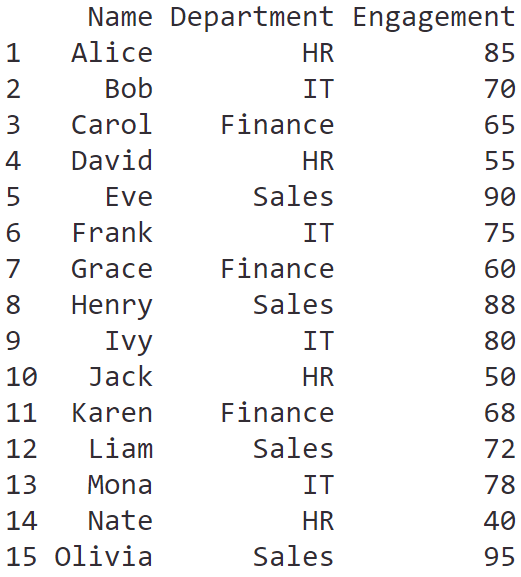
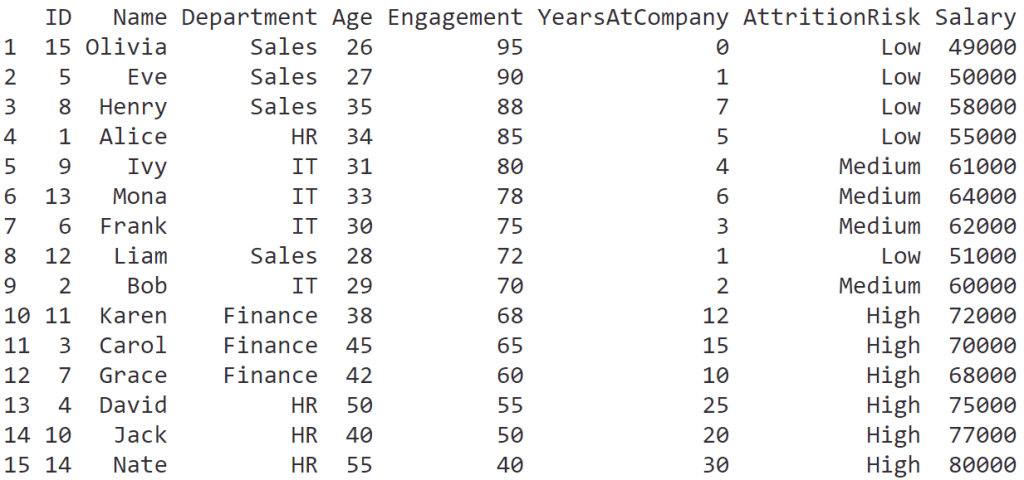
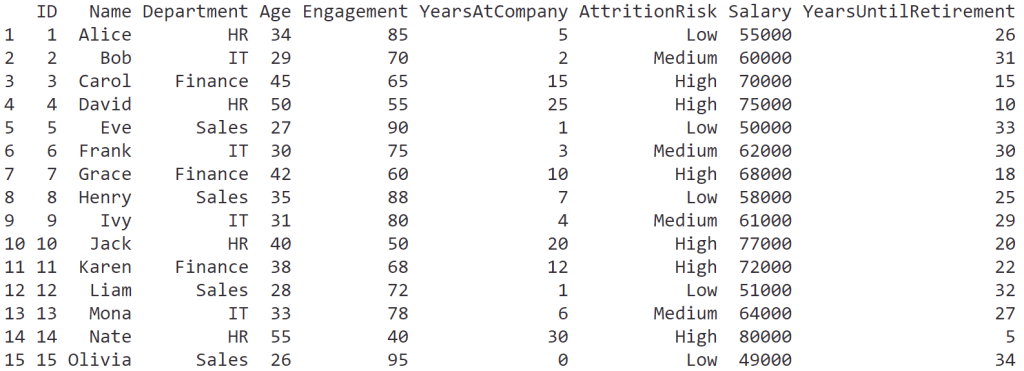
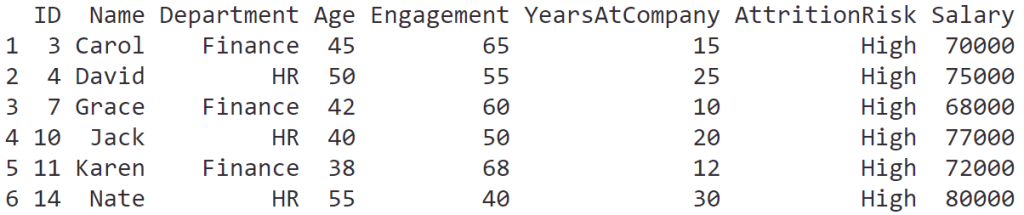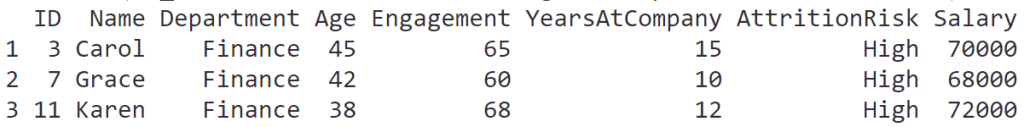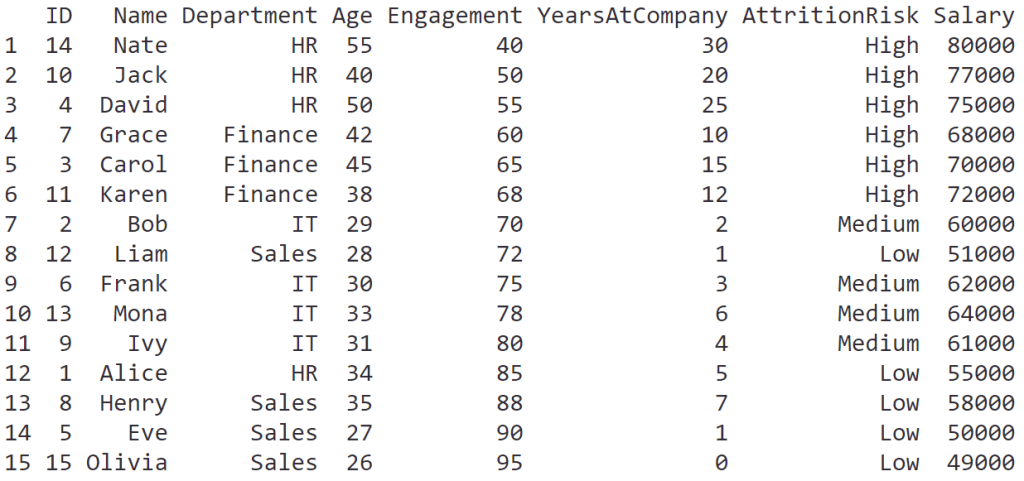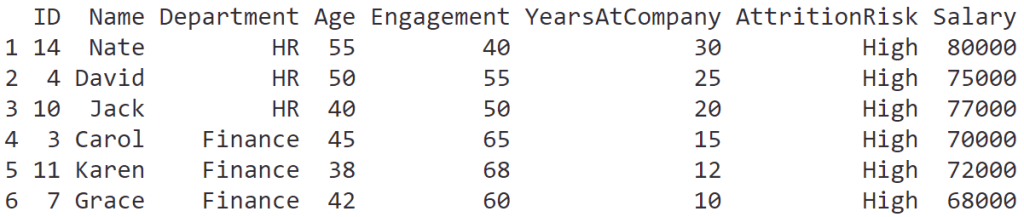ในบทความนี้ เราจะมาทำความรู้จักกับการใช้ data visualisation หรือเรียกสั้น ๆ ว่า data viz เบื้องต้นกัน:
- Data viz คืออะไร?
- วิธีเลือกและประเภท data viz
ถ้าพร้อมแล้วไปเริ่มกันเลย
- Data Viz & Its Values
- วิธีเลือกใช้ Data Viz
- Data Viz สำหรับ 1 ตัวแปร
- Data Viz สำหรับ 2 ตัวแปร
- Data Viz สำหรับมากกว่า 2 ตัวแปร
- Caution: Pie Chart
- สรุป
- Bonus: เพิ่มตัวแปรใน Data Viz อย่างง่าย ๆ
Data Viz & Its Values
Data viz เป็นการนำเสนอข้อมูล (data หรือ information) ในรูปแบบของ …
- กราฟ/ชาร์ต (graph/chart)
- แผนภาพ (diagram)
- รูปภาพ (picture)
การแปลข้อมูลมาอยู่ในรูปของ data viz มีประโยชน์หลัก ๆ คือ
- ช่วยให้เห็น pattern ที่อยู่ในข้อมูลได้ง่ายขึ้น
- (ในกรณีที่ใช้ในการนำเสนอข้อมูล) ช่วยให้คนอื่นเข้าใจและจดจำข้อมูลของเราได้ดีขึ้น
Anscombe’s Quartet
ประโยชน์ของ data viz เห็นได้ชัดที่สุด ในตัวอย่างของ Anscombe’s Quartet
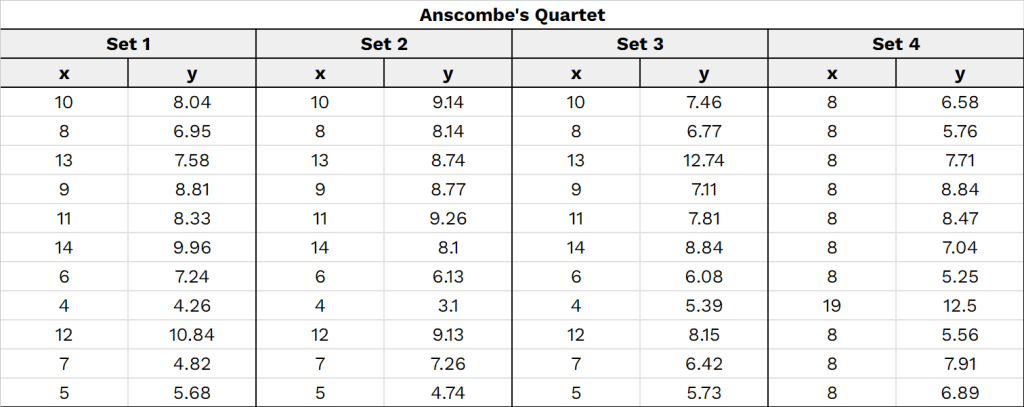
Anscombe’s Quartet เป็นข้อมูล 4 ชุด (แต่ละชุดประกอบด้วยคะแนน x และ y) ที่แตกต่างกัน แต่มีค่าสถิติที่เกือบจะเหมือนกัน เช่น
- ค่าเฉลี่ย (mean) ของ x และ y
- ค่าความแปรปวน (variance) ของ x และ y
- correlation ระหว่าง x และ y
แต่ถ้าเรานำ Anscombe’s Quartet มาทำเป็น data viz ก็จะเห็นว่า ข้อมูลทั้งสี่ชุดแตกต่างกันอย่างชัดเจน

Anscombe’s Quartet เป็นตัวอย่างที่แสดงให้เห็นว่า data viz สามารถช่วยให้เราทำความเข้าใจข้อมูลได้อย่างง่ายและรวดเร็ว
(ใครที่สนใจข้อมูลชุดนี้ สามารถเข้าดูเพิ่มได้ที่ Google Sheets)
วิธีเลือกใช้ Data Viz
เพื่อใช้งาน data viz ให้เกิดประสิทธิภาพสูงสุด เราควรเลือกใช้งาน data viz ให้ถูกประเภท
โดยปัจจัยที่เราใช้เพื่อเลือก data viz มีอยู่ 2 อย่าง คือ
- จำนวนตัวแปร (variable) ที่เราใช้สร้าง data viz
- ประเภทของตัวแปร ซึ่งแยกได้เป็น 2 ประเภท ได้แก่
- Categorical variable หรือตัวแปรเชิงคุณภาพ เช่น เพศ จังหวัด สกุลเงิน
- Continuous variable หรือตัวแปรเชิงปริมาณ เช่น ความสูง น้ำหนัก จำนวนเงิน
เมื่อเราใช้ 2 ปัจจัยนี้ เราจะจัดกลุ่ม data viz ได้ต่อไปดังนี้
Data Viz สำหรับ 1 ตัวแปร
.
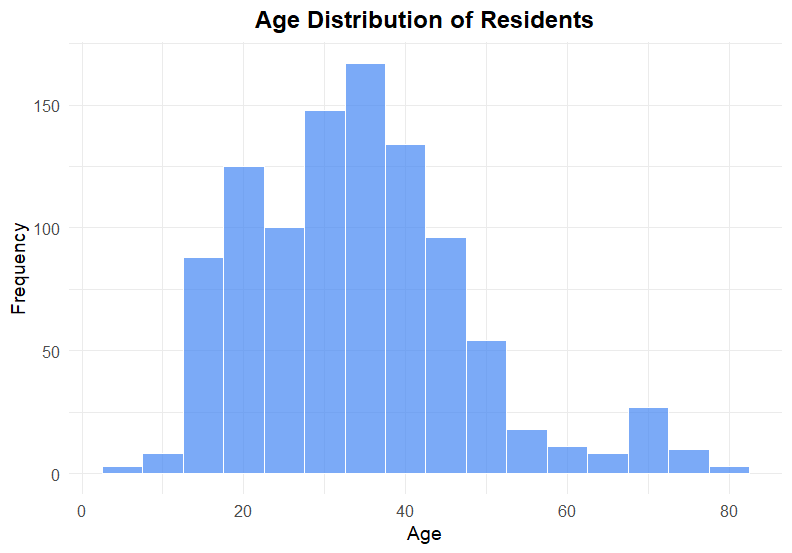
(1) Histogram
ประเภทตัวแปร:
Categorical variable
กรณีการใช้งาน:
สำรวจการกระจายตัว (distribution) ของตัวแปร
ตัวอย่าง:
การกระจายตัวของอายุประชาชน
.
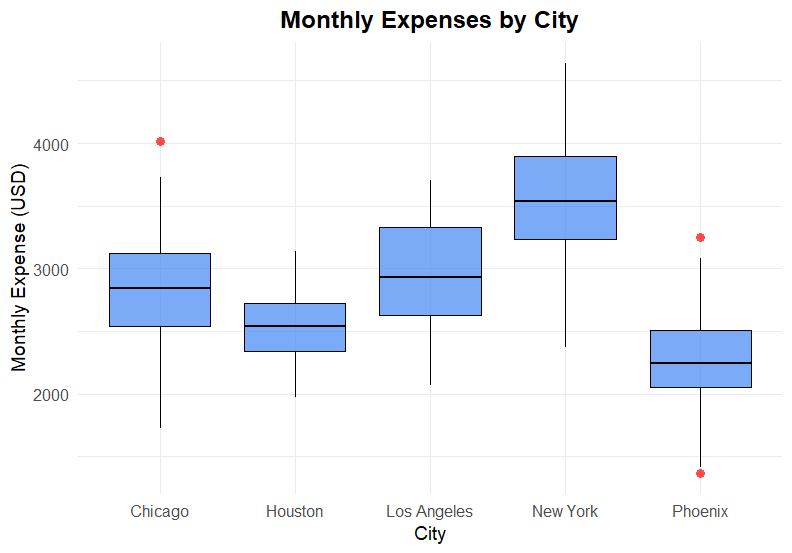
(2) Box Plot
ประเภทตัวแปร:
Categorical variable
กรณีการใช้งาน:
- สำรวจ distribution ของตัวแปร
- เปรียบเทียบ distribution กับตัวแปรอื่น ๆ
ตัวอย่าง:
ค่าใช้จ่ายรายเดือนของ 5 เมืองใหญ่ในอเมริกา
Data Viz สำหรับ 2 ตัวแปร
.
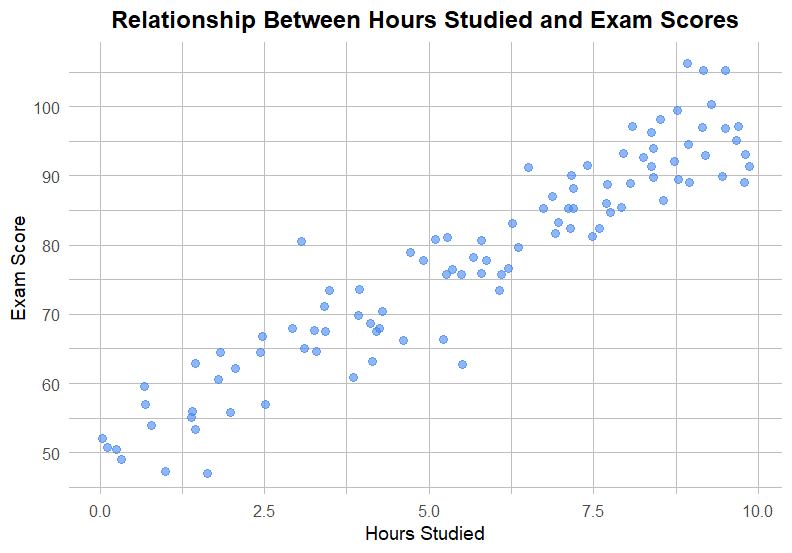
(1) Scatter Plot
ประเภทตัวแปร:
1 continuous x 1 continuous variable
กรณีการใช้งาน:
สำรวจความสัมพันธ์ระหว่าง 2 ตัวแปร
ตัวอย่าง:
ความสัมพันธ์ระหว่างชั่วโมงเรียนและคะแนนสอบ
.
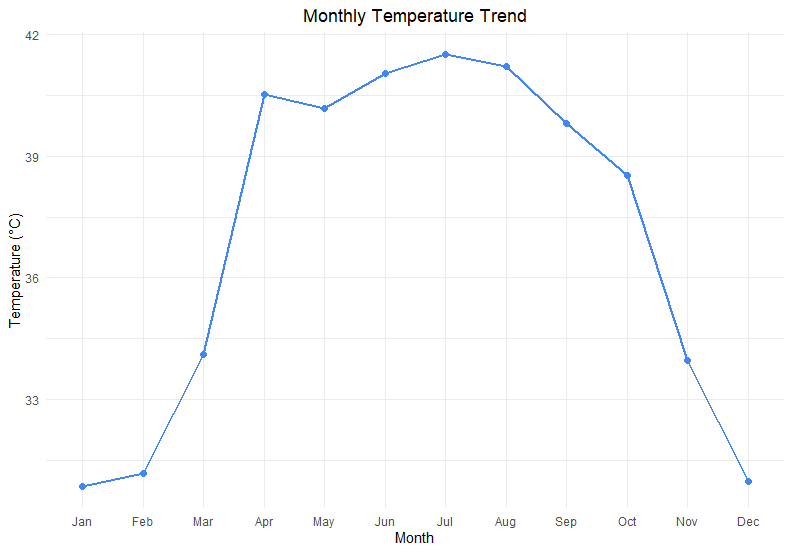
(2) Line Plot
ประเภทตัวแปร:
1 continuous x 1 continuous variable
กรณีการใช้งาน:
- สำรวจความสัมพันธ์ระหว่าง 2 ตัวแปร
- ดู trend การเปลี่ยนแปลงตามเวลา
ตัวอย่าง:
ระดับอุณหภูมิในช่วงเวลา 1 ปี
.
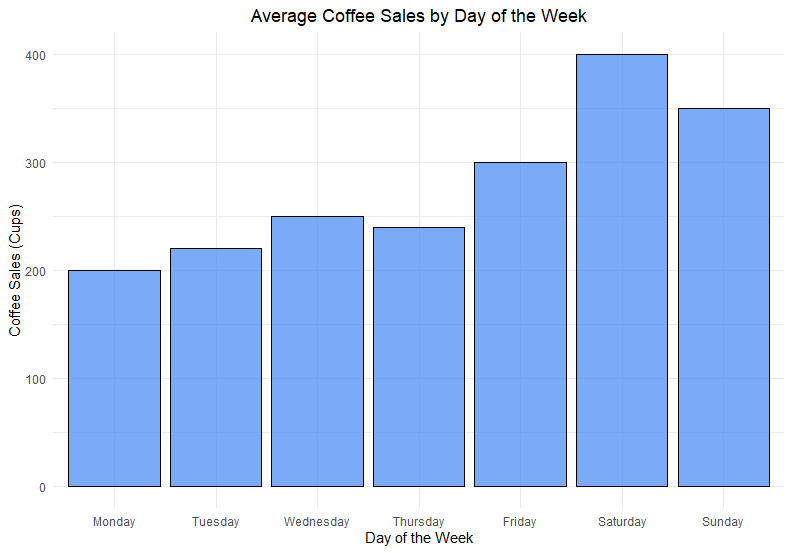
(3) Bar Plot
ประเภทตัวแปร:
1 categorical x 1 continuous variable
กรณีการใช้งาน:
- นับจำนวนครั้งของ categorical variable
- ดู percent ของ continuous variable เมื่อแบ่งตาม categorical variable
ตัวอย่าง:
จำนวนกาแฟที่ขายได้ในแต่ละวันของสัปดาห์
.
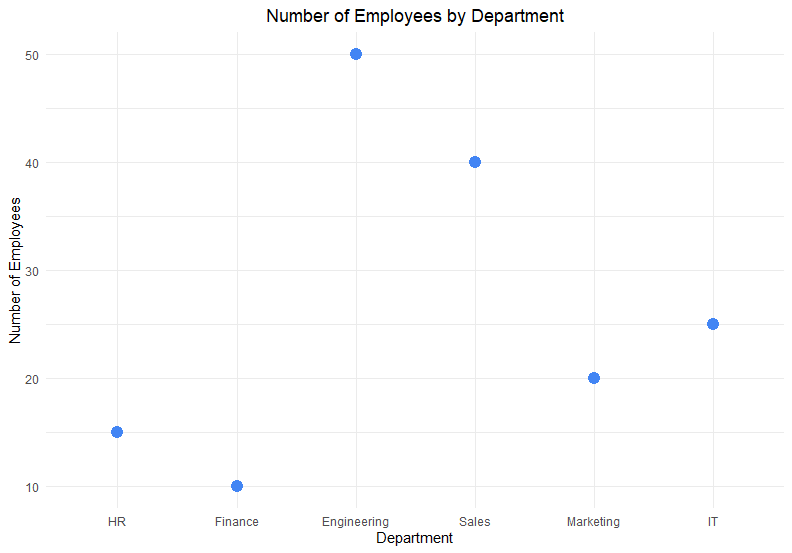
(4) Dot Plot
ประเภทตัวแปร:
1 categorical x 1 continuous variable
กรณีการใช้งาน:
ดูจำนวน continuous variable เมื่อแบ่งตาม categorical variable
ตัวอย่าง:
จำนวนพนักงานในแต่ละแผนก
Data Viz สำหรับมากกว่า 2 ตัวแปร
.
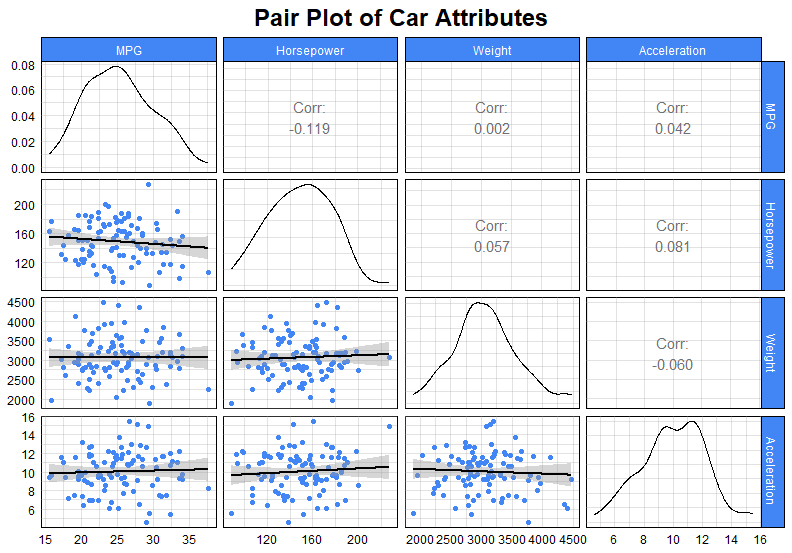
(1) Pair Plot
จำนวนตัวแปร:
สูงสุด 10 ตัวแปร
ประเภทตัวแปร:
Categorical, continuous variables, หรือผสมก็ได้
กรณีการใช้งาน:
- ดู distribution ของตัวแปร
- หาความสัมพันธ์ระหว่างตัวแปร
ตัวอย่าง:
ดูความสัมพันธ์ระหว่างลักษณะต่าง ๆ ของรถยนต์ เช่น แรงม้า น้ำหนัก การกินน้ำมัน
.
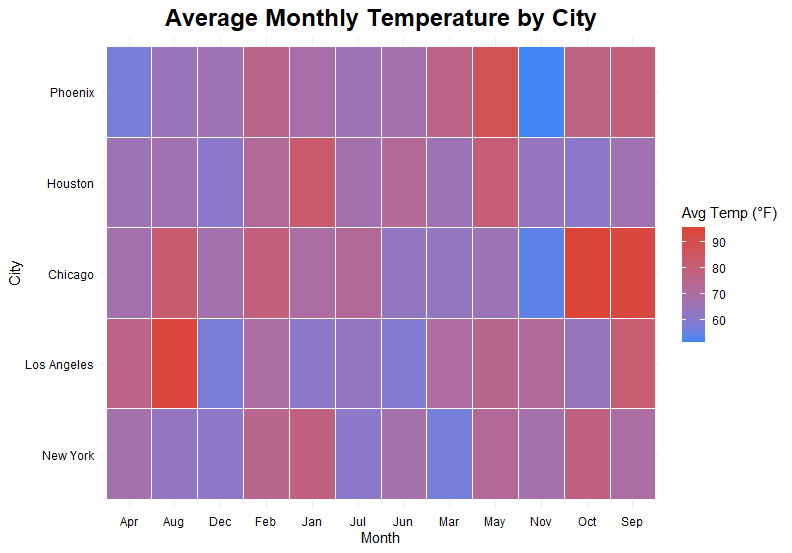
(2) Heatmap
ประเภทตัวแปร:
Continuous variables
กรณีการใช้งาน:
หาความสัมพันธ์ระหว่างตัวแปร
ตัวอย่าง:
อุณหภูมิของแต่ละเมืองในแต่ละเดือน
.
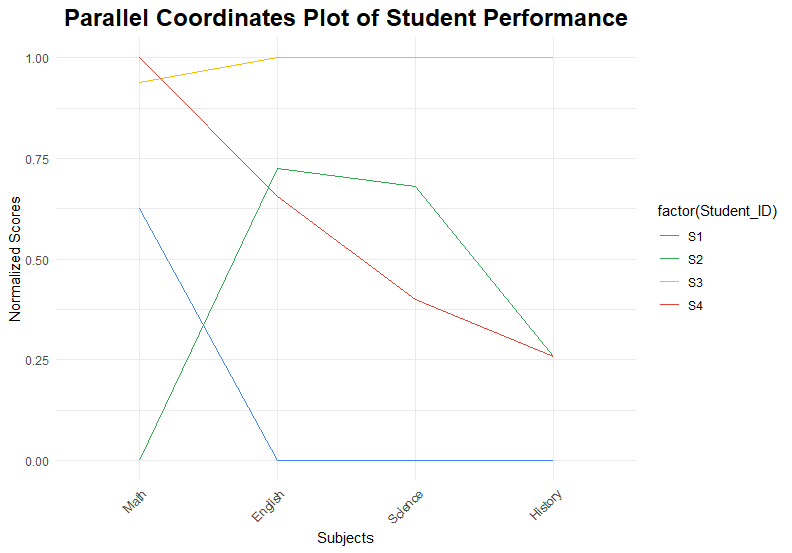
(3) Parallel Coordinates Plot
ประเภทตัวแปร:
Continuous variables เท่านั้น
กรณีการใช้งาน:
- หา pattern ในข้อมูล
- จับกลุ่ม pattern ในข้อมูล
ตัวอย่าง:
คะแนนสอบนักเรียนในแต่ละวิชา
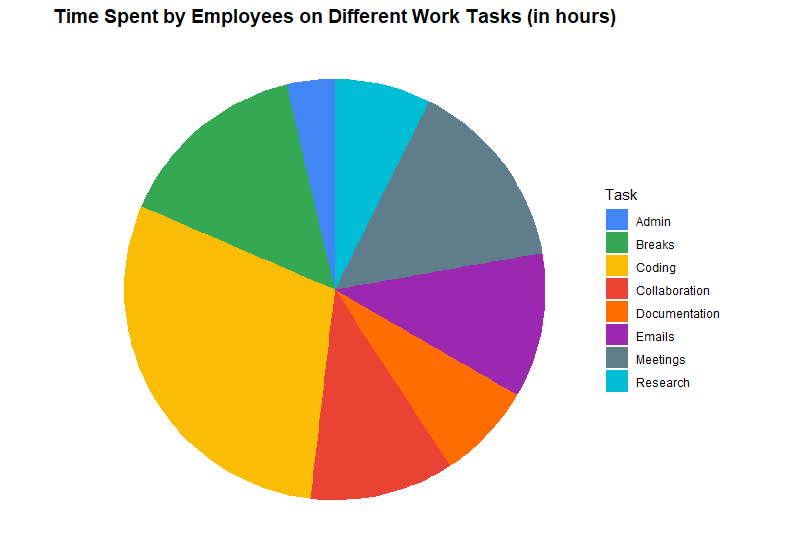
Caution: Pie Chart
Pie chart เป็น data viz ที่ควรหลีกเลี่ยง เพราะเป็นกราฟที่ตีความได้ยาก
ตัวอย่างเช่น pie chart ที่แสดงสัดส่วนเวลาที่ programmer ใช้ในแต่ละวัน เราจะรู้ได้ยังไงว่า programmer ใช้เวลาไปกับอะไรมากกว่ากัน ระหว่าง Research และ Documentation
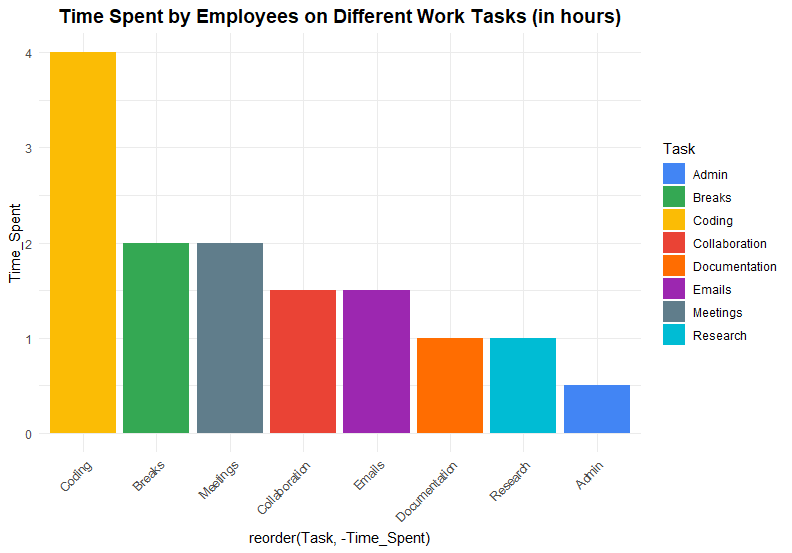
จากตัวอย่าง ถ้าเราใช้ bar plot แทน จะเห็นได้ว่า เราทำความเข้าใจข้อมูลได้เร็วกว่า และตอบได้ทันทีว่า programmer ใช้เวลาไปกับ Research และ Documentation เท่า ๆ กัน:
กรณีหลัก ๆ ที่เราจะใช้ pie chart คือ สำรวจสัดส่วนของข้อมูล เช่น ตัวอย่างด้านบน หรือจากยอดขายทั้งหมด สินค้าแต่ละตัวขายได้เป็นกี่เปอร์เซ็นต์
นอกจากนี้ เราไม่ควรใช้ pie chart กับข้อมูลที่มี category มากกว่า 7 เพราะจะทำให้ pie chart อ่านยาก
สรุป
Data viz เป็นเครื่องมือช่วยในการทำความเข้าใจและสื่อสารข้อมูล
โดยการเลือกใช้ data viz ขึ้นอยู่กับ 2 ปัจจัย คือ
- จำนวนตัวแปร
- ประเภทตัวแปร
เราสามารถใช้ 2 ปัจจัยนี้ สรุปการเลือกใช้ data viz 10 ประเภทได้ดังนี้:
| No. | Data Viz | จำนวน | ประเภท |
|---|---|---|---|
| 1 | Histogram | 1 | Categorical |
| 2 | Box plot | 1 | Categorical |
| 3 | Scatter plot | 2 | All continuous |
| 4 | Line plot | 2 | All continuous |
| 5 | Bar plot | 2 | Categorical x Continuous |
| 6 | Dot plot | 2 | Categorical x Continuous |
| 7 | Pair plot | >2 | Any |
| 8 | Heatmap | >2 | Continuous |
| 9 | Parallel coordinates | >2 | Continuous |
| 10 | Pie chart | 1 | Categorical |
Bonus: เพิ่มตัวแปรใน Data Viz อย่างง่าย ๆ
เราสามารถใช้ 4 สิ่งเหล่านี้ เพื่อเพิ่มตัวแปรที่ 3 เข้าไปใน data viz สำหรับ 2 ตัวแปรได้:
- สี (colour)
- ขนาด (size)
- ความโปร่งใส (transparency)
- รูปทรง (shape)
มาดูตัวอย่างกัน:
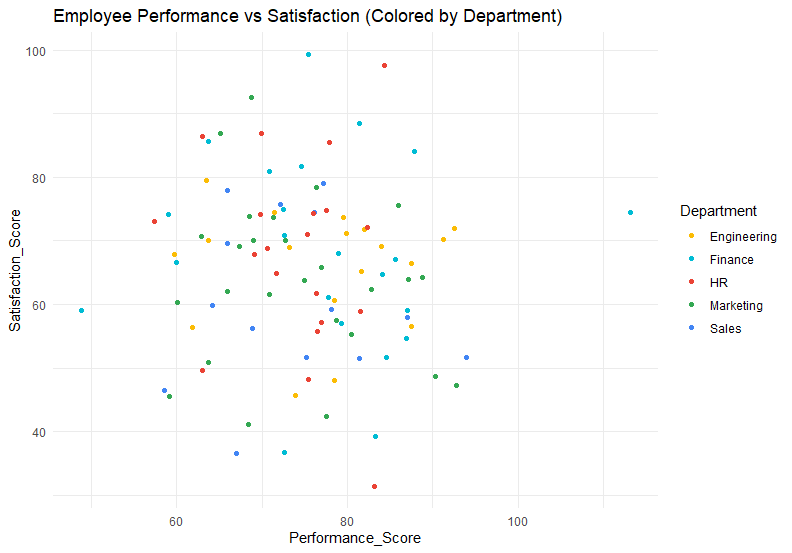
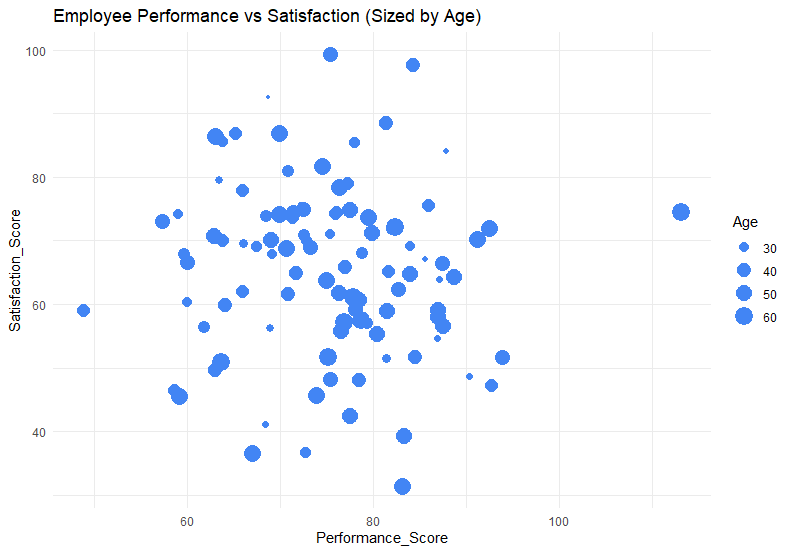
ความสัมพันธ์ระหว่างความพึงพอใจและประสิทธิภาพในการทำงาน โดยแบ่งตามแผนก
1. แบ่งแผนกด้วยสี
2. แบ่งแผนกด้วยขนาด
3. แบ่งแผนกด้วยความโปร่งใส
4. แบ่งแผนกด้วยรูปทรง
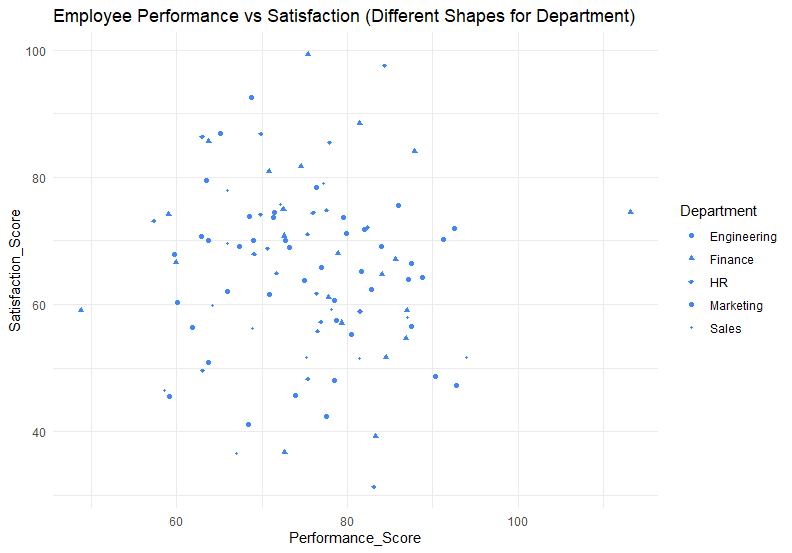
Note: จากตัวอย่างเราจะเห็นว่า การใช้สีเป็นวิธีนำเสนอตัวแปรที่สามได้ดีที่สุด ในขณะที่ขนาด ความโปร่งใส และรูปทรง