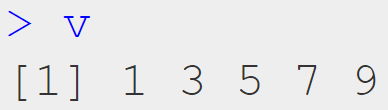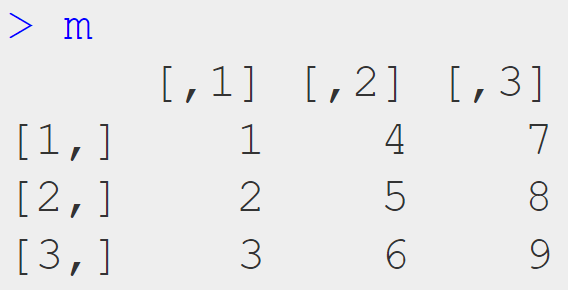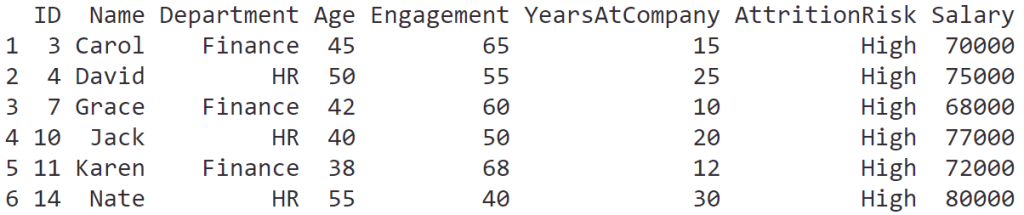R ได้ชื่อว่าเป็น “statistical programming language” เพราะออกแบบมาเพื่อทำงานกับ data โดยเฉพาะ
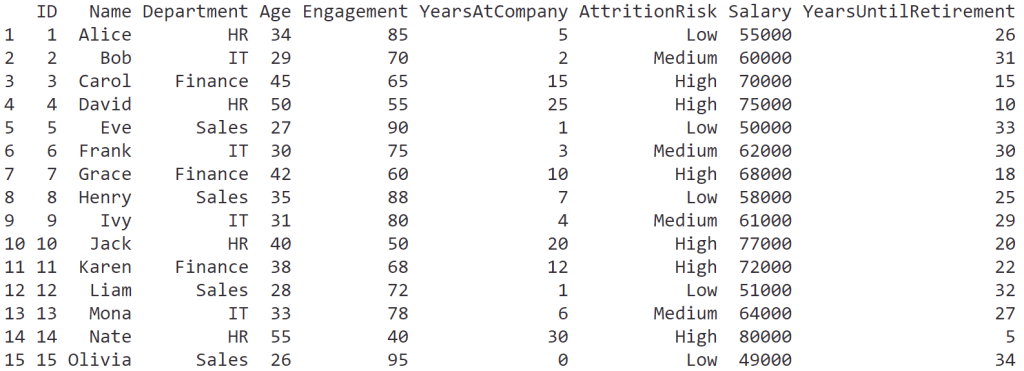
ภาษา R มี packages มากมายที่รองรับการทำงานกับ data ในรูปแบบตาราง (tabular data) หรือ data frame อย่างตัวอย่างในภาพ:
หนึ่งใน packages ที่ได้รับความนิยมในการทำงานกับ data frame โดยเฉพาะงาน data science ได้แก่ data.table
data.table เป็น package สำหรับ data manipulation ที่มีจุดเด่น 3 อย่าง คือ:
- ใช้งานง่าย (แม้จะมีการเขียนที่แตกต่างจาก functions ทั่วไป แต่มี syntax ที่ตายตัว)
- ประมวลผลเร็วและประหยัด resource เพราะ
data.tableoptimises code ที่เราเขียน - รองรับการทำงานกับ data ขนาดใหญ่ (เช่น data ที่ใช้ RAM ขนาด 10 ถึง 100 GB ในการประมวลผล)
ในบทความนี้ เราจะมาดูวิธีการใช้งาน data.table แบบครบจบใน 3 ส่วนกัน:
- การใช้งาน
data.tableเบื้องต้น (syntax และ arguments) - การใช้งาน
data.tableขั้นสูง (combining และ chaining) - Special symbols ใน
data.table
ถ้าพร้อมแล้ว มาเริ่มกันเลย
- 🏁 Get Started With data.table
- ✈️ Example Dataset: flights
- ✍️ Syntax: DT[i, j, by]
- 🍦 1st Argument: i
- 🧮 2nd Argument: j
- 🤝 3rd Argument: by
- 🔗 Combining & Chaining
- 🍩 Special Symbols
- 😎 Conclusion
- 🎒 Learn More About data.table
- 📃 References
- ✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
🏁 Get Started With data.table
ในการเริ่มต้นใช้งาน data.table เราจะต้องทำ 2 อย่าง ได้แก่:
- ติดตั้ง
data.table(ทำครั้งแรกครั้งเดียว) - โหลด
data.table(ทำทุกครั้งที่เริ่ม session ใหม่)
# Install data.table
install.packages("data.table")
# Load data.table
library(data.table)
เมื่อทำทั้ง 2 อย่างนี้แล้ว เราก็พร้อมที่จะใช้งาน data.table กันแล้ว
✈️ Example Dataset: flights

1️⃣ Intro to flights
ในบทความนี้ เราจะมาดูตัวอย่างการใช้ data.table กับ flights ซึ่งมีข้อมูลเที่ยวบินที่ออกจาก New York City ในปี ค.ศ. 2014 เช่น:
- วันที่
- สนามบินต้นทางและปลายทาง
- ระยะเวลาที่เที่ยวบิน delay
- ระยะเวลาบิน
- ระยะทาง
Note: ดูรายละเอียดทั้งหมดของ dataset ได้ที่ GitHub
.
2️⃣ Get flights
เราสามารถเริ่มใช้งาน flights ใน 2 ขั้นตอน:
ขั้นที่ 1. Download ไฟล์จาก link โดยไฟล์ที่ได้จะเป็น CSV (comma-separated values):
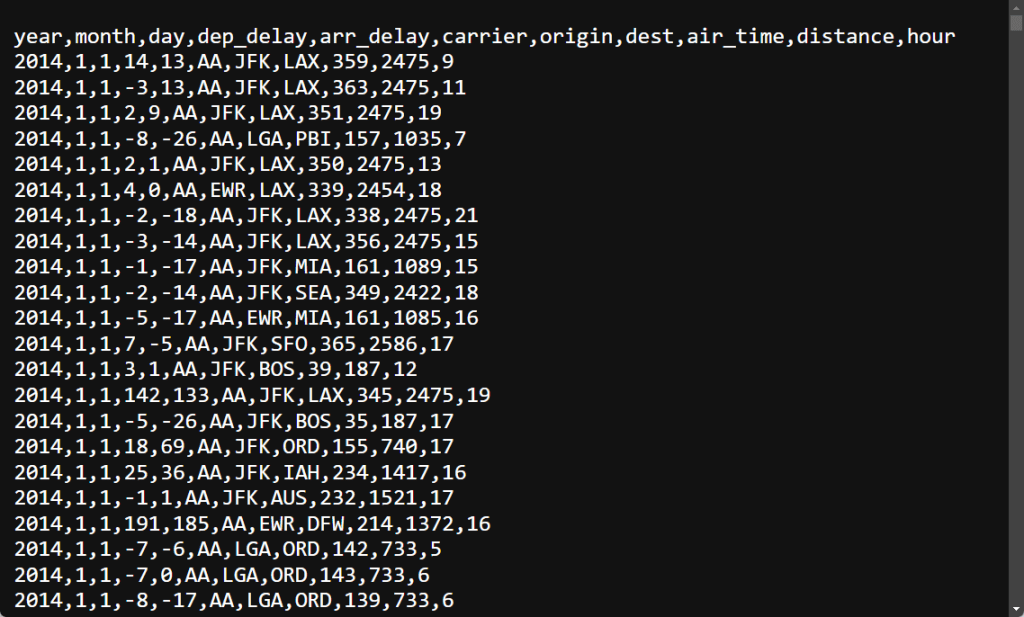
ขั้นที่ 2. Import ข้อมูลเข้าใน R ด้วย fread() (”fast read”) ซึ่งเป็น function สำหรับโหลดข้อมูลของ data.table:
# Import the dataset
flights <- fread("flights14.csv")
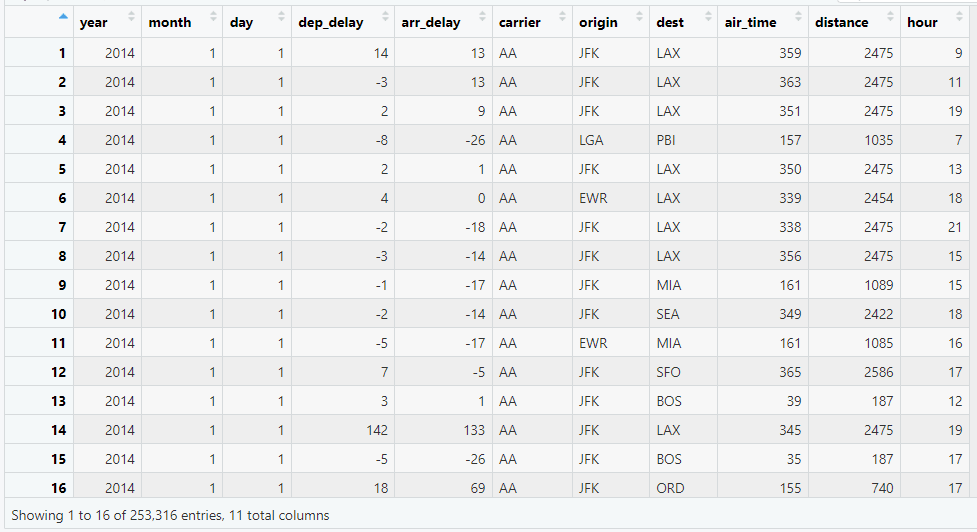
เราสามารถดูตัวอย่างข้อมูลได้ด้วย head():
# Preview the dataset
head(flights)
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 14 13 AA JFK LAX 359 2475 9
2: 2014 1 1 -3 13 AA JFK LAX 363 2475 11
3: 2014 1 1 2 9 AA JFK LAX 351 2475 19
4: 2014 1 1 -8 -26 AA LGA PBI 157 1035 7
5: 2014 1 1 2 1 AA JFK LAX 350 2475 13
6: 2014 1 1 4 0 AA EWR LAX 339 2454 18
✍️ Syntax: DT[i, j, by]
การใช้งาน data.table ประกอบด้วย 4 ส่วน ดังนี้:
DT[i, j, by]
- DT คือ dataset ที่เราต้องการใช้งาน
- i ใช้ทำงานกับ rows
- j ใช้ทำงานกับ columns
- by ใช้จับกลุ่มข้อมูล
เราไปดูรายละเอียดการใช้งาน i, j, และ by กัน
🍦 1st Argument: i
เราสามารถใช้งาน i ได้ 3 อย่าง:
- Select rows: เลือก rows ที่ต้องการ
- Filter: กรองข้อมูล
- Sort: จัดลำดับข้อมูล

.
1️⃣ Select Rows
เราสามารถใช้ i เพื่อเลือก rows ได้ 3 แบบ:
- เลือก 1 row
- เลือกหลาย rows
- คัด rows ที่ไม่ต้องการออก
.
แบบที่ #1. เลือก 1 row
เช่น เลือก row ที่ 5 จาก flights:
# Select a row
flights[5]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 2 1 AA JFK LAX 350 2475 13
.
แบบที่ #2 – เลือกหลาย rows
ซึ่งเราทำได้โดยการใช้ vector เช่น เลือก rows 1 ถึง 10:
# Select a range of rows
flights[1:10]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 14 13 AA JFK LAX 359 2475 9
2: 2014 1 1 -3 13 AA JFK LAX 363 2475 11
3: 2014 1 1 2 9 AA JFK LAX 351 2475 19
4: 2014 1 1 -8 -26 AA LGA PBI 157 1035 7
5: 2014 1 1 2 1 AA JFK LAX 350 2475 13
6: 2014 1 1 4 0 AA EWR LAX 339 2454 18
7: 2014 1 1 -2 -18 AA JFK LAX 338 2475 21
8: 2014 1 1 -3 -14 AA JFK LAX 356 2475 15
9: 2014 1 1 -1 -17 AA JFK MIA 161 1089 15
10: 2014 1 1 -2 -14 AA JFK SEA 349 2422 18
หรือเลือก rows 1, 3, 5, 7, และ 9:
# Select multiple rows at interval
flights[c(1, 3, 5, 7, 9)]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 14 13 AA JFK LAX 359 2475 9
2: 2014 1 1 2 9 AA JFK LAX 351 2475 19
3: 2014 1 1 2 1 AA JFK LAX 350 2475 13
4: 2014 1 1 -2 -18 AA JFK LAX 338 2475 21
5: 2014 1 1 -1 -17 AA JFK MIA 161 1089 15
.
แบบที่ #3 – คัด rows ที่ไม่ต้องการออก
ซึ่งเราสามารถทำได้ 2 แบบ คือ:
- ใช้
- - ใช้
!
เช่น คัด row ที่ 1 ออก โดยใช้ -:
# Deselect a row
flights[-1]
หรือใช้ !:
# Deselect a row
flights[!1]
โดยทั้งสองแบบจะให้ผลลัพธ์แบบเดียวกัน แบบนี้:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 -3 13 AA JFK LAX 363 2475 11
2: 2014 1 1 2 9 AA JFK LAX 351 2475 19
3: 2014 1 1 -8 -26 AA LGA PBI 157 1035 7
4: 2014 1 1 2 1 AA JFK LAX 350 2475 13
5: 2014 1 1 4 0 AA EWR LAX 339 2454 18
---
253311: 2014 10 31 1 -30 UA LGA IAH 201 1416 14
253312: 2014 10 31 -5 -14 UA EWR IAH 189 1400 8
253313: 2014 10 31 -8 16 MQ LGA RDU 83 431 11
253314: 2014 10 31 -4 15 MQ LGA DTW 75 502 11
253315: 2014 10 31 -5 1 MQ LGA SDF 110 659 8
.
2️⃣ Filter
นอกจากการเลือก rows เรายังสามารถใช้ i เพื่อกรอง data ได้ 3 แบบ:
- กรองโดยใช้ 1 เงื่อนไข
- กรองโดยใช้หลายเงื่อนไข
- กรองโดยใช้ helpers
.
แบบที่ #1 – กรองข้อมูลโดยใช้ 1 เงื่อนไข
เช่น กรอง rows ที่มีระยะทางบิน 500 miles ขึ้นไป:
# Filter with 1 condition
flights[distance >= 500]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 14 13 AA JFK LAX 359 2475 9
2: 2014 1 1 -3 13 AA JFK LAX 363 2475 11
3: 2014 1 1 2 9 AA JFK LAX 351 2475 19
4: 2014 1 1 -8 -26 AA LGA PBI 157 1035 7
5: 2014 1 1 2 1 AA JFK LAX 350 2475 13
---
198323: 2014 10 31 18 -14 UA EWR LAS 291 2227 16
198324: 2014 10 31 1 -30 UA LGA IAH 201 1416 14
198325: 2014 10 31 -5 -14 UA EWR IAH 189 1400 8
198326: 2014 10 31 -4 15 MQ LGA DTW 75 502 11
198327: 2014 10 31 -5 1 MQ LGA SDF 110 659 8
.
แบบที่ #2 – กรองข้อมูลด้วยหลายเงื่อนไข
เราสามารถเพิ่มเงื่อนไขการกรองได้ด้วย logical operators:
| Operator | Meaning |
|---|---|
& | AND |
| | OR |
! | NOT |
เช่น กรอง rows ที่:
- มีระยะทางบิน 500 miles ขึ้นไป และ
- ออกจากสนามบิน LaGuardia (
LGA):
# Filter with multiple conditions
flights[distance >= 500 & origin == "LGA"]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 -8 -26 AA LGA PBI 157 1035 7
2: 2014 1 1 -7 -6 AA LGA ORD 142 733 5
3: 2014 1 1 -7 0 AA LGA ORD 143 733 6
4: 2014 1 1 -8 -17 AA LGA ORD 139 733 6
5: 2014 1 1 -2 15 AA LGA ORD 145 733 7
---
63251: 2014 10 31 14 -17 UA LGA IAH 200 1416 17
63252: 2014 10 31 24 -5 UA LGA IAH 198 1416 6
63253: 2014 10 31 1 -30 UA LGA IAH 201 1416 14
63254: 2014 10 31 -4 15 MQ LGA DTW 75 502 11
63255: 2014 10 31 -5 1 MQ LGA SDF 110 659 8
.
แบบที่ #3 – กรองโดยใช้ helpers
เราสามารถกรองข้อมูลโดยใช้ helpers หรือ operators พิเศษ 3 อย่างนี้:
| Helper | For | Syntax |
|---|---|---|
%between% | กรองข้อมูลตาม range | col %between% range |
%like% | กรองข้อมูลตาม text pattern | col %like% pattern |
%chin% | กรองข้อมูลอยู่ใน set ที่กำหนด | col %chin% set |
ตัวอย่าง:
ใช้ %between% เพื่อกรองข้อมูลที่มีระยะทางบินระหว่าง 500 ถึง 1,000 miles:
# Filter using %between%
flights[distance %between% c(500, 1000)]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 18 69 AA JFK ORD 155 740 17
2: 2014 1 1 -7 -6 AA LGA ORD 142 733 5
3: 2014 1 1 -7 0 AA LGA ORD 143 733 6
4: 2014 1 1 -8 -17 AA LGA ORD 139 733 6
5: 2014 1 1 -2 15 AA LGA ORD 145 733 7
---
79754: 2014 10 31 10 -5 UA EWR ORD 110 719 6
79755: 2014 10 31 5 2 UA EWR ORD 132 719 10
79756: 2014 10 31 427 393 UA EWR ORD 100 719 21
79757: 2014 10 31 -4 15 MQ LGA DTW 75 502 11
79758: 2014 10 31 -5 1 MQ LGA SDF 110 659 8
Note: code นี้ให้ผลลัพธ์เดียวกับการเขียน flights[distance >= 500 & distance <= 1000] แต่การใช้ %between% ทำให้ code สั้นและอ่านง่ายกว่า
.
ใช้ %like% เพื่อกรองข้อมูลที่สนามบินปลายทางขึ้นต้นด้วย “A” เช่น “ABQ”, “ACK”, “AGS”:
# Filter using %like%
flights[dest %like% "^A"]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 -1 1 AA JFK AUS 232 1521 17
2: 2014 1 1 -5 16 B6 JFK AUS 247 1521 20
3: 2014 1 1 21 21 B6 JFK AUS 237 1521 9
4: 2014 1 1 10 4 B6 JFK ABQ 280 1826 20
5: 2014 1 1 10 10 DL LGA ATL 126 762 18
---
15630: 2014 10 31 50 43 UA EWR ATL 113 746 15
15631: 2014 10 31 -5 -38 UA EWR ATL 111 746 5
15632: 2014 10 31 -5 -2 UA EWR AUS 211 1504 15
15633: 2014 10 31 -9 -15 UA EWR ATL 119 746 11
15634: 2014 10 31 11 -10 UA EWR ATL 109 746 8
ใช้ %chin% เพื่อกรองข้อมูลที่สนามบินปลายทาง คือ ATL, LAX, หรือ ORD:
# Filter using %chin%
flights[dest %chin% c("ATL", "LAX", "ORD")]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 14 13 AA JFK LAX 359 2475 9
2: 2014 1 1 -3 13 AA JFK LAX 363 2475 11
3: 2014 1 1 2 9 AA JFK LAX 351 2475 19
4: 2014 1 1 2 1 AA JFK LAX 350 2475 13
5: 2014 1 1 4 0 AA EWR LAX 339 2454 18
---
38827: 2014 10 31 10 -5 UA EWR ORD 110 719 6
38828: 2014 10 31 3 -32 UA EWR LAX 320 2454 20
38829: 2014 10 31 5 2 UA EWR ORD 132 719 10
38830: 2014 10 31 427 393 UA EWR ORD 100 719 21
38831: 2014 10 31 10 -27 UA EWR LAX 326 2454 10
.
3️⃣ Sort
สุดท้าย เราสามารถใช้ i เพื่อเรียงลำดับข้อมูลได้ 3 แบบ:
- Sort ascending (A—Z)
- Sort descending (Z—A)
- Sort by multiple columns
.
แบบที่ #1 – Sort ascending
เช่น จัดเรียงตามชื่อสนามบินต้นทาง จาก A—Z:
# Sort ascending
flights[order(origin)]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 4 0 AA EWR LAX 339 2454 18
2: 2014 1 1 -5 -17 AA EWR MIA 161 1085 16
3: 2014 1 1 191 185 AA EWR DFW 214 1372 16
4: 2014 1 1 -1 -2 AA EWR DFW 214 1372 14
5: 2014 1 1 -3 -10 AA EWR MIA 154 1085 6
---
253312: 2014 10 31 24 -5 UA LGA IAH 198 1416 6
253313: 2014 10 31 1 -30 UA LGA IAH 201 1416 14
253314: 2014 10 31 -8 16 MQ LGA RDU 83 431 11
253315: 2014 10 31 -4 15 MQ LGA DTW 75 502 11
253316: 2014 10 31 -5 1 MQ LGA SDF 110 659 8
.
แบบที่ #2 – Sorting descending
เราเรียงข้อมูลแบบ descending (Z—A) ได้ 2 วิธี:
- ใช้
decreasing = TRUE - ใช้
-
เช่น จัดเรียงตามชื่อสนามบินต้นทาง จาก Z-A โดยใช้ decreasing = TRUE:
# Sort descending with decreasing = TRUE
flights[order(origin, decreasing = TRUE)]
หรือโดยใช้ -:
# Sort descending with -
flights[order(-origin)]
เราจะได้ผลลัพธ์แบบเดียวกัน:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 -8 -26 AA LGA PBI 157 1035 7
2: 2014 1 1 -7 -6 AA LGA ORD 142 733 5
3: 2014 1 1 -7 0 AA LGA ORD 143 733 6
4: 2014 1 1 -8 -17 AA LGA ORD 139 733 6
5: 2014 1 1 -2 15 AA LGA ORD 145 733 7
---
253312: 2014 10 31 41 19 UA EWR SFO 344 2565 12
253313: 2014 10 31 427 393 UA EWR ORD 100 719 21
253314: 2014 10 31 10 -27 UA EWR LAX 326 2454 10
253315: 2014 10 31 18 -14 UA EWR LAS 291 2227 16
253316: 2014 10 31 -5 -14 UA EWR IAH 189 1400 8
.
แบบที่ #3 – Sort by multiple columns
เช่น จัดเรียงตามชื่อสนามบินต้นทางและปลายทาง ตามลำดับ:
# Sort by multiple columns
flights[order(origin, dest)]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 2 -2 -25 EV EWR ALB 30 143 7
2: 2014 1 3 88 79 EV EWR ALB 29 143 23
3: 2014 1 4 220 211 EV EWR ALB 32 143 15
4: 2014 1 4 35 19 EV EWR ALB 32 143 7
5: 2014 1 5 47 42 EV EWR ALB 26 143 8
---
253312: 2014 10 29 0 9 MQ LGA XNA 174 1147 6
253313: 2014 10 29 -5 -16 MQ LGA XNA 162 1147 14
253314: 2014 10 30 -4 -23 MQ LGA XNA 154 1147 6
253315: 2014 10 30 -7 -11 MQ LGA XNA 157 1147 14
253316: 2014 10 31 -5 -11 MQ LGA XNA 165 1147 6
🧮 2nd Argument: j
เราสามารถใช้ j เพื่อทำงานได้ 3 อย่าง ได้แก่:
- Select columns: เลือก columns ที่ต้องการ
- Compute: วิเคราะห์ข้อมูล
- Create columns: สร้าง columns ใหม่

.
1️⃣ Select Columns
เราสามารถใช้ j เพื่อเลือก columns ได้ 3 แบบ:
- เลือก 1 column
- เลือกหลาย columns
- คัด columns ที่ไม่ต้องการออก
.
แบบที่ #1 – เลือก 1 column
เช่น เลือก column สนามบินต้นทาง:
# Select a column
flights[, "origin"]
ผลลัพธ์:
origin
<char>
1: JFK
2: JFK
3: JFK
4: LGA
5: JFK
---
253312: LGA
253313: EWR
253314: LGA
253315: LGA
253316: LGA
Note: เราสามารถใช้ตำแหน่ง (1, 2, 3, …) แทนชื่อ columns ("origin") ได้ แต่ไม่เป็นที่นิยม เพราะ columns อาจขยับตำแหน่งได้ และทำให้ผลลัพธ์เปลี่ยนไปได้
.
แบบที่ #2 – เลือกหลาย columns
เราใช้ j เพื่อเลือกหลาย columns ได้ 3 วิธี:
- Vector
- List หรือ
.() ..
เช่น เลือก 3 columns คือ:
- สนามบินต้นทาง
- สนามบินปลายทาง
- ระยะเวลาบิน
โดยใช้ vector:
# Select multiple columns with a vector
flights[, c("origin", "dest", "air_time")]
ผลลัพธ์:
origin dest air_time
<char> <char> <int>
1: JFK LAX 359
2: JFK LAX 363
3: JFK LAX 351
4: LGA PBI 157
5: JFK LAX 350
---
253312: LGA IAH 201
253313: EWR IAH 189
253314: LGA RDU 83
253315: LGA DTW 75
253316: LGA SDF 110
โดยใช้ list:
# Select multiple columns with a list
flights[, list(origin, dest, air_time)]
หรือใช้ .() ซึ่งเป็น shorthand สำหรับ list:
# Select multiple columns using .()
flights[, .(origin, dest, air_time)]
ผลลัพธ์:
origin dest air_time
<char> <char> <int>
1: JFK LAX 359
2: JFK LAX 363
3: JFK LAX 351
4: LGA PBI 157
5: JFK LAX 350
---
253312: LGA IAH 201
253313: EWR IAH 189
253314: LGA RDU 83
253315: LGA DTW 75
253316: LGA SDF 110
โดยใช้ .. ซึ่งเรามักใช้วิธีนี้เมื่อต้องการเลือก columns แบบ dynamic:
# Select multiple columns using ..
## Create a vector of column names
cols <- c("origin", "dest", "air_time")
## Select using ..
flights[, ..cols]
ผลลัพธ์:
origin dest air_time
<char> <char> <int>
1: JFK LAX 359
2: JFK LAX 363
3: JFK LAX 351
4: LGA PBI 157
5: JFK LAX 350
---
253312: LGA IAH 201
253313: EWR IAH 189
253314: LGA RDU 83
253315: LGA DTW 75
253316: LGA SDF 110
Note: ความแตกต่างระหว่าง vector และ list หรือ .() และ .. คือ:
- vector ให้ผลลัพธ์ที่เป็น vector
- List หรือ
.()และ..ให้ผลลัพธ์เป็นdata.table(data frame ของdata.table)
.
แบบที่ #3 – คัด columns ที่ไม่ต้องการออก
เราสามารถคัด columns ที่ไม่ต้องการออกได้ 2 วิธี:
- ใช้
- - ใช้
!
เช่น เอาชื่อสายการบินออก โดยใช้ -:
# Deselect a column using -
flights[, -c("carrier")]
หรือใช้ !:
# Deselect a column using !
flights[, !c("carrier")]
ผลลัพธ์:
year month day dep_delay arr_delay origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <int> <int> <int>
1: 2014 1 1 14 13 JFK LAX 359 2475 9
2: 2014 1 1 -3 13 JFK LAX 363 2475 11
3: 2014 1 1 2 9 JFK LAX 351 2475 19
4: 2014 1 1 -8 -26 LGA PBI 157 1035 7
5: 2014 1 1 2 1 JFK LAX 350 2475 13
---
253312: 2014 10 31 1 -30 LGA IAH 201 1416 14
253313: 2014 10 31 -5 -14 EWR IAH 189 1400 8
253314: 2014 10 31 -8 16 LGA RDU 83 431 11
253315: 2014 10 31 -4 15 LGA DTW 75 502 11
253316: 2014 10 31 -5 1 LGA SDF 110 659 8
.
2️⃣ Compute
นอกจากการเลือก columns เรายังสามารถใช้ j เพื่อวิเคราะห์หรือข้อมูล (summarise, aggregate) ได้
เช่น หาค่าเฉลี่ยของระยะเวลาบิน:
# Calculate mean
flights[, mean(air_time)]
ผลลัพธ์:
[1] 156.7228
หรือ หาค่าเฉลี่ย และ standard deviation (SD) ของระยะเวลาบิน:
# Calculate mean and SD
flights[, .(avg_air_time = mean(air_time),
sd_air_time = sd(air_time))]
ผลลัพธ์:
avg_air_time sd_air_time n
<num> <num> <int>
1: 156.7228 96.12978 253316
Note: เราสามารถวิเคราะห์ข้อมูลโดยไม่ตั้งชื่อให้กับผลลัพธ์ได้ (avg_air_time, sd_air_time, n) แต่การตั้งชื่อจะช่วยให้เราอ่าน output ได้ง่ายขึ้น
.
3️⃣ Create Columns
สุดท้าย เราสามารถใช้ j สร้าง columns ใหม่ได้ร่วมกับ:
:=สำหรับสร้าง 1 column`:=`สำหรับสร้างหลาย columns
เช่น สร้าง column ความเร็วในการบิน (ระยะทาง / เวลา) ด้วย :=:
# Creating 1 new column
flights[, speed := distance / (air_time / 60)]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour speed
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int> <num>
1: 2014 1 1 14 13 AA JFK LAX 359 2475 9 413.6490
2: 2014 1 1 -3 13 AA JFK LAX 363 2475 11 409.0909
3: 2014 1 1 2 9 AA JFK LAX 351 2475 19 423.0769
4: 2014 1 1 -8 -26 AA LGA PBI 157 1035 7 395.5414
5: 2014 1 1 2 1 AA JFK LAX 350 2475 13 424.2857
6: 2014 1 1 4 0 AA EWR LAX 339 2454 18 434.3363
Note:
- เราหาร
air_timeด้วย 60 เพื่อแปลงหน่วยจากนาทีเป็นชั่วโมง และทำให้ผลลัพธ์ที่ได้เป็นหน่วย miles/hour - สังเกตว่า column ใหม่จะอยู่ท้ายสุดของ
data.table
หรือ สร้าง 2 columns พร้อมกัน เช่น:
- ความเร็วในการบิน (ระยะทาง / เวลา)
- ระยะเวลาที่ delay โดยรวม (delay ขาออก + delay ขาเข้า)
ด้วย `:=`:
# Creating multiple new column
flights[, `:=`(speed = distance / (air_time / 60),
total_delay = dep_delay + arr_delay)]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour speed total_delay
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int> <num> <int>
1: 2014 1 1 14 13 AA JFK LAX 359 2475 9 413.6490 27
2: 2014 1 1 -3 13 AA JFK LAX 363 2475 11 409.0909 10
3: 2014 1 1 2 9 AA JFK LAX 351 2475 19 423.0769 11
4: 2014 1 1 -8 -26 AA LGA PBI 157 1035 7 395.5414 -34
5: 2014 1 1 2 1 AA JFK LAX 350 2475 13 424.2857 3
6: 2014 1 1 4 0 AA EWR LAX 339 2454 18 434.3363 4
🤝 3rd Argument: by
เราใช้ by เพื่อจับกลุ่มข้อมูล ซึ่งมีประโยชน์มากเวลาที่เราต้องการวิเคราะห์ข้อมูลเป็น ๆ กลุ่ม
เราสามารถใช้ by ได้ 2 แบบ:
- จับกลุ่มด้วย 1 column
- จับกลุ่มด้วยหลาย columns

.
แบบที่ #1 – จับกลุ่มด้วย 1 column
เช่น หาค่าเฉลี่ยของ delay ขาออก ตามชื่อสนามบินต้นทาง:
# Group by 1 column
flights[, mean(dep_delay), by = origin]
ผลลัพธ์:
origin V1
<char> <num>
1: JFK 11.44617
2: LGA 10.60500
3: EWR 15.21248
.
แบบที่ #2 – จับกลุ่มด้วยหลาย columns
เราจับกลุ่มด้วยหลาย columns ได้ด้วย 2 วิธี คือ:
- Vector
- List หรือ
.()
เช่น หาค่าเฉลี่ยของ delay ขาออก โดยจับกลุ่มตามชื่อสนามบินต้นทางและปลายทาง ตามลำดับ
วิธีที่ 1. ใช้ vector:
# Group by with a vector
flights[, mean(dep_delay), by = c("origin", "dest")]
ผลลัพธ์:
origin dest V1
<char> <char> <num>
1: JFK LAX 8.359718
2: LGA PBI 10.168617
3: EWR LAX 15.882631
4: JFK MIA 10.008364
5: JFK SEA 10.858953
---
217: LGA AVL -6.500000
218: LGA GSP 6.000000
219: LGA SBN 5.000000
220: EWR SBN -1.500000
221: LGA DAL -6.266667
วิธีที่ 2. ใช้ list:
# Group by with a list
flights[, mean(dep_delay), by = list(origin, dest)]
หรือใช้ .():
# Group by with .()
flights[, mean(dep_delay), by = .(origin, dest)]
ผลลัพธ์:
origin dest V1
<char> <char> <num>
1: JFK LAX 8.359718
2: LGA PBI 10.168617
3: EWR LAX 15.882631
4: JFK MIA 10.008364
5: JFK SEA 10.858953
---
217: LGA AVL -6.500000
218: LGA GSP 6.000000
219: LGA SBN 5.000000
220: EWR SBN -1.500000
221: LGA DAL -6.266667
Note: เช่นเดียวกับการเลือก columns …
- ถ้าเราใช้ vector เราจะได้ผลลัพธ์เป็น vector
- ถ้าใช้ list หรือ
.()เราจะได้data.table
🔗 Combining & Chaining
เราสามารถปลอดล็อกพลังที่แท้จริงของ data.table ได้ด้วย 2 วิธี:
- Combining: ใช้
i,j,byร่วมกัน เพื่อตอบโจทย์ที่ซับซ้อน - Chaining: เชื่อมต่อ
data.tableเข้าด้วยกัน
.
1️⃣ Combining
ยกตัวอย่างเช่น:
- หาค่าเฉลี่ยของความเร็ว
- เฉพาะเที่ยวบินที่มีระยะทางตั้งแต่ 500 miles ขึ้นไป
- โดยจับกลุ่มตามชื่อสนามบินต้นทาง:
# Combining
flights[distance >= 500,
.(avg_speed = mean(distance / (air_time / 60))),
by = origin]
อธิบาย code:
distance >= 500เลือกเฉพาะข้อมูลที่มีระยะทางตั้งแต่ 500 miles ขึ้นไป.(avg_speed = mean(distance / (air_time / 60)))หาค่าเฉลี่ยของความเร็วby = origin]จับกลุ่มข้อมูลด้วยสนามบินต้นทาง
ผลลัพธ์:
origin avg_speed
<char> <num>
1: JFK 436.6284
2: LGA 407.5462
3: EWR 417.1765
.
2️⃣ Chaining
Chaining คือ การนำ code มาต่อกัน เพื่อส่ง output ต่อกันเป็นทอด ๆ:
DT[...][...][...]
เช่น ค้นหาสนามบินปลายทาง 5 อันดับแรกที่มีค่าเฉลี่ย delay ขาเข้ามากที่สุด ในเดือนสิงหาคม:
# Chaining
flights[month == 8,
.(avg_arr_delay = mean(arr_delay)),
by = dest][order(-avg_arr_delay)][1:5]
อธิบาย code:
month == 8เลือกข้อมูลจากเดือนสิงหาคม.(avg_arr_delay = mean(arr_delay))คำนวณค่าเฉลี่ย delay ขาเข้าby = destจับกลุ่มตามสนามบินปลายทาง[order(-avg_arr_delay)]จัดลำดับตามค่าเฉลี่ย delay ขาเข้า แบบ descending[1:5]เลือกเฉพาะ 5 rows แรกมาแสดง
ผลลัพธ์:
dest avg_arr_delay
<char> <num>
1: LIT 37.06452
2: DSM 22.85714
3: CAK 19.60976
4: TYS 19.44681
5: TVC 19.00000
🍩 Special Symbols
เพื่อช่วยให้เราทำงานได้ง่ายขึ้น data.table มี special symbols 3 ตัวที่เราสามารถเรียกใช้ในการทำงานได้:
.N.SD.SDcols
.
1️⃣ .N
.N เป็น special symbol ที่เก็บจำนวน rows ของ data.table เอาไว้ (เช่น 500)
เรามักใช้งาน .N ใน 2 กรณีหลัก ๆ ได้แก่:
- เลือก rows
- นับจำนวนข้อมูล
.
กรณีที่ 1. เลือก rows
เช่น เลือก row ที่ 500 จนถึง row สุดท้าย:
# Select rows with .N
flights[500:.N]
ผลลัพธ์:
year month day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 2014 1 1 81 86 WN EWR HOU 222 1411 17
2: 2014 1 1 -3 -4 WN EWR MDW 128 711 7
3: 2014 1 1 0 22 WN EWR MDW 144 711 12
4: 2014 1 1 88 190 WN EWR MDW 130 711 21
5: 2014 1 1 45 63 WN EWR MDW 141 711 16
---
252813: 2014 10 31 1 -30 UA LGA IAH 201 1416 14
252814: 2014 10 31 -5 -14 UA EWR IAH 189 1400 8
252815: 2014 10 31 -8 16 MQ LGA RDU 83 431 11
252816: 2014 10 31 -4 15 MQ LGA DTW 75 502 11
252817: 2014 10 31 -5 1 MQ LGA SDF 110 659 8
.
กรณีที่ 2. นับจำนวนข้อมูล
เช่น นับจำนวนข้อมูลการบินตามสนามบินต้นทางแต่ละแห่ง:
# Compute with .N
flights[, .N, by = origin]
ผลลัพธ์:
origin N
<char> <int>
1: JFK 81483
2: LGA 84433
3: EWR 87400
.
2️⃣ .SD
.SD ย่อมาจาก “Subset of Data” ซึ่งหมายถึง ชุดข้อมูลย่อยที่เกิดจากการจับกลุ่มด้วย by
เรามักใช้ .SD ในการคำนวณคู่กับ lapply() function เพื่อวิเคราะห์ข้อมูลตามกลุ่ม
เช่น หาค่าสูงสุดของแต่ละ columns ในแต่ละเดือน:
# Compute with .SD
flights[,
lapply(.SD, max, na.rm = TRUE),
by = month]
ผลลัพธ์:
month year day dep_delay arr_delay carrier origin dest air_time distance hour
<int> <int> <int> <int> <int> <char> <char> <char> <int> <int> <int>
1: 1 2014 31 973 996 WN LGA XNA 688 4983 24
2: 2 2014 28 1014 1007 WN LGA XNA 685 4983 24
3: 3 2014 31 920 925 WN LGA XNA 706 4983 24
4: 4 2014 30 1241 1223 WN LGA XNA 664 4983 24
5: 5 2014 31 889 879 WN LGA XNA 650 4983 24
6: 6 2014 30 1071 1073 WN LGA XNA 640 4983 24
7: 7 2014 31 1087 1090 WN LGA XNA 638 4983 24
8: 8 2014 31 978 964 WN LGA XNA 635 4983 24
9: 9 2014 30 1056 1115 WN LGA XNA 635 4983 23
10: 10 2014 31 1498 1494 WN LGA XNA 662 4983 24
.
3️⃣ .SDcols
.SDcols เป็น special symbol ที่เก็บชื่อ columns ของ .SD เอาไว้
เรามักใช้ .SDcols คู่กับ .SD และ lapply() เพื่อวิเคราะห์เฉพาะ columns ที่ต้องการ
เช่น หาเวลา delay สูงสุดของขาเข้าและขาออกในแต่ละเดือน:
# Compute with .SDcols
flights[,
lapply(.SD, max, na.rm = TRUE),
by = month,
.SDcols = c("arr_delay", "dep_delay")]
ผลลัพธ์:
month arr_delay dep_delay
<int> <int> <int>
1: 1 996 973
2: 2 1007 1014
3: 3 925 920
4: 4 1223 1241
5: 5 879 889
6: 6 1073 1071
7: 7 1090 1087
8: 8 964 978
9: 9 1115 1056
10: 10 1494 1498
😎 Conclusion
ในบทความนี้ เราได้ไปดูวิธีใช้ data.table เพื่อทำทำงานกับข้อมูลขนาดใหญ่กัน
เราได้เห็นว่า data.table มีหลักการเขียนดังนี้:
DT[i, j, by]
และแต่ละ argument มีการใช้งานดังนี้:
.
Argument i:
| Use Case | Example |
|---|---|
| Select rows | flights[1:5] |
| Filter | flights[distance >= 500] |
| Sort | flights[order(origin)] |
.
Argument j:
| Use Case | Example |
|---|---|
| Select columns | flights[, .(origin, dest)] |
| Compute | flights[, mean(air_time)] |
| Create columns | flights[, speed := distance / (air_time / 60)] |
.
Argument by:
| Use Case | Example |
|---|---|
| Group data | flights[by = origin] |
.
Special symbols:
| Symbol | Meaning |
|---|---|
.N | จำนวน rows |
.SD | Subset of Data |
.SDcols | columns ใน Subset of Data |
.
เราสามารถใช้ทุก arguments ร่วมกัน (combining) หรือเชื่อมต่อ data.table (chaining) เพื่อตอบโจทย์ที่ซับซ้อนได้
🎒 Learn More About data.table
.
😺 GitHub
ดู code ตัวอย่างทั้งหมดในบทความนี้ได้ที่ GitHub
.
📚 อ่านเพิ่มเติมเกี่ยวกับ data.table
- Introduction to data.table
- data.table: Enhanced data.frame
- data.table in R – The Complete Beginners Guide
.
📑 Cheat Sheets ในการใช้งาน data.table
📃 References
- Data Science: R Basics
- Data Manipulation with data.table in R
- A data.table and dplyr tour
- data.table speed with dplyr syntax: Yes we can!
✅ R Book for Psychologists: หนังสือภาษา R สำหรับนักจิตวิทยา
📕 ขอฝากหนังสือเล่มแรกในชีวิตด้วยนะครับ 😆
🙋 ใครที่กำลังเรียนจิตวิทยาหรือทำงานสายจิตวิทยา และเบื่อที่ต้องใช้ software ราคาแพงอย่าง SPSS และ Excel เพื่อทำข้อมูล
💪 ผมขอแนะนำ R Book for Psychologists หนังสือสอนใช้ภาษา R เพื่อการวิเคราะห์ข้อมูลทางจิตวิทยา ที่เขียนมาเพื่อนักจิตวิทยาที่ไม่เคยมีประสบการณ์เขียน code มาก่อน
ในหนังสือ เราจะปูพื้นฐานภาษา R และพาไปดูวิธีวิเคราะห์สถิติที่ใช้บ่อยกัน เช่น:
- Correlation
- t-tests
- ANOVA
- Reliability
- Factor analysis
🚀 เมื่ออ่านและทำตามตัวอย่างใน R Book for Psychologists ทุกคนจะไม่ต้องพึง SPSS และ Excel ในการทำงานอีกต่อไป และสามารถวิเคราะห์ข้อมูลด้วยตัวเองได้ด้วยความมั่นใจ
แล้วทุกคนจะแปลกใจว่า ทำไมภาษา R ง่ายขนาดนี้ 🙂↕️
👉 สนใจดูรายละเอียดหนังสือได้ที่ meb: