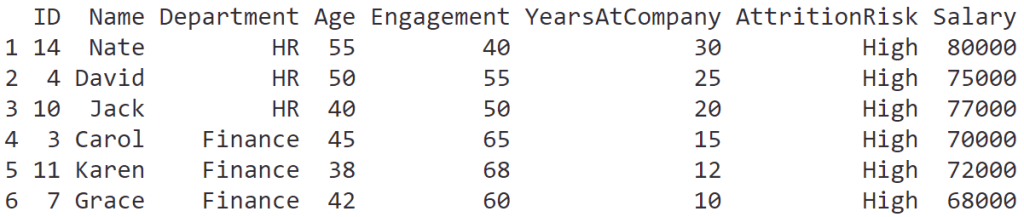ในบทความนี้ ผมจะมาสรุปเนื้อหาจาก workshop “Compassionate Leadership in the Age of AI” ของคุณดามพ์ (มงคล หงษ์ชัย) ผู้เชี่ยวชาญ agile leadership และ AI for future skills ในงาน PMAT 60th เมื่อวันที่ 12 พ.ย. ที่ผ่านมา
โดยเนื้อหาจะแบ่งเป็น 3 ส่วน ได้แก่:
- Issues with AI adoption: ปัญหาการพัฒนา AI solution
- Compassion: เครื่องมือทำความเข้าใจคน
- DEMO: เครื่องมือทำความเข้าใจ process
ถ้าพร้อมแล้ว ไปเริ่มกันเลย
- 😭 The Issue With AI Solutions
- 🫂 Compassion: Tool for Understanding the People
- 🦾 DEMO: Tool for Understanding Process
- 💪 Summary
- 📚 Further Reading
😭 The Issue With AI Solutions
95% ขององค์กรล้มเหลวในการสร้าง AI solution ที่สร้างกำไรได้จริง (The GenAI Divide: State of AI in Business 2025)
สาเหตุหลักของความล้มเหลวมีอยู่ 2 ข้อ ได้แก่:
- People: ขาดความเข้าใจในผู้ที่เกี่ยวข้องกับการเปลี่ยนแปลง (เช่น พนักงานที่ต้องใช้ AI)
- Process: ขาดความเข้าใจใน process งานที่นำ AI มาประยุกต์ใช้
ซึ่งทำให้ AI solution ที่ออกแบบไม่ตอบโจทย์คนใช้งานและไม่สามารถสร้างรายได้ให้กับองค์กรได้
เราสามารถแก้ทั้ง 2 สาเหตุนี้ได้ด้วย 2 เครื่องมือนี้:
- Compassion: ช่วยทำความเข้าใจคน
- DEMO: ช่วยทำความเข้าใจ process
🫂 Compassion: Tool for Understanding the People
.
❤️ Empathy
ถ้าเราจะเข้าใจคนอื่นได้ เราจะต้องมี empathy
Empathy เป็นคำที่มีคนพูดถึงอยู่บ่อย ๆ โดยเฉพาะในองค์กรที่ทำงานกับ design thinking ซึ่งใช้ empathy เป็นเครื่องมือหลักในการทำความเข้าใจปัญหาของ user เพื่อออกแบบ solution ที่ตอบโจทย์ user อย่างแท้จริง
Empathy ยังเป็น 1 ใน 4 ลักษณะสำคัญของ leader ในยุค VUCA (volatile, uncertain, complex, ambiguous) เคียงข้างกับ problem solving, relationship management, และ motivation อีกด้วย
Empathy เป็นสิ่งจำเป็น เพราะทำให้เราเข้าใจความรู้สึกและมุมมองของคนอื่นได้ เพราะ leader ที่ไม่มี empathy จะไม่สามารถ engage คนอื่นได้ เพราะไม่สามารถสร้าง motivation ให้กับคนอื่นได้ (Connect with Empathy, But Lead with Compassion)
แต่ empathy อย่างเดียวอาจไม่พอ และสิ่งที่เราต้องการจริง ๆ คือ compassion
.
🫂 Compassion
ในขณะที่ empathy ช่วยให้เรารับรู้ความรู้สึกและมุมมองของคนอื่น compassion ไม่เพียงแต่ช่วยให้เราเข้าถึงความรู้สึกของคนอื่น แต่ยังรวมไปถึงความต้องการที่จะช่วยคนอื่นอีกด้วย
Compassion แปลไทยได้ว่า “กรุณา” ซึ่งหมายถึง การช่วยให้คนอื่นพ้นทุกข์ และคำที่มักมาคู่กัน คือ “เมตตา” ซึ่งแปลว่า การทำให้คนอื่นมีความสุข (Buddhist beliefs – Edexcel)
Empathy เป็นสิ่งจำเป็นที่จะช่วยให้เรา connect กับคนอื่นได้ แต่ถ้าเราจะเป็น leader ที่ดี เราจะต้องมี compassion ด้วย เพราะ empathy อย่างเดียวอาจทำให้เราตัดสินใจผิดพลาดได้ ตามคำของ Paul Polman อดีต CEO ของ Unilever:
If I led with empathy, I would never be able to make a single decision. Why? Because with empathy, I mirror the emotions of others, which makes it impossible to consider the greater good.”
แปล:
ถ้าผมนำด้วย empathy ผมจะตัดสินใจไม่ได้สักอย่าง ทำไมหรอ? เพราะ empathy ทำให้ผมรู้สึกความรู้สึกของคนอื่น ซึ่งทำให้ผมคิดถึงประโยชน์ของส่วนรวมไม่ได้
มีงานวิจัยที่แสดงให้เห็นถึงข้อเสียของ empathy
ในงานวิจัย ผู้เข้าร่วมถูกขอให้เลือกว่า จะลัดคิวเด็กที่ป่วยหนักคนหนึ่งเพื่อให้ได้รับการรักษาก่อนคิวไหม โดยกลุ่มหนึ่งถูกขอให้ฟังและมีความรู้สึกร่วมในขณะที่เด็กเล่าถึงความเจ็บปวดจากโรค และอีกกลุ่มถูกขอให้ฟังโดยไม่ตัดสิน
ผู้เข้าร่วมกลุ่มแรกเลือกที่จะลัดคิวให้เด็กมากกว่าผู้เข้าร่วมในกลุ่มหลัง แม้ว่าผู้เชี่ยวชาญด้านการแพทย์จะคัดค้าน แม้ว่าการตัดสินใจลัดคิวจะเป็นผลดีต่อเด็ก แต่ทำให้ผู้ป่วยอื่น ๆ ที่อาจต้องการการรักษามากกว่าอยู่ในอันตรายได้ (Connect with Empathy, But Lead with Compassion)
ดังนั้น เราไม่ควรมีแต่ empathy แต่ควรมี compassion ด้วย
.
🧘 How to Develop Compassion
เราสามารถพัฒนา compassion ได้ 2 วิธี:
วิธีที่ 1. ฝึกอยู่กับปัจจุบันทั้งกายและใจ
แม้ว่าเวลาคุยกับคนอื่น เราอาจจะคิดว่าเราฟังอยู่ แต่จริง ๆ แล้วใจเราอาจไปอยู่ที่อื่น หรือเสียงในหัวเราอาจจะดังกลบเสียงคนที่กำลังพูด
เราสามารถฝึก compassion ได้โดยกลับมาอยู่กับสิ่งที่เกิดขึ้นในปัจจุบัน ซึ่งจะช่วยให้เราอยู่กับสิ่งที่คนอื่นกำลังพูดได้มากขึ้น
เราสามารถฝึกอยู่กับปัจจุบันได้ผ่านการนั่งสมาธิ หรือง่ายกว่านั้น คือ การสังเกตสิ่งที่กำลังเกิดขึ้นรอบตัวเรา เช่น:
- ลมหายใจเข้าออกของเรา
- ผิวของเนื้อผ้าที่เราสวมใส่
- แอร์หรือลมที่ตกกระทบผิวของเรา
แค่เราฝึกสังเกตสิ่งที่เกิดขึ้นในแต่ละช่วงขณะ เราก็จะค่อย ๆ พัฒนา compassion ของเราขึ้นทีละนิด เพราะเราสามารถอยู่กับคนที่ต้องการความช่วยเหลือจากทั้งกายและใจ
วิธีที่ 2. ให้ AI ช่วย
เราสามารถให้ AI ช่วยพัฒนา compassion ได้ เช่น:
- เล่าสถานการณ์ที่เราพูดคุยกับคนอื่นให้ AI ฟัง เพื่อให้ AI ให้มุมมองใหม่ ๆ กับเรา พร้อมแนะนำวิธีแสดง compassion เพิ่มเติมได้ (Using AI to Make You a More Compassionate Leader)
- ให้ AI ช่วย role-play กับเรา ให้เราได้ฝึก compassion เหมือนในหน้างานจริง
🦾 DEMO: Tool for Understanding Process
.
📊 Why DEMO?
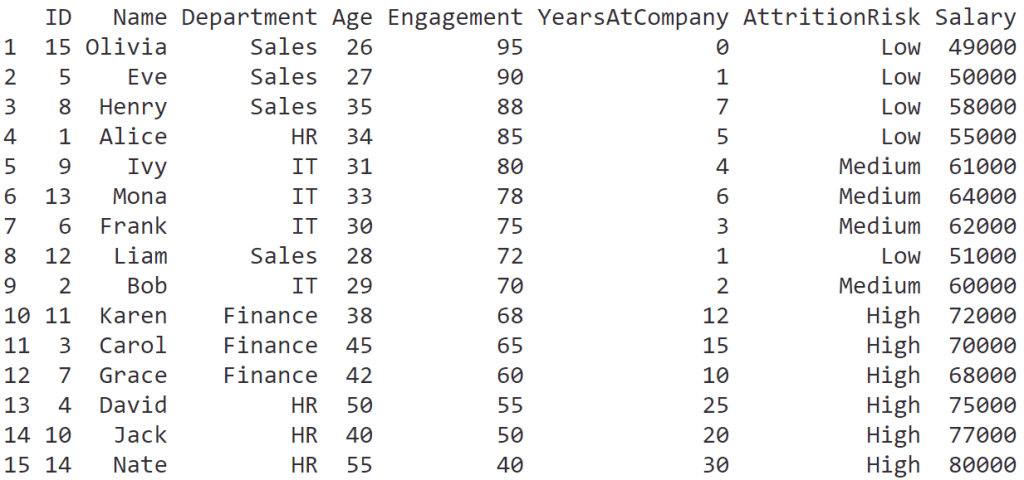
ทุกองค์กรมี chart มากมายสำหรับแสดงข้อมูลต่าง ๆ เช่น flow chart สำหรับแสดงขั้นตอนการทำงานในองค์กร และ organisation chart ที่แสดงผังองค์กร
Chart เหล่านี้ล้วนแสดงข้อมูลเป็นท่อน ๆ นั่นคือ แสดงรายละเอียดภาพย่อย แต่ขาดความเชื่อมโยงระหว่างข้อมูลที่สำคัญต่อการตัดสินใจในระดับบริหาร
ยกตัวอย่างเช่น flow chart แสดงการเบิกจ่ายค่าเดินทางให้พนักงาน:
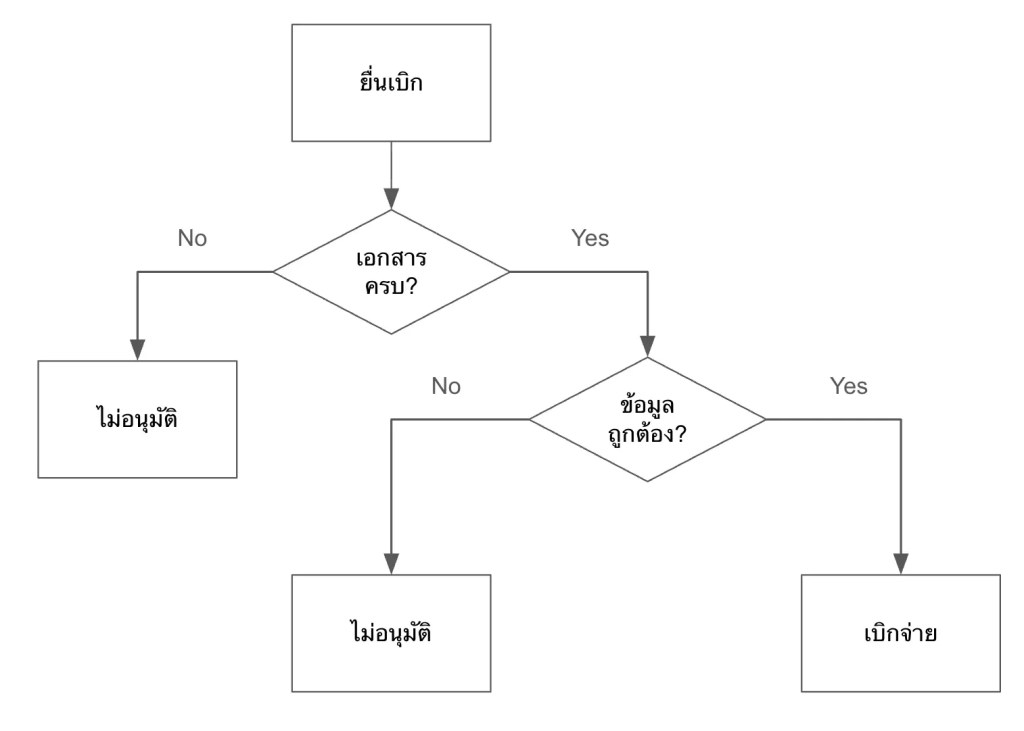
ในรูป เราจะรู้ว่ามีขั้นตอนอะไรบ้างที่จะเกิดขึ้นก่อนพนักงานจะได้รับเงินค่าเดินทาง แต่เราไม่รู้ว่าขั้นตอนเหล่านี้เกี่ยวข้องกับส่วนอื่น ๆ ขององค์กรยังไงบ้าง เช่น:
- แต่ละขั้นตอนมีใครเกี่ยวข้องบ้าง
- มีเอกสารอะไรที่ต้องการใช้บ้าง
- แต่ละขั้นตอนใช้เวลาเท่าไร
ถ้าเราต้องการเห็นภาพรวมของการทำงานในองค์กร เราจะใช้ DEMO
.
👷 What Is DEMO?
DEMO (ย่อมาจาก Design & Engineering Methodology for Organisations) เป็นหลักการในการออกแบบองค์กร ซึ่งมีวิธีการเขียน process ในระดับ high level ที่ช่วยให้ทำความเข้าใจและตัดสินใจได้ง่าย
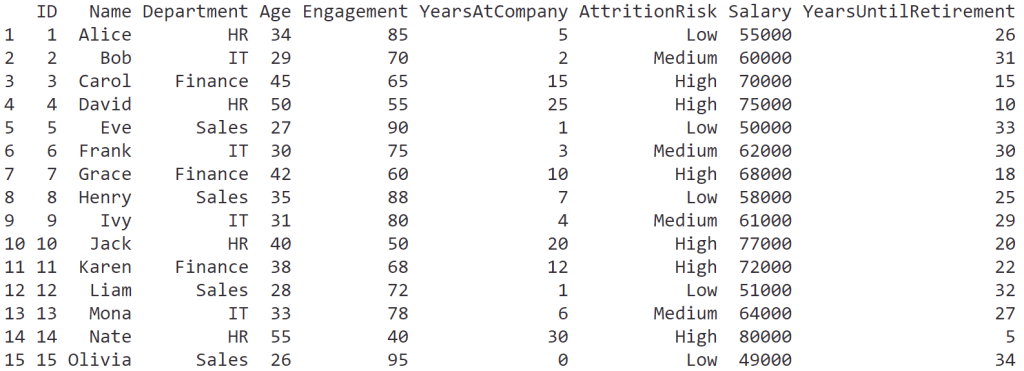
ยกตัวอย่างการเขียน process การเบิกค่าเดินทางแบบ DEMO:
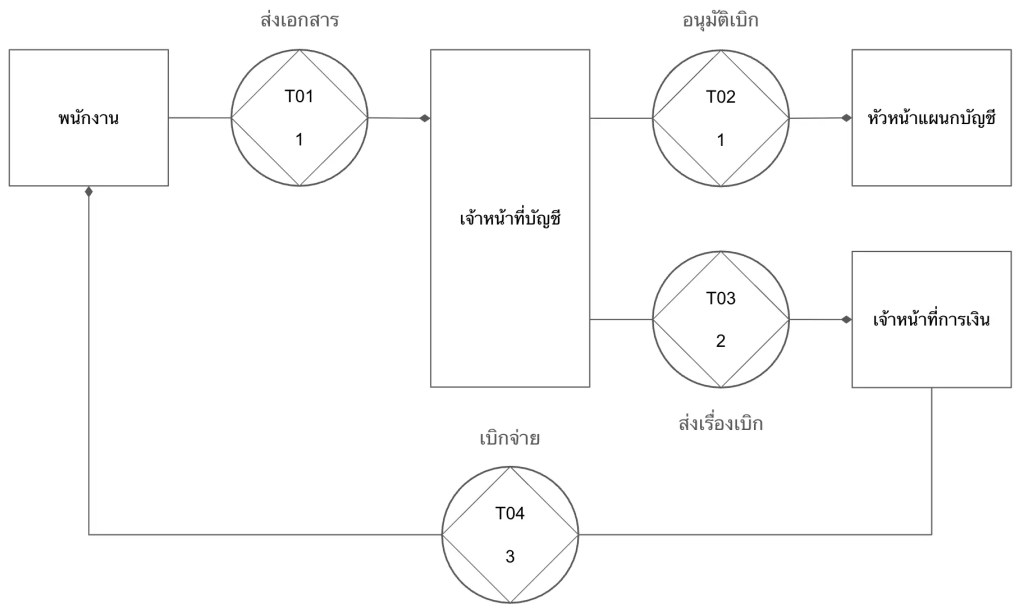
DEMO แสดง process ในรูปแบบของ transaction หรือการแลกเปลี่ยนระหว่าง 2 ฝ่าย ได้แก่:
- Initiator: คนที่เริ่มการแลกเปลี่ยน (เช่น พนักงานที่ขอเบิกค่าเดินทาง)
- Executor: คนที่ทำให้เกิดผลลัพธ์บางอย่างในระบบ (เช่น ฝ่ายบัญชีที่อนุมัติจ่าย)
ในแผนภาพแบบ DEMO (เรียกว่า OCD หรือ Organisation Construction Diagram) เราจะเห็นว่า:
- การเบิกจ่ายเงินมีกี่ transaction (ดูจาก T01, T02, …)
- แต่ละ transaction มีใครที่เกี่ยวข้องบ้าง
- แต่ละ transaction ใช้เวลาเท่าไร (ตัวเลขใต้ T0x เช่น T01 ใช้เวลา 1 วัน)
OCD มาพร้อมกับตารางที่ให้ข้อมูลเพิ่มเติมเกี่ยวกับ transaction เช่น:
| Transaction | Duration | Documents |
|---|---|---|
| T01. ส่งเอกสาร | 1 วัน | ฟอร์มเบิกค่าเดินทาง, หลักฐานการเดินทาง, สำเนาบัตรประชาชน |
| T02. อนุมัติเบิก | 1 วัน | ฟอร์มเบิกค่าเดินทาง, หลักฐานการเดินทาง |
| T03. ส่งเรื่องเบิก | 2 วัน | ฟอร์มเบิกค่าเดินทาง, หลักฐานการเดินทาง |
| T04. เบิกจ่าย | 3 วัน | อีเมลแจ้งการเบิกจ่าย |
เมื่อเราดู OCD และตารางประกอบกัน เราจะสามารถระบุปัญหาและจุดที่ควรแก้ไขได้ในทันที เช่น:
- เราตัดขั้นตอน T03 ออกได้ไหม? ให้ฝ่ายบัญชีจ่ายตรงให้พนักงานเลย
- ทำไม T03 ใช้เวลานาน? ลดเหลือ 1 วันได้ไหม?
- T01 ต้องใช้เอกสาร 3 อย่างเลยหรอ? ตัดสำเนาบัตรประชาชนออกได้หรือเปล่า?
ถ้าเรามองย้อนกลับไปที่ flow chart ก่อนหน้านี้ เราจะเห็นความแตกต่างอย่างชัดเจนว่า เราไม่สามารถตั้งคำถามเหล่านี้ได้ในทันที เพราะ flow chart ไม่ได้ให้ข้อมูลที่เพียงพอหรือจำเป็นต่อการตัดสินใจในการเปลี่ยนแปลง process งาน
ในทางตรงกันข้าม OCD สามารถให้ข้อมูลที่ช่วยให้เราทำความเข้าใจ process และระบุปัญหาที่ควรแก้ไขได้ในทันที
.
🤖 DEMO & AI Solution
เราสามารถนำ DEMO มาประยุกต์ใช้ในการออกแบบ AI solution ให้เหมาะกับองค์กรได้
ยกตัวอย่างเช่น สำหรับการเบิกค่าเดินทาง เราอาจจะอยากพัฒนา AI ขึ้นมาช่วยพนักงานยื่นเอกสารเบิกจ่าย (T01) แต่จะเห็นได้ว่า ถ้าเราทุ่มงบประมาณไปกับการพัฒนา AI ในส่วนนี้ เราจะลดภาระงานไปเพียง 1 วันเท่านั้น
แต่ถ้าเราพัฒนา AI เพื่อมาช่วยฝ่ายบัญชีส่งต่อเอกสารให้กับฝ่ายการเงิน (T03) หรือช่วยฝ่ายการเงินตั้งจ่ายและส่งอีเมลยืนยันการจ่าย (T04) เราจะสามารถลดเวลาได้มากขึ้น เพราะทั้ง 2 จุดนี้ใช้เวลามากที่สุดในขั้นตอนทั้งหมด ถ้าเราพัฒนา AI เพื่อช่วย T03 และ T04 แล้ว เราจะลดเวลาในการทำงานลงไปกว่าครึ่งของ process ทั้งหมด (5 จาก 7 วัน)
.
📋 How to DEMO
การเขียน OCD มีอยู่ 3 ขั้นตอน ได้แก่:
- Gather data: เก็บข้อมูล process งานจากฝ่ายที่เกี่ยวข้อง (เช่น ฝ่ายบัญชี) โดยใช้ empathy และ compassion เพื่อช่วยให้เราเข้าใจและอยากช่วยเหลือ
- Categorise data: จัดกลุ่มข้อมูลได้เป็น 3 ส่วน ได้แก่:
- Forma: วิธีการสื่อสาร (เช่น อีเมล, แบบฟอร์ม)
- Informa: สิ่งที่ต้องการสื่อสาร (เช่น คำขออนุมัติเบิกค่าเดินทาง)
- Performa: สิ่งที่ทำให้เกิดผลลัพธ์ (เช่น การอนุมัติเบิก)
- Convert to transaction: เปลี่ยนข้อมูลให้เป็น transaction ที่มี 3 องค์ประกอบ ได้แก่:
- Actors: initiator และ executor
- Documents: เอกสารที่เกี่ยวข้อง (เช่น ฟอร์มเบิกค่าเดินทาง, ใบเสร็จ)
- Duration: ระยะเวลาที่ใช้สำหรับ transaction นั้น ๆ (เช่น 1 วัน)
💪 Summary
องค์กรส่วนใหญ่ล้มเหลวในการพัฒนา AI solution ให้ตอบโจทย์ เพราะขาดความเข้าใจ 2 อย่าง ได้แก่:
- People: ความเข้าใจในคนที่เกี่ยวข้อง
- Process: ความเข้าใจในกระบวนการทำงานที่จะเอา AI solution เข้าไปช่วย
เราสามารถแก้ทั้ง 2 สาเหตุนี้ได้ โดยใช้:
- Compassion เพื่อทำความเข้าใจคน
- DEMO เพื่อทำความเข้าใจกระบวนการทำงาน
📚 Further Reading
สำหรับคนที่สนใจศึกษาเชิงลึกเกี่ยวกับหัวข้อในบทความนี้ สามารถอ่านเพิ่มเติมได้ตามนี้
Compassion:
- Connect with Empathy, But Lead with Compassion
- Compassionate Leadership: How to Do Hard Things in a Human Way
- Using AI to Make You a More Compassionate Leader
- Buddhist beliefs – Edexcel
DEMO:
- DEMO: Towards a discipline of organisation engineering
- Enterprise Ontology
- Application of Design and Engineering Methodology for Organization (DEMO) With Scaled Agile Framework 4.0 (SAFe 4.0)
Bonus — สรุปงาน PMAT 60th: