ในบทความนี้ เราจะมาทำความรู้จักกับ getSymbols() จาก quantmod package ซึ่งใช้โหลดข้อมูลทางการเงิน เช่น ข้อมูลหุ้น และข้อมูลทางเศรษฐกิจ กัน
โดยเราจะไปดู 4 วิธีการใช้งาน ได้แก่:
- Basics: การใช้งาน
getSymbols()เบื้องต้น - Advanced: การใช้งานขั้นสูง
- View columns: การดู column ข้อมูล
- Visualise data: การสร้างกราฟข้อมูล
ถ้าพร้อมแล้ว ไปเริ่มกันเลย
- 💻 Install & Import
- 1️⃣ Basics: 5 Parametres to Know
- 2️⃣ Advanced: Set Defaults
- 3️⃣ View Columns
- 4️⃣ Visualise Data
- 💪 Summary
- 😺 GitHub
- 📃 References
- ✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
💻 Install & Import
ในการใช้งาน getSymbols() เราจะต้องเริ่มจากการติดตั้งและโหลด quantmod package ก่อน แบบนี้:
# Install the packages
install.packages("quantmod")
# Load the packages
library(quantmod)
1️⃣ Basics: 5 Parametres to Know
ในการใช้งานพื้นฐาน getSymbols() มี 5 parametres หลักที่เราควรรู้ ได้แก่:
Symbols: ตัวย่อชื่อข้อมูลsrc: แหล่งข้อมูลauto.assign: ให้โหลด (TRUE) หรือแสดงข้อมูล (FALSE)env: environment สำหรับโหลดข้อมูลfromและto: ช่วงเวลาของข้อมูล
เราไปดูวิธีใช้งานแต่ละ parametre กัน
.
💲 Symbols
ในขั้นแรกของการโหลดข้อมูลการเงินด้วย getSymbols() ให้เราระบุชื่อข้อมูลที่เราต้องการ เช่น:
| ข้อมูล | ชื่อข้อมูล |
|---|---|
| Apple | AAPL |
| GOOG | |
| Microsoft | MSFT |
| NVIDIA | NVDA |
ในบทความนี้ เราจะลองโหลดข้อมูลหุ้น Apple กัน ซึ่งเราสามารถกำหนด Symbols ได้แบบนี้:
# Import Apple data
getSymbols("AAPL")
เมื่อรันแล้ว เราจะได้ตัวแปรประเภท xts (time series object) ชื่อ AAPL มา ซึ่งเราดูข้อมูลในตัวแปรนี้ได้ด้วย head():
# Print result
head(AAPL)
ผลลัพธ์:
AAPL.Open AAPL.High AAPL.Low AAPL.Close AAPL.Volume AAPL.Adjusted
2007-01-03 3.081786 3.092143 2.925000 2.992857 1238319600 2.518541
2007-01-04 3.001786 3.069643 2.993571 3.059286 847260400 2.574443
2007-01-05 3.063214 3.078571 3.014286 3.037500 834741600 2.556108
2007-01-08 3.070000 3.090357 3.045714 3.052500 797106800 2.568732
2007-01-09 3.087500 3.320714 3.041071 3.306071 3349298400 2.782115
2007-01-10 3.383929 3.492857 3.337500 3.464286 2952880000 2.915257
จะเห็นได้ว่า นอกจากวันที่แล้ว ข้อมูลเรายังประกอบไปด้วย 6 columns ดังนี้:
- Open: ราคาเปิด
- High: ราคาสูงสุด
- Low: ราคาต่ำสุด
- Close: ราคาปิด
- Volume: ปริมาณการซื้อขาย
- Adjusted: ราคาปรับปรุง
ในกรณีที่เราต้องการโหลดข้อมูลหุ้นหลายตัวพร้อมกัน เราสามารถใช้ character vector ช่วยได้แบบนี้:
# Load multiple instruments
getSymbols(c("AAPL", "GOOGL", "MSFT", "NVDA"))
.
🏦 src
src ใช้กำหนดแหล่งข้อมูลที่ getSymbols() จะไปดึงข้อมูลมา
โดย default, src ถูกตั้งไว้ให้ดึงข้อมูลจาก Yahoo! Finance ("yahoo")
แสดงว่า เราสามารถเขียน code เพื่อดึงข้อมูล Apple จาก Yahoo! Finance ได้ทั้งแบบนี้:
# Import Apple data
getSymbols("AAPL")
และแบบนี้:
# Import Apple data
getSymbols("AAPL", src = "yahoo")
ทั้งนี้ getSymbols() มีแหล่งข้อมูลอื่น ๆ ให้เราเลือกใช้งานได้ เช่น:
- Federal Reserve Economic Data (
"FRED") - Oanda (
"oanda")
นอกจากแหล่งข้อมูลออนไลน์แล้ว เรายังสามารถโหลดข้อมูลแบบออฟไลน์ได้ เช่น:
- CSV (
"csv") - RData (
"RData")
ยกตัวอย่างเช่น โหลดข้อมูล Apple จาก CSV:
# Load csv data
getSymbols("AAPL", src = "csv")
Note: การโหลดข้อมูล CSV ด้วย getSymbols() มีเงื่อนไข 4 อย่าง ได้แก่:
- มีชื่อไฟล์เป็นชื่อหุ้น (เช่น AAPL.csv)
- มี header
- Column แรกจะต้องเป็น datetime (เช่น 2025-05-25)
- Column ที่เหลือควรมีชื่อและข้อมูลดังนี้:
- Open: ข้อมูลราคาเปิด
- High: ข้อมูลราคาสูงสุด
- Low: ข้อมูลราคาต่ำสุด
- Close: ข้อมูลราคาปิด
- Volume: ข้อมูลปริมาณการซื้อขาย
- Adjusted: ข้อมูลราคาปรับปรุง
.
🏧 auto.assign
auto.assign ใช้กำหนดว่า getSymbols() จะโหลดข้อมูลมาไว้ใน global environment หรือแสดงข้อมูลที่โหลดมาได้
โดย default, auto.assign เป็น TRUE ซึ่งทำให้เราได้ตัวแปรที่เก็บข้อมูลการเงินมาไว้ใน global environment ของเรา โดยไม่ต้องกำหนดตัวแปรเอง
ทั้งนี้ ในกรณีที่เราต้องการกำหนดตัวแปรเอง ให้เราเปลี่ยน auto.assign เป็น FALSE แบบนี้:
# Set auto.assign to FALSE to assign to custom variable
apple_data <- getSymbols("AAPL", auto.assign = FALSE)
ถ้าเรากำหนดให้ auto.assign = FALSE โดยไม่จัดเก็บไว้ในตัวแปร getSymbols() จะแสดงข้อมูลใน console ของเรา:
# Set auto.assign to FALSE without variable assignment
getSymbols("AAPL", auto.assign = FALSE)
ผลลัพธ์:
AAPL.Open AAPL.High AAPL.Low AAPL.Close AAPL.Volume AAPL.Adjusted
2007-01-03 3.081786 3.092143 2.925000 2.992857 1238319600 2.518541
2007-01-04 3.001786 3.069643 2.993571 3.059286 847260400 2.574442
2007-01-05 3.063214 3.078571 3.014286 3.037500 834741600 2.556108
2007-01-08 3.070000 3.090357 3.045714 3.052500 797106800 2.568732
2007-01-09 3.087500 3.320714 3.041071 3.306071 3349298400 2.782115
2007-01-10 3.383929 3.492857 3.337500 3.464286 2952880000 2.915257
2007-01-11 3.426429 3.456429 3.396429 3.421429 1440252800 2.879192
2007-01-12 3.378214 3.395000 3.329643 3.379286 1312690400 2.843727
2007-01-16 3.417143 3.473214 3.408929 3.467857 1244076400 2.918262
2007-01-17 3.484286 3.485714 3.386429 3.391071 1646260000 2.853645
...
2025-06-05 203.500000 204.750000 200.149994 200.630005 55126100 200.630005
2025-06-06 203.000000 205.699997 202.050003 203.919998 46607700 203.919998
2025-06-09 204.389999 206.000000 200.020004 201.449997 72862600 201.449997
2025-06-10 200.600006 204.350006 200.570007 202.669998 54672600 202.669998
2025-06-11 203.500000 204.500000 198.410004 198.779999 60989900 198.779999
2025-06-12 199.080002 199.679993 197.360001 199.199997 43904600 199.199997
2025-06-13 199.729996 200.369995 195.699997 196.449997 51447300 196.449997
2025-06-16 197.300003 198.690002 196.559998 198.419998 43020700 198.419998
2025-06-17 197.199997 198.389999 195.210007 195.639999 38856200 195.639999
2025-06-18 195.940002 197.570007 195.070007 196.580002 45350400 196.580002
.
🌲 env
env ใช้กำหนด environment ที่ใช้เก็บข้อมูล ซึ่งโดย default, getSymbols() จะโหลดข้อมูลไว้ใน global environment
ในการใช้ env กำหนด environment ที่ต้องการ เราจะต้องเริ่มจากสร้าง environment ขึ้นมาก่อนด้วย new.env():
# Create a new environment
my_env <- new.env()
จากนั้น โหลดข้อมูลเข้าไปใน environment ใหม่:
# Load data into the environment
getSymbols("AAPL", env = my_env)
เราสามารถดูตัวแปรที่เก็บไว้ใน environment ได้ด้วย ls():
# List all variables in environment
ls(envir = my_env)
และดูข้อมูลได้ด้วย $ เช่น:
# Show Apple data
head(my_env$AAPL)
ผลลัพธ์:
AAPL.Open AAPL.High AAPL.Low AAPL.Close AAPL.Volume AAPL.Adjusted
2007-01-03 3.081786 3.092143 2.925000 2.992857 1238319600 2.518541
2007-01-04 3.001786 3.069643 2.993571 3.059286 847260400 2.574442
2007-01-05 3.063214 3.078571 3.014286 3.037500 834741600 2.556109
2007-01-08 3.070000 3.090357 3.045714 3.052500 797106800 2.568732
2007-01-09 3.087500 3.320714 3.041071 3.306071 3349298400 2.782115
2007-01-10 3.383929 3.492857 3.337500 3.464286 2952880000 2.915256
.
📆 from, to
from ใช้กำหนดวันแรกของข้อมูล และ to กำหนดวันสุดท้ายของข้อมูล
ยกตัวอย่างเช่น เราต้องการโหลดข้อมูล Apple ในเดือนพฤษภาคม 2025:
# Load data for May 2025
apple_data_2025_05 = getSymbols("AAPL",
auto.assign = FALSE,
from = "2025-05-01",
to = "2025-05-31")
# Print results
print("First three records:")
head(apple_data_2025_05, n = 3)
print("------------------------------------------------------------------------------")
print("Last three records:")
tail(apple_data_2025_05, n = 3)
ผลลัพธ์:
First three records:
AAPL.Open AAPL.High AAPL.Low AAPL.Close AAPL.Volume AAPL.Adjusted
2025-05-01 209.08 214.56 208.90 213.32 57365700 213.0406
2025-05-02 206.09 206.99 202.16 205.35 101010600 205.0811
2025-05-05 203.10 204.10 198.21 198.89 69018500 198.6295
------------------------------------------------------------------------------
Last three records:
AAPL.Open AAPL.High AAPL.Low AAPL.Close AAPL.Volume AAPL.Adjusted
2025-05-28 200.59 202.73 199.90 200.42 45339700 200.42
2025-05-29 203.58 203.81 198.51 199.95 51396800 199.95
2025-05-30 199.37 201.96 196.78 200.85 70819900 200.85
Note: ตลาดหุ้นวันสุดท้ายของเดือนพฤษภาคม 2025 คือ 30 พฤษภาคม ทำให้ข้อมูลสิ้นสุด ณ วันที่ 30
2️⃣ Advanced: Set Defaults
จะเห็นว่า getSymbols() การตั้งค่าที่หลากหลาย
ทั้งนี้ quantmod มี 6 functions ที่ใช้ร่วมกับ getSymbols() เพื่อช่วยลดขั้นตอนในการตั้งค่าต่าง ๆ ได้แก่:
getDefaults()และsetDefaults()getSymbolLookup()และsetSymbolLookup()saveSymbolLookup()และloadSymbolLookup()
เราไปดูวิธีการใช้งานทั้ง 6 functions กัน
.
🌍 getDefaults(), setDefaults()
getDefaults() ใช้สำหรับดูค่า default ของ getSymbols()
ส่วน setDefaults() ใช้สำหรับกำหนดค่า default
ยกตัวอย่างเช่น เราต้องการกำหนด:
srcจาก"yahoo"เป็น"FRED"auto.assignจากTRUEเป็นFALSE
เราสามารถทำได้แบบนี้:
# Get defaults before changing
print("Defaults (before):")
getDefaults(getSymbols)
# Set defaults
setDefaults(getSymbols,
src = "FRED",
auto.assign = FALSE)
# Get defaults after changing
print("Defaults (after):")
getDefaults(getSymbols)
ผลลัพธ์:
Defaults (before):
NULL
Defaults (after):
$src
[1] "'FRED'"
$auto.assign
[1] FALSE
ตอนนี้ ถ้าเราเรียกใช้ getSymbols() โดยไม่กำหนด src และ auto.assign ทั้งสอง arguments นี้จะเป็น "FRED" และ FALSE ตามลำดับ
ถ้าเราต้องการ reset ค่า default ให้เราใส่ NULL ใน setDefaults():
# Reset defaults
setDefaults(getSymbols,
src = NULL,
auto.assign = NULL)
# Check defaults after resetting
print("Defaults (reset):")
getDefaults(getSymbols)
ผลลัพธ์:
Defaults (reset):
NULL
.
💹 setSymbolLookup(), getSymbolLookup()
getSymbolLookup() และ setSymbolLookup() ทำงานเหมือนกับ getDefaults() และ setDefaults() แต่เป็นการตั้งค่า default สำหรับข้อมูลแต่ละตัว (แทนระดับ global) ภายใน session เท่านั้น
ยกตัวอย่างเช่น เราต้องการกำหนดให้ดึงข้อมูลหุ้น Google มาจาก Google Finance:
# Set default for Google
setSymbolLookup(GOOG = list(src = "google"))
# Get new defaults
getSymbolLookup()
ผลลัพธ์:
$GOOG
$GOOG$src
[1] "google"
Note: Google Finance หยุดให้ข้อมูลกับ quantmod เมื่อปี 2018 ทำให้ตอนนี้ เราไม่สามารถใช้ src = "google" ได้อีก
เราสามารถ reset ค่า default ได้โดยใส่ NULL เหมือนเดิม:
# Reset defaults
setSymbolLookup(NULL)
# Get defaults after resetting
getSymbolLookup()
ผลลัพธ์:
named list()
.
💾 saveSymbolLookup(), loadSymbolLookup()
ค่าที่เราใช้ setSymbolLookup() กำหนดจะถูก reset ทุกครั้งที่เราปิด session ไป
ถ้าเราต้องการเก็บค่าเพื่อไปใช้ใน session อื่น เราสามารถใช้ saveSymbolLookup() และ loadSymbolLookup() ช่วยได้:
saveSymbolLookup()บันทึกค่าเก็บไว้ในไฟล์ RDSloadSymbolLookup()โหลดค่าที่เก็บไว้ใน RDS
ตัวอย่าง code:
# Save defaults
saveSymbolLookup(file = "symbols.rds")
# Load defaults
loadSymbolLookup(file = "symbols.rds")
3️⃣ View Columns
หลังจากเราโหลดข้อมูลมาแล้ว เราสามารถดูข้อมูลแต่ละ column ได้ด้วย 7 functions หลัก ดังนี้:
| No. | Function | For |
|---|---|---|
| 1 | Op() | ราคาเปิด |
| 2 | Hi() | ราคาสูงสุด |
| 3 | Lo() | ราคาต่ำสุด |
| 4 | Cl() | ราคาปิด |
| 5 | Ad() | ราคาปรับปรุง |
| 6 | Vo() | ปริมาณการซื้อขาย |
| 7 | OHLC() | ราคาเปิด, สูงสุด, ต่ำสุด, และราคาปิด |
ตัวอย่างเช่น ดูราคาเปิด:
# Get opening price
Op(AAPL)
ผลลัพธ์:
AAPL.Open
2007-01-03 3.081786
2007-01-04 3.001786
2007-01-05 3.063214
2007-01-08 3.070000
2007-01-09 3.087500
2007-01-10 3.383929
2007-01-11 3.426429
2007-01-12 3.378214
2007-01-16 3.417143
2007-01-17 3.484286
...
2025-06-05 203.500000
2025-06-06 203.000000
2025-06-09 204.389999
2025-06-10 200.600006
2025-06-11 203.500000
2025-06-12 199.080002
2025-06-13 199.729996
2025-06-16 197.300003
2025-06-17 197.199997
2025-06-18 195.940002
ดูราคาสูงสุด:
# Get highest price
Hi(AAPL)
ผลลัพธ์:
AAPL.High
2007-01-03 3.092143
2007-01-04 3.069643
2007-01-05 3.078571
2007-01-08 3.090357
2007-01-09 3.320714
2007-01-10 3.492857
2007-01-11 3.456429
2007-01-12 3.395000
2007-01-16 3.473214
2007-01-17 3.485714
...
2025-06-05 204.750000
2025-06-06 205.699997
2025-06-09 206.000000
2025-06-10 204.350006
2025-06-11 204.500000
2025-06-12 199.679993
2025-06-13 200.369995
2025-06-16 198.690002
2025-06-17 198.389999
2025-06-18 197.570007
ดูราคาต่ำสุด:
# Get lowest price
Lo(AAPL)
ผลลัพธ์:
AAPL.Low
2007-01-03 2.925000
2007-01-04 2.993571
2007-01-05 3.014286
2007-01-08 3.045714
2007-01-09 3.041071
2007-01-10 3.337500
2007-01-11 3.396429
2007-01-12 3.329643
2007-01-16 3.408929
2007-01-17 3.386429
...
2025-06-05 200.149994
2025-06-06 202.050003
2025-06-09 200.020004
2025-06-10 200.570007
2025-06-11 198.410004
2025-06-12 197.360001
2025-06-13 195.699997
2025-06-16 196.559998
2025-06-17 195.210007
2025-06-18 195.070007
ดูราคาปิด:
# Get closing price
Cl(AAPL)
ผลลัพธ์:
AAPL.Close
2007-01-03 2.992857
2007-01-04 3.059286
2007-01-05 3.037500
2007-01-08 3.052500
2007-01-09 3.306071
2007-01-10 3.464286
2007-01-11 3.421429
2007-01-12 3.379286
2007-01-16 3.467857
2007-01-17 3.391071
...
2025-06-05 200.630005
2025-06-06 203.919998
2025-06-09 201.449997
2025-06-10 202.669998
2025-06-11 198.779999
2025-06-12 199.199997
2025-06-13 196.449997
2025-06-16 198.419998
2025-06-17 195.639999
2025-06-18 196.580002
ดูราคาปรับปรุง:
# Get adjusted price
Ad(AAPL)
ผลลัพธ์:
AAPL.Adjusted
2007-01-03 2.518541
2007-01-04 2.574442
2007-01-05 2.556109
2007-01-08 2.568732
2007-01-09 2.782116
2007-01-10 2.915256
2007-01-11 2.879192
2007-01-12 2.843727
2007-01-16 2.918261
2007-01-17 2.853645
...
2025-06-05 200.630005
2025-06-06 203.919998
2025-06-09 201.449997
2025-06-10 202.669998
2025-06-11 198.779999
2025-06-12 199.199997
2025-06-13 196.449997
2025-06-16 198.419998
2025-06-17 195.639999
2025-06-18 196.580002
ดูปริมาณการซื้อขาย:
# Get volume
Vo(AAPL)
ผลลัพธ์:
AAPL.Volume
2007-01-03 1238319600
2007-01-04 847260400
2007-01-05 834741600
2007-01-08 797106800
2007-01-09 3349298400
2007-01-10 2952880000
2007-01-11 1440252800
2007-01-12 1312690400
2007-01-16 1244076400
2007-01-17 1646260000
...
2025-06-05 55126100
2025-06-06 46607700
2025-06-09 72862600
2025-06-10 54672600
2025-06-11 60989900
2025-06-12 43904600
2025-06-13 51447300
2025-06-16 43020700
2025-06-17 38856200
2025-06-18 45350400
ดูราคาเปิด, สูงสุด, ต่ำสุด, และราคาปิด:
# Get all price
OHLC(AAPL)
ผลลัพธ์:
AAPL.Open AAPL.High AAPL.Low AAPL.Close
2007-01-03 3.081786 3.092143 2.925000 2.992857
2007-01-04 3.001786 3.069643 2.993571 3.059286
2007-01-05 3.063214 3.078571 3.014286 3.037500
2007-01-08 3.070000 3.090357 3.045714 3.052500
2007-01-09 3.087500 3.320714 3.041071 3.306071
2007-01-10 3.383929 3.492857 3.337500 3.464286
2007-01-11 3.426429 3.456429 3.396429 3.421429
2007-01-12 3.378214 3.395000 3.329643 3.379286
2007-01-16 3.417143 3.473214 3.408929 3.467857
2007-01-17 3.484286 3.485714 3.386429 3.391071
...
2025-06-05 203.500000 204.750000 200.149994 200.630005
2025-06-06 203.000000 205.699997 202.050003 203.919998
2025-06-09 204.389999 206.000000 200.020004 201.449997
2025-06-10 200.600006 204.350006 200.570007 202.669998
2025-06-11 203.500000 204.500000 198.410004 198.779999
2025-06-12 199.080002 199.679993 197.360001 199.199997
2025-06-13 199.729996 200.369995 195.699997 196.449997
2025-06-16 197.300003 198.690002 196.559998 198.419998
2025-06-17 197.199997 198.389999 195.210007 195.639999
2025-06-18 195.940002 197.570007 195.070007 196.580002
4️⃣ Visualise Data
สุดท้าย เราสามารถสร้างกราฟเพื่อสำรวจข้อมูล โดยใช้ 2 functions ได้แก่:
autoplot()จากggplot2packagechartSeries()จากquantmodpackage
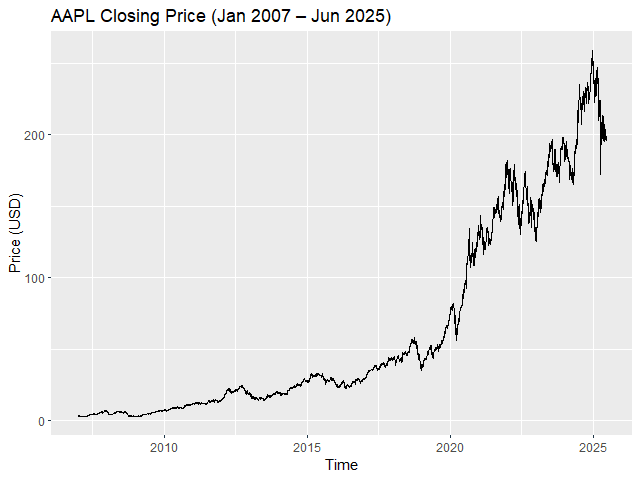
ยกตัวอย่างเช่น สำรวจราคาปิดของ Apple:
# Import ggplots
library(ggplot2)
# Visualise with autoplot()
autoplot(Cl(AAPL),
ts.colour = "darkgreen") +
# Add text
labs(title = "AAPL Closing Price (Jan 2007 – Jun 2025)",
x = "Time",
y = "Price (USD)")
ผลลัพธ์:
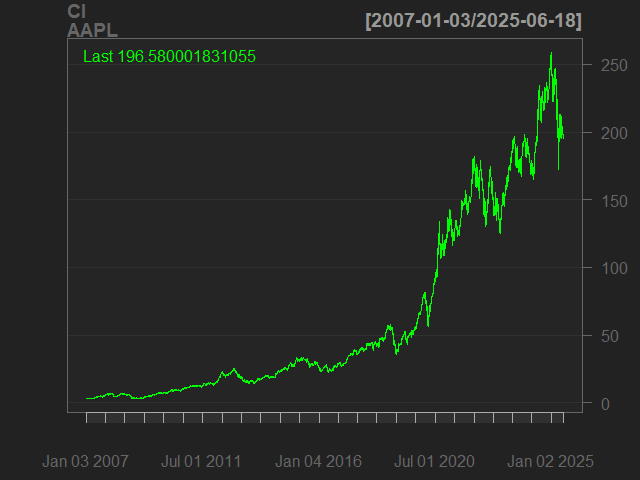
# Visualise with chartSeries()
chartSeries(Cl(AAPL))
ผลลัพธ์:
💪 Summary
ในบทความนี้ เราได้ดูวิธีการทำงานกับ getSymbols() เพื่อโหลดข้อมูลจากการเงินจากแหล่งต่าง ๆ กัน
ตอนนี้ เรารู้จักกับ 5 parametres หลักของ getSymbols():
Symbolssrcauto.assignenvfromและto
วิธีตั้งค่า default ด้วย 3 คู่ functions:
getDefaults()และsetDefaults()getSymbolLookup()และsetSymbolLookup()saveSymbolLookup()และloadSymbolLookup()
วิธีดูข้อมูลด้วย 7 functions:
Op()Hi()Lo()Cl()Ad()Vo()OHLC()
และสุดท้าย วิธีสร้างกราฟด้วย 2 functions:
autoplot()chartSeries()
😺 GitHub
ดู code ทั้งหมดในบทความนี้ได้ที่ GitHub
📃 References
- Importing and Managing Financial Data in R
- getSymbols.google: Download OHLC Data From Google Finance
- getSymbols() method for fetching data in R
✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
📕 ขอฝากหนังสือเล่มแรกในชีวิตด้วยนะครับ 😆
🙋 ใครที่กำลังเรียนจิตวิทยาหรือทำงานสายจิตวิทยา และเบื่อที่ต้องใช้ software ราคาแพงอย่าง SPSS และ Excel เพื่อทำข้อมูล
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
- Correlation
- t-tests
- ANOVA
- Reliability
- Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
แล้วทุกคนจะแปลกใจว่า ทำไมภาษา R ง่ายขนาดนี้ 🙂↕️
👉 สนใจดูรายละเอียดหนังสือได้ที่ meb: