessor1_Model1
2 34.6 train/test split 4 33.4 Preprocessor1_Model1
3 11.8 train/test split 9 16.5 Preprocessor1_Model1
4 17.2 train/test split 25 15.6 Preprocessor1_Model1
5 27.3 train/test split 40 30.8 Preprocessor1_Model1
6 21.7 train/test split 53 25 Preprocessor1_Model1
7 34.6 train/test split 56 35.4 Preprocessor1_Model1
8 21.7 train/test split 79 21.2 Preprocessor1_Model1
9 27.3 train/test split 82 23.9 Preprocessor1_Model1
10 44.3 train/test split 99 43.8 Preprocessor1_Model1
# ℹ 93 more rows
# ℹ Use `print(n = ...)` to see more rows
Note:
.predคือ ราคาที่ทำนายmedvคือ ราคาจริง
.
ดึงตัวบ่งชี้ที่ได้จาก last_fit() ด้วย collect_metrics():
# Collect metrics
dt_metrics <- collect_metrics(dt_last_fit)
# Print metrics
dt_metrics
ผลลัพธ์:
# A tibble: 2 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 mae standard 3.70 Preprocessor1_Model1
2 rmse standard 5.13 Preprocessor1_Model1
จะเห็นได้ว่า แม้ workflow จะมีจำนวนขั้นตอนใกล้เคียงกับ standard flow แต่การทำงานแบบ workflow มีความสะดวกกว่ามาก
🍩 Bonus: Hyperparametre Tuning

ส่งท้าย เรามาดูวิธีใช้ tidymodels เพื่อทำ hyperparametre tuning ใน 5 ขั้นตอนกัน:
- Prepare
- Tune
- Select
- Fit
- Evaluate
.
1️⃣ Prepare
ในการทำ hyperparametre tuning เราสามารถเขียนได้ทั้งแบบ standard flow และ workflow
ในบทความนี้ เราจะดูวิธีทำแบบ workflow ซึ่งเป็นวิธีที่ง่ายกว่ากัน
ในขั้นแรก เราต้องเตรียมของสำหรับ hyperparametre tuning 4 ข้อ ได้แก่:
| No. | Input | Description |
|---|---|---|
| 1 | object | workflow object ที่รวม recipe และ model เอาไว้ |
| 2 | resamples | การแบ่ง training set เพื่อทดสอบ hyperparametres |
| 3 | grid | การจับคู่ hyperparametres |
| 4 | metrics | ตัวชี้วัดที่ต้องการใช้ประเมิน hyperparametres |
ข้อที่ 1. เตรียม object
เราเริ่มจากแบ่งข้อมูล:
# Set seed for reproducibility
set.seed(2025)
# Define the training set index
bt_split <- initial_split(data = bt,
prop = 0.8,
strata = medv)
# Create the training set
bt_train <- training(bt_split)
สร้าง recipe:
# Create a recipe
rec <- recipe(medv ~ .,
data = bt_train) |>
## Remove near-zero variance predictors
step_nzv(all_numeric_predictors()) |>
## Handle multicollinearity
step_corr(all_numeric_predictors(),
threshold = 0.8)
จากนั้น เรียกใช้ model โดยเราจะต้องกำหนด hyperparametre ที่ต้องการปรับ ด้วย tune():
# Define the tuning parameters
dt_model_tune <- decision_tree(cost_complexity = tune(),
tree_depth = tune(),
min_n = tune()) |>
## Set engine
set_engine("rpart") |>
## Set mode
set_mode("regression")
สุดท้าย เรารวม recipe และ model ไว้ใน workflow object:
# Define the workflow with tuning
bt_wfl_tune <- workflow() |>
## Add recipe
add_recipe(rec) |>
## Add model
add_model(dt_model_tune)
ข้อที่ 2. Resamples ซึ่งในที่นี้ เราจะใช้ k-fold cross-validation ที่แบ่ง training set ออกเป็น 5 ส่วน (4 ส่วนเพื่อ train และ 1 ส่วนเพื่อ test) แบบนี้:
# Set k-fold cross-validation for tuning
hpt_cv <- vfold_cv(bt_train,
v = 5,
strata = medv)
ข้อที่ 3. Grid ซึ่งเราจะใช้การจับคู่แบบสุ่มผ่าน grid_random():
# Set seed for reproducibility
set.seed(2025)
# Define the grid for tuning
hpt_grid <- grid_random(cost_complexity(range = c(-5, 0), trans = log10_trans()),
tree_depth(range = c(1, 20)),
min_n(range = c(2, 50)),
size = 20)
ข้อที่ 4. Metrics ซึ่งเราต้องเก็บไว้ใน metric_set():
# Define metrics
hpt_metrics = metric_set(mae,
rmse)
.
2️⃣ Tune
หลังจากเตรียม input ครบแล้ว เราสามารถ tune model ได้ด้วย tune_grid():
# Tune the model
dt_tune_results <- tune_grid(bt_wfl_tune,
resamples = hpt_cv,
grid = hpt_grid,
metrics = hpt_metrics)
.
3️⃣ Select
หลังจาก tune แล้ว เราสามารถดูค่า hyperparametres ที่ดีที่สุดตามตัวบ่งชี้ที่เราเลือกได้ด้วย show_best()
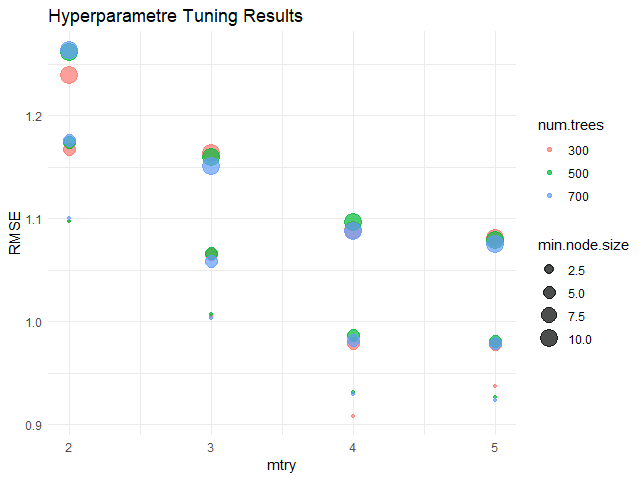
โดยในตัวอย่าง เราจะลองเลือก hyperparametres ที่ดีที่สุด 5 ชุดแรก โดยดูจาก RMSE:
# Show the best model
show_best(dt_tune_results,
metric = "rmse",
n = 5)
ผลลัพธ์:
# A tibble: 5 × 9
cost_complexity tree_depth min_n .metric .estimator mean n
<dbl> <int> <int> <chr> <chr> <dbl> <int>
1 0.00311 3 5 rmse standard 4.55 5
2 0.0167 16 12 rmse standard 4.70 5
3 0.00150 5 28 rmse standard 4.75 5
4 0.0000436 18 14 rmse standard 4.88 5
5 0.0000345 11 39 rmse standard 4.88 5
# ℹ 2 more variables: std_err <dbl>, .config <chr>
จากนั้น เราสามารถเลือกค่า hyperparametres ที่ดีที่สุดได้ด้วย select_best():
# Select the best model
dt_best_params <- select_best(dt_tune_results,
metric = "rmse")
.
4️⃣ Fit
ในขั้นที่ 4 เราจะใส่ค่า hyperparametres ที่เลือกมาเข้าไปใน workflow object ผ่าน finalize_workflow():
# Finalise the best workflow
dt_wkl_best <- finalize_workflow(bt_wfl_tune,
dt_best_params)
จากนั้น train model ด้วย last_fit():
# Fit the best model
dt_best_fit <- last_fit(dt_wkl_best,
split = bt_split,
metrics = metric_set(mae, rmse))
.
5️⃣ Evaluate
สุดท้าย เราจะทดสอบ model ด้วย collect_predictions() และ collect_metrics():
# Collect predictions
predictions_best <- collect_predictions(dt_best_fit)
# Print predictions
predictions_best
ผลลัพธ์:
# A tibble: 103 × 5
.pred id .row medv .config
<dbl> <chr> <int> <dbl> <chr>
1 32.3 train/test split 3 34.7 Preprocessor1_Model1
2 32.3 train/test split 4 33.4 Preprocessor1_Model1
3 11.8 train/test split 9 16.5 Preprocessor1_Model1
4 17.2 train/test split 25 15.6 Preprocessor1_Model1
5 22.6 train/test split 40 30.8 Preprocessor1_Model1
6 22.6 train/test split 53 25 Preprocessor1_Model1
7 32.3 train/test split 56 35.4 Preprocessor1_Model1
8 22.6 train/test split 79 21.2 Preprocessor1_Model1
9 22.6 train/test split 82 23.9 Preprocessor1_Model1
10 34.5 train/test split 99 43.8 Preprocessor1_Model1
# ℹ 93 more rows
# ℹ Use `print(n = ...)` to see more rows
และ
# Collect metrics
metrics_best <- collect_metrics(dt_best_fit)
# Print metrics
metrics_best
ผลลัพธ์:
# A tibble: 2 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 mae standard 3.48 Preprocessor1_Model1
2 rmse standard 4.68 Preprocessor1_Model1
จะเห็นว่า hyperparametre tuning ทำให้ model ของเรามีประสิทธิภาพมากขึ้น เพราะมี MAE (3.70 vs 3.48) และ RMSE (5.13 vs 4.68) ที่ลดลง
😎 Summary
ในบทความนี้ เราได้ดูวิธีสร้าง ประเมิน และปรับ ML model ด้วย tidymodels ซึ่ง functions ต่าง ๆ ที่เราได้เรียนรู้สรุปตาม ML phase ได้ดังนี้:
Pre-processing:
| Function | Description |
|---|---|
initial_split() | แบ่งข้อมูล |
training() | สร้าง training set |
testing() | สร้าง test set |
recipe() | กำหนดตัวแปรต้น ตัวแปรตาม |
step_*() | กำหนดขั้นการแปลงข้อมูล |
prep() | เตรียม recipe |
bake() | เตรียมข้อมูล |
Modelling:
| Function | Description |
|---|---|
decision_tree() | สร้าง decision tree |
set_engine() | เรียกใช้ ML engine |
set_mode() | กำหนดประเภท model |
fit() | train model |
last_fit() | train, ทำนาย, และประเมิน model |
Post-processing:
| Function | Description |
|---|---|
mae() | คำนวณ MAE |
rmse() | คำนวณ RMSE |
metric_set() | กำหนดชุดตัวชี้วัด |
collect_predictions() | เรียกดูคำทำนาย |
collect_metrics() | เรียกดูตัวชี้วัด |
tune() | กำหนด hyperparametres ที่ต้องการ tune |
vfold_cv() | สร้าง k-fold cross-validation |
grid_random() | สุ่มสร้างค่า hyperparametres ที่ต้องการทดสอบ |
tune_grid() | tune model |
All:
| Function | Description |
|---|---|
workflow() | รวม recipe และ model ไว้ด้วยกัน |
📚 Further Reading
สำหรับคนที่สนใจ สามารถศึกษาเกี่ยวกับ tidymodels เพิ่มเติมได้ที่:
💪 Example Project
ดูตัวอย่างการใช้งาน tidymodels เพื่อสำหรับ data analytics project ได้ที่ Exploring & Predicting Employee Attrition With Machine Learning in R
😺 GitHub
ดู code ทั้งหมดในบทความนี้ได้ที่ GitHub:
📃 References
- Modeling with tidymodels in R (DataCamp)
- Modeling with tidymodels in R (RPubs)
- Machine Learning with Tree-Based Models in R
✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
📕 ขอฝากหนังสือเล่มแรกในชีวิตด้วยนะครับ 😆
🙋 ใครที่กำลังเรียนจิตวิทยาหรือทำงานสายจิตวิทยา และเบื่อที่ต้องใช้ software ราคาแพงอย่าง SPSS และ Excel เพื่อทำข้อมูล
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
- Correlation
- t-tests
- ANOVA
- Reliability
- Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
แล้วทุกคนจะแปลกใจว่า ทำไมภาษา R ง่ายขนาดนี้ 🙂↕️
👉 สนใจดูรายละเอียดหนังสือได้ที่ meb: