
ในบทความนี้ เราจะมาทำความรู้จักกับ hierarchical cluster analysis (HCA) หรือ hierarchical clustering ในภาษา R กัน
- 🧐 HCA คืออะไร?
- 💻 HCA ในภาษา R: hclust()
- 🔢 Example Dataset: USArrests
- 📏 Normalise the Data
- 🍿 HCA With hclust()
- 📈 Print & Dendrogram
- 😺 GitHub
- 📃 References
- ✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
🧐 HCA คืออะไร?
HCA เป็น machine learning algorithm ประเภท unsupervised learning และใช้จัดกลุ่มข้อมูล (clustering) แบบลำดับชั้น (hierarchical)
HCA มี 2 ประเภท:
- Agglomerative (bottom-up): จับ data point ที่อยู่ใกล้กันให้อยู่ cluster เดียวกัน แล้วจับ clusters ที่อยู่ใกล้กันให้อยูากลุ่มเดียวกัน ทำอย่างนี้ไปเรื่อย ๆ จนได้ 1 cluster ใหญ่
- Divisive (top-down): เริ่มจาก 1 cluster และแยก cluster ย่อยออกมาเรื่อย ๆ
ตัวอย่างการใช้งาน HCA เช่น จัดกลุ่มผู้บริโภค (customer segmentation):
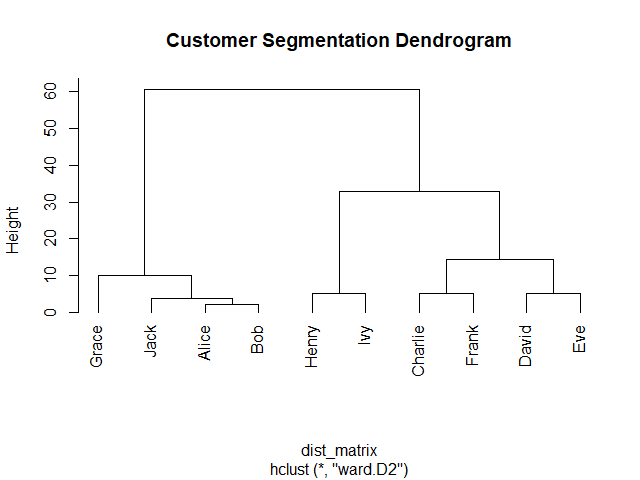
💻 HCA ในภาษา R: hclust()
ในภาษา R เราสามารถทำ HCA ได้ด้วย 2 functions:
hclust()สำหรับ agglomerative HCAdiana()จากclusterpackage สำหรับ divisive HCA
ในบทความนี้ เราจะดูวิธีใช้ hclust() ซึ่งเป็นที่นิยมสำหรับ HCA กัน
🔢 Example Dataset: USArrests
Dataset ที่เราจะใช้เป็นตัวอย่างในบทความนี้ คือ USArrests
USArrests มีข้อมูลจำนวนประชากรจาก 50 รัฐในอเมริกา และข้อมูลการจับกุมใน 3 ประเภทการกระทำผิด ได้แก่:
- ฆาตกรรม (murder)
- ทำร้ายร่างกาย (assault)
- ข่มขืน (rape)
ในการใช้งาน เราสามารถโหลด USArrests ได้ด้วย data():
# Load
data(USArrests)
จากนั้น ดูตัวอย่างข้อมูลด้วย head():
# Preview
head(USArrests)
ผลลัพธ์:
Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7
📏 Normalise the Data
เนื่องจาก HCA จัดกลุ่มข้อมูลโดยใช้ระยะห่างระหว่างข้อมูล เราจะต้อง normalise ข้อมูล เพื่อให้ข้อมูลมีช่วงข้อมูลที่เท่า ๆ กัน และป้องกันไม่ให้ข้อมูลที่มีระยะห่างมาก (เช่น ข้อมูลที่อยู่ในช่วง 1 ถึง 1,000 เทียบกับ ข้อมูลที่มีช่วง 1 ถึง 10) มีผลต่อการจัดกลุ่ม
สำหรับ HCA เราจะ normalise ด้วย z-score standardisation ซึ่งมีสูตรคำนวณดังนี้:
Z = (X - M) / SD
- Z = ข้อมูลที่ normalised แล้ว
- X = ข้อมูลตั้งต้น
- M = ค่าเฉลี่ยของข้อมูลตั้งต้น
- SD = standard deviation (SD) ของข้อมูลตั้งต้น
ทั้งนี้ เราสามารถทำ z-score standardisation ได้ด้วย scale():
# Perform z-score standardisation
USArrests_scaled <- scale(USArrests)
จากนั้น เช็กผลลัพธ์ด้วย colMeans() และ apply() กับ sd():
# Check the results
## Mean
colMeans(USArrests_scaled)
## SD
apply(USArrests_scaled, 2, sd)
ผลลัพธ์:
> ## Mean
> round(colMeans(USArrests_scaled), 2)
Murder Assault UrbanPop Rape
0 0 0 0
>
> ## SD
> apply(USArrests_scaled, 2, sd)
Murder Assault UrbanPop Rape
1 1 1 1
จะเห็นได้ว่า ทุก column มี mean เป็น 0 และ SD เป็น 1 แสดงว่า เรา normalise ข้อมูลได้สำเร็จ และพร้อมไปขั้นตอนถัดไป
🍿 HCA With hclust()
ตอนนี้ เราจะเริ่มใช้ HCA เพื่อจัดกลุ่มข้อมูลกัน
hclust() ต้องการ input 2 อย่าง:
hclust(d, method)
Input #1. d หมายถึง distance matrix หรือ matrix ที่เก็บค่าระยะห่างระหว่างข้อมูลแบบ pair-wise ไว้
เราสามารถคำนวณ distance matrix ได้ด้วย dist() function
Input #2. method หมายถึง linkage method หรือวิธีในการจับ clusters รวมกันเป็น cluster ที่ใหญ่ขึ้น
Linkage methods มี 5 ประเภท:
- Ward’s linkage: จับกลุ่ม cluster โดยลด variance ภายใน cluster
- Complete linkage: ใช้ระยะห่างสูงสุด
- Single linkage: ใช้ระยะห่างต่ำที่สุด
- Average linkage: ใช้ระยะห่างเฉลี่ยระหว่างข้อมูลจาก 2 clusters
- Centroid linkage: ใช้ระยะห่างระหว่างจุดศูนย์กลางของ 2 clusters
Linkage ที่มักใช้กันได้ แก่ Ward’s, complete, และ average และในบทความนี้ เราจะใช้ Ward’s linkage ("ward.D2") กัน
เราเรียกใช้ hclust() เพื่อจัดกลุ่มข้อมูล:
# Create a distance matrix
dm <- dist(USArrests_scaled)
# HCA
hc <- hclust(dm,
method = "ward.D2")
ตอนนี้ เราก็ได้ข้อมูลที่จัดกลุ่มแล้ว
📈 Print & Dendrogram
สุดท้าย เราสามารถดูผลลัพธ์ของ HCA ได้ด้วย print():
# Print HCA
print(hc)
ผลลัพธ์:
Call:
hclust(d = dm, method = "ward.D2")
Cluster method : ward.D2
Distance : euclidean
Number of objects: 50
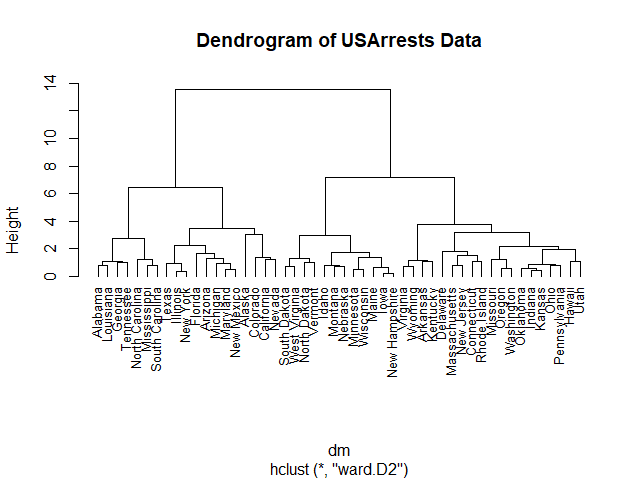
และการสร้าง dendrogram:
# Plot a dendrogram
plot(hc,
hang = -1,
cex = 0.8,
main = "Dendrogram of USArrests Data")
ผลลัพธ์:
😺 GitHub
ดู code ทั้งหมดในบทความนี้ได้ที่ GitHub
📃 References
- Hierarchical Clustering in R
- Unsupervised Learning in R
- Hierarchical clustering
- What is hierarchical clustering?
- hclust: Hierarchical Clustering
✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
📕 ขอฝากหนังสือเล่มแรกในชีวิตด้วยนะครับ 😆
🙋 ใครที่กำลังเรียนจิตวิทยาหรือทำงานสายจิตวิทยา และเบื่อที่ต้องใช้ software ราคาแพงอย่าง SPSS และ Excel เพื่อทำข้อมูล
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
- Correlation
- t-tests
- ANOVA
- Reliability
- Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
แล้วทุกคนจะแปลกใจว่า ทำไมภาษา R ง่ายขนาดนี้ 🙂↕️
👉 สนใจดูรายละเอียดหนังสือได้ที่ meb:
