
ในบทความนี้ เราจะมาทำความรู้จักและสร้าง tree-based models ในภาษา R กัน:
- Classification tree
- Random forest
ถ้าพร้อมแล้ว ไปเริ่มกันเลย
🌳 Tree-Based Algorithms คืออะไร?
Tree-based algorithm เป็น machine learning algorithm ประเภท supervised learning ที่ทำนายข้อมูลโดยใช้ decision tree
Decision tree เป็นเครื่องมือช่วยตัดสินใจที่ดูคล้ายกับต้นไม้กลับหัว เพราะประกอบด้วยจุดตัดสินใจ (node) ที่แตกยอด (ทางเลือก) ออกไปเรื่อย ๆ เพื่อใช้ทำนายผลลัพธ์ที่ต้องการ
ยกตัวอย่างเช่น เราอยากรู้ว่า เราควรจะสมัครงานกับบริษัทแห่งหนึ่งไหม เราอาจจะสร้าง decision tree จาก 3 ปัจจัย คือ:
- เงินเดือน
- ได้ใช้ทักษะที่มี
- การทำงานแบบ hybrid หรือ remote
ได้แบบนี้:

จาก decision tree ถ้าเราเห็นงานที่ได้เงินเดือนไม่ตรงใจ เราจะไม่สมัครงานนั้น (เส้นการตัดสินใจซ้ายสุด)
ในทางกลับกัน ถ้างานมีเงินเดือนที่น่าสนใจ และได้ใช้ทักษะที่มีอยู่ เราจะสมัครงานนั้น (เส้นการตัดสินใจขวาสุด) เป็นต้น
💻 Tree-Based Models ในภาษา R
ในภาษา R เราสามารถสร้าง tree-based model ได้ด้วย rpart() จาก rpart package:
# Install
install.packages("rpart")
# Load
library(rpart)
rpart() ต้องการ 4 arguments ดังนี้:
rpart(formula, data, method, control)
- formula = สูตรในการวิเคราะห์ (ตัวแปรตาม ~ ตัวแปรต้น)
- data = dataset ที่ใช้สร้าง model
- method = ประเภท algorithm (
"anova"สำหรับ regression และ"class"สำหรับ classification) - control (optional) = เงื่อนไขควบคุม “การเติบโต” ของ decision tree เช่น ระดับชั้นที่มีได้ เป็นต้น
(Note: ศึกษาการใช้งาน rpart() เพิ่มเติมได้ที่ rpart: Recursive Partitioning and Regression Trees)
เราไปดูตัวอย่างการใช้งาน rpart() กัน

.
🚗 Dataset: mtcars
ในบทความนี้ เราจะลองสร้าง tree-based model ประเภท classification หรือ classification tree เพื่อทำนายประเภทเกียร์รถใน mtcars dataset
mtcars เป็นชุดข้อมูลรถจาก ปี ค.ศ. 1974 ซึ่งประกอบไปด้วยข้อมูล เช่น รุ่นรถ น้ำหนัก ระดับการกินน้ำมัน แรงม้า เป็นต้น
เราสามารถโหลด mtcars มาใช้งานได้ด้วย data() และ preview ด้วย head():
# Load
data(mtcars)
# Preview
head(mtcars)
ตัวอย่างข้อมูล:
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 manual 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 manual 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 manual 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 automatic 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 automatic 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 automatic 3 1
.
🔧 Prepare the Data
ก่อนนำ mtcars ไปใช้สร้าง classification tree เราจะต้องทำ 2 อย่างก่อน:
อย่างที่ #1. ปรับ column am ให้เป็น factor เพราะสิ่งที่เราต้องการทำนายเป็น categorical data:
# Convert `am` to factor
mtcars$am <- factor(mtcars$am,
levels = c(0, 1),
labels = c("automatic", "manual"))
# Check the result
class(mtcars$am)
ผลลัพธ์:
[1] "factor"
อย่างที่ #2. Split ข้อมูลเป็น 2 ชุด:
- Training set สำหรับสร้าง model
- Test set สำหรับประเมิน model
# Set seed for reproducibility
set.seed(500)
# Get training index
train_index <- sample(nrow(mtcars),
nrow(mtcars) * 0.7)
# Split the data
train_set <- mtcars[train_index, ]
test_set <- mtcars[-train_index, ]
.
🪴 Train the Model
ตอนนี้ เราพร้อมที่จะสร้าง classification tree ด้วย rpart() แล้ว
สำหรับ classification tree ในบทความนี้ เราจะลองตั้งเงื่อนไขในการปลูกต้นไม้ (control) ดังนี้:
| Argument | Explanation |
|---|---|
cp = 0 | คะแนนประสิทธิภาพขั้นต่ำ ก่อนจะแตกกิ่งใหม่ได้ = 0 |
minsplit = 1 | จำนวนกิ่งย่อยขั้นต่ำที่ต้องมี ก่อนจะแตกกิ่งใหม่ได้ = 1 |
maxdepth = 5 | จำนวนชั้นที่ decision tree มีได้สูงสุด = 5 |
# Classification tree
ct <- rpart(am ~ .,
data = train_set,
method = "class",
control = rpart.control(cp = 0, minsplit = 1, maxdepth = 5))
เราสามารถดู classification tree ของเราได้ด้วย rpart.plot():
# Plot classification tree
rpart.plot(ct,
type = 3,
extra = 101,
under = TRUE,
digits = 3,
tweak = 1.2)
ผลลัพธ์:
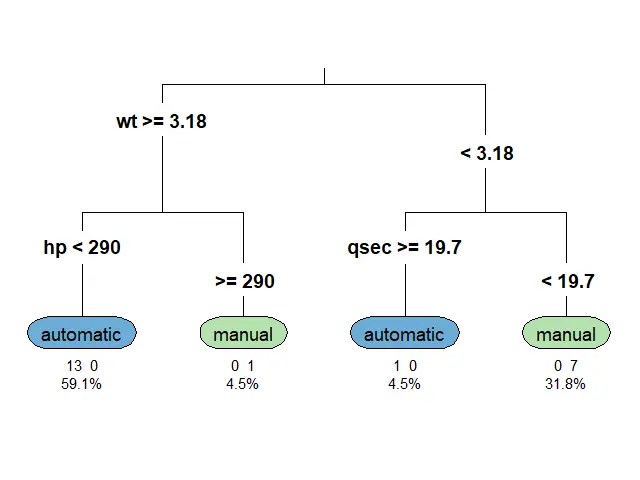
Note:
- ก่อนใช้งาน
rpart.plot()เราต้องจะติดตั้งและเรียกใช้งานด้วยinstall.packages()และlibrary()ตามลำดับ - ศึกษาการใช้งาน
rpart.plot()เพิ่มเติมได้ที่ rpart.plot: Plot an rpart model. A simplified interface to the prp function.
.
📏 Evaluate the Model
เมื่อได้ classification tree มาแล้ว เราลองมาประเมินความสามารถของ model ด้วย accuracy หรือสัดส่วนการทำนายที่ถูกต้องกัน
เราเริ่มจากใช้ predict() เพื่อใช้ model ทำนายประเภทเกียร์:
# Predict the outcome
test_set$pred_ct <- predict(ct,
newdata = test_set,
type = "class")
จากนั้น สร้าง confusion matrix หรือ matrix เปรียบเทียบคำทำนายกับข้อมูลจริง:
# Create a confusion matrix
cm_ct <- table(Predicted = test_set$pred_ct,
Actual = test_set$am)
# Print confusion matrix
print(cm_ct)
ผลลัพธ์:
Actual
Predicted automatic manual
automatic 5 1
manual 0 4
สุดท้าย เราหา accuracy ด้วยการนำจำนวนคำทำนายที่ถูกต้องมาหารด้วยจำนวนคำทำนายทั้งหมด:
# Get accuracy
acc_ct <- sum(diag(cm_ct)) / sum(cm_ct)
# Print accuracy
cat("Accuracy (classification tree):", acc_ct)
ผลลัพธ์:
Accuracy (classification tree): 0.9
จะเห็นได้ว่า model ของเรามีความแม่นยำถึง 90%
🍄 Random Forest
Random forest เป็น tree-based algorithm ที่ช่วยเพิ่มความแม่นยำในการทำนาย โดยสุ่มสร้าง decision trees ต้นเล็กขึ้นมาเป็นกลุ่ม (forest) แทนการปลูก decision tree ต้นเดียว

Decision tree แต่ละต้นใน random forest มีความสามารถในการทำนายแตกต่างกัน ซึ่งบางต้นอาจมีความสามารถที่น้อยมาก
แต่จุดแข็งของ random forest อยู่ที่จำนวน โดย random forest ทำนายผลลัพธ์โดยดูจากผลลัพธ์ในภาพรวม ดังนี้:
| Task | Predict by |
|---|---|
| Regression | ค่าเฉลี่ยของผลลัพธ์การทำนายของทุกต้น |
| Classification | เสียงส่วนมาก (majority vote) |
ดังนั้น แม้ว่า decision tree บางต้นอาจทำนายผิดพลาด แต่โดยรวมแล้ว random forest มีโอกาสที่จะทำนายได้ดีกว่า decision tree ต้นเดียว
ในภาษา R เราสามารถสร้าง random forest ได้ด้วย randomForest() จาก randomForest package ซึ่งต้องการ 3 arguments:
randomFrest(formula, data, ntree)
- formula = สูตรในการวิเคราะห์ (ตัวแปรตาม ~ ตัวแปรต้น)
- data = dataset ที่ใช้สร้าง model
- ntree = จำนวน decision trees ที่ต้องการสร้าง
Note:
- เราไม่ต้องกำหนดว่า จะทำ classification หรือ regression model เพราะ
randomForest()จะเลือก model ให้อัตโนมัติตามข้อมูลที่เราใส่เข้าไป - ศึกษาการใช้งาน
randomForest()เพิ่มเติมได้ที่ randomForest: Classification and Regression with Random Forest
ก่อนใช้ randomForest() เราต้องเตรียมข้อมูลแบบเดียวกันกับ rpart() ได้แก่:
- เปลี่ยน
amให้เป็น factor - Split the data
สมมุติว่า เราเตรียมข้อมูลแล้ว เราสามารถเรียกใช้ randomForest() ได้เลย โดยเราจะลองสร้าง random forest ที่ประกอบด้วย decision trees 100 ต้น:
# Random forest
rf <- randomForest(am ~ .,
data = train_set,
ntree = 100)
แล้วลองประเมินความสามารถของ model ด้วย accuracy
เริ่มจากทำนายประเภทเกียร์:
# Predict the outcome
test_set$pred_rf <- predict(rf,
newdata = test_set,
type = "class")
สร้าง confusion matrix:
# Create a confusion matrix
cm_rf <- table(Predicted = test_set$pred_rf,
Actual = test_set$am)
# Print confusion matrix
print(cm_rf)
ผลลัพธ์:
Actual
Predicted automatic manual
automatic 5 0
manual 0 5
และสุดท้าย คำนวณ accuracy:
# Get accuracy
acc_rf <- sum(diag(cm_rf)) / sum(cm_rf)
# Print accuracy
cat("Accuracy (random forest):", acc_rf)
ผลลัพธ์:
Accuracy (random forest): 1
จะเห็นว่า random forest (100%) มีความแม่นยำในการทำนายมากกว่า classification tree ต้นเดียว (90%)
🐱 GitHub
ดู code ทั้งหมดในบทความนี้ได้ที่ GitHub:
📃 References
- Supervised Learning in R: Classification
- Tree-Based Models in R
- Tree Based Machine Learning Algorithms
- Decision tree
✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
📕 ขอฝากหนังสือเล่มแรกในชีวิตด้วยนะครับ 😆
🙋 ใครที่กำลังเรียนจิตวิทยาหรือทำงานสายจิตวิทยา และเบื่อที่ต้องใช้ software ราคาแพงอย่าง SPSS และ Excel เพื่อทำข้อมูล
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
- Correlation
- t-tests
- ANOVA
- Reliability
- Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
แล้วทุกคนจะแปลกใจว่า ทำไมภาษา R ง่ายขนาดนี้ 🙂↕️
👉 สนใจดูรายละเอียดหนังสือได้ที่ meb:
