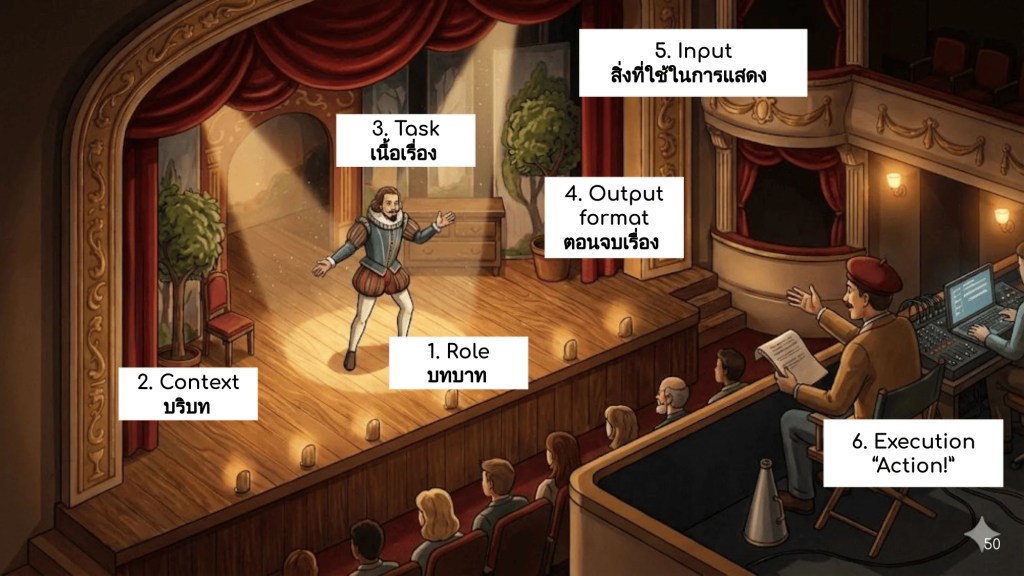
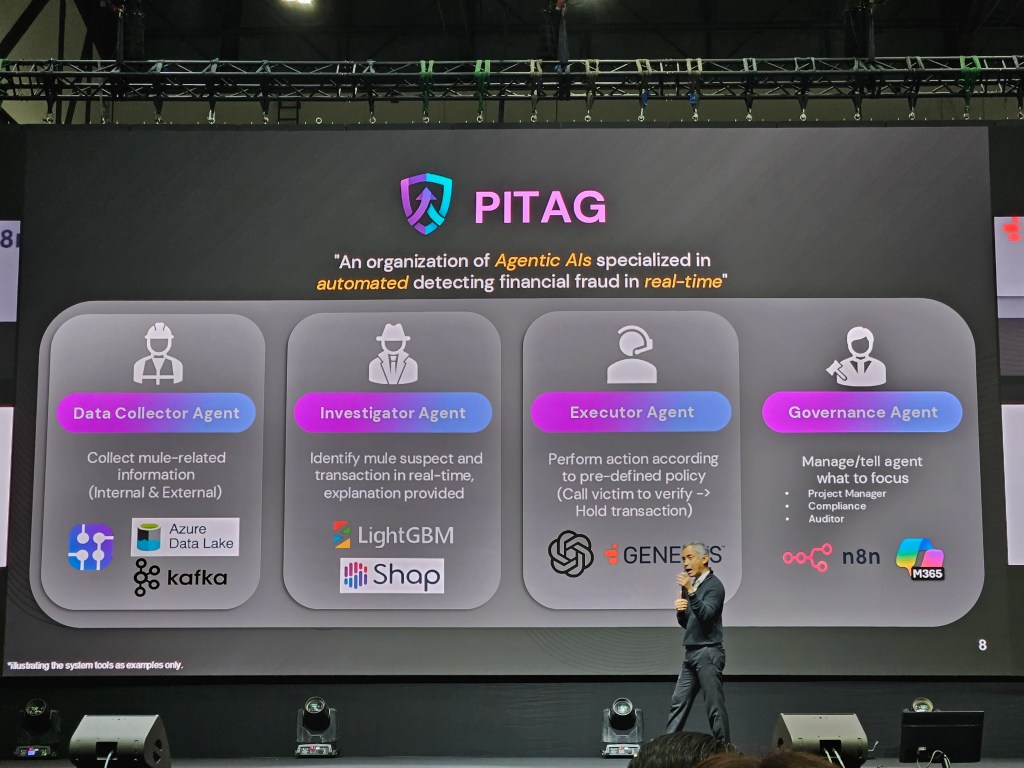
Full-time employees receive health insurance after completing probation.
The company provides annual health checkups once per year.
Employees can claim up to 2,000 THB per month for wellness activities such as fitness memberships, yoga classes, or mental health support.
Employees are also eligible for learning support. The company reimburses up to 10,000 THB per year for approved online courses, books, or professional certificates.
Full-time employees receive health insurance after completing probation.
The company provides annual health checkups once per year.
Employees can claim up to 2,000 THB per month for wellness activities such as fitness memberships, yoga classes, or mental health support.
Employees are also eligible for learning support. The company reimburses up to 10,000 THB per year for approved online courses, books, or professional certificates.
[SystemMessage(content='You are an expert curator of mental models across science, philosophy, and applied reasoning.\\n\\nYour task is to explain mental models clearly and accurately using a fixed schema.\\n\\nIf the origin of a model is unclear or debated, state that explicitly.\\n\\nDo not invent historical sources. Be concise and concrete.', additional_kwargs={}, response_metadata={}),
HumanMessage(content='Explain the following mental model: Pareto Princinple', additional_kwargs={}, response_metadata={})]
"origin": "Finance, Mathematics; concept dates back to ancient times, formalized in the Renaissance.",
"description": "Compound interest is the interest on a loan or deposit calculated based on both the initial principal and the accumulated interest from previous periods. It is often called 'interest on interest' and leads to exponential growth over time, making it a powerful force in finance for both wealth creation and debt accumulation.",
"example": "If you invest $1,000 at an annual interest rate of 5% compounded annually, after the first year you'll have $1,050. In the second year, the 5% interest is calculated on $1,050, not just the original $1,000, leading to a balance of $1,102.50. This snowball effect accelerates over decades, significantly increasing the total return compared to simple interest.",
"origin": "Often attributed to Aristotle; popularized in modern business by Elon Musk.",
"description": "First Principles Thinking involves breaking down complex problems into their most basic, fundamental truths or 'first principles,' rather than reasoning by analogy or conventional wisdom. It matters because it allows for innovative solutions by challenging assumptions and building new knowledge from the ground up.",
"example": "Instead of accepting the high cost of batteries for electric cars, Elon Musk famously broke down a battery into its constituent raw materials (cobalt, nickel, lithium, etc.) to understand their actual cost, then sought ways to procure and assemble them more efficiently, leading to significant cost reductions and innovation.",
"tags": [
"Problem-solving",
"Innovation",
"Critical Thinking",
"Decision-making"
]
}
👉 Query 2:
{
"model_name": "Occam's Razor",
"origin": "William of Ockham (14th-century philosopher and theologian)",
"description": "Occam's Razor is a problem-solving principle stating that among competing hypotheses that explain an event or phenomenon equally well, the simplest solution is most likely the correct one. It advocates for parsimony, suggesting that one should not multiply entities beyond necessity, thereby favoring theories with fewer assumptions.",
"example": "If you hear hoofbeats outside, it is more likely to be horses than zebras, assuming you are in a location where horses are common and zebras are not. The 'horse' explanation is simpler and requires fewer extraordinary assumptions.",
"tags": [
"Philosophy",
"Decision-making",
"Problem-solving",
"Critical thinking",
"Science"
]
}
👉 Query 3:
{
"model_name": "Confirmation Bias",
"origin": "Psychology; early concepts traced to Francis Bacon's Novum Organum (1620)",
"description": "Confirmation bias is the tendency to search for, interpret, favor, and recall information in a way that confirms one's pre-existing beliefs or hypotheses. It matters because it can lead to flawed reasoning, poor decision-making, and resistance to new or contradictory evidence, hindering objective analysis.",
"example": "A person who believes a certain stock will perform well might selectively read news articles and analyst reports that support this positive outlook, while ignoring or downplaying any negative news or warnings about the company.",
การที่ AI พัฒนาเร็วขึ้นเรื่อย ๆ ทำให้เรามีเวลาปรับตัวน้อยลงเรื่อย ๆ
และตอนนี้ เราเหมือนอยู่ที่ทางแยกที่เราจะต้องเลือกว่า เราจะเรียนรู้การใช้ AI ให้เป็นและอยู่รอดในยุคของ AI หรือเราจะใช้ AI แบบเดิม ๆ และถูกทิ้งไว้ข้างหลัง
The people who will come out of this well won’t be the ones who mastered one tool. They’ll be the ones who got comfortable with the pace of change itself. — Matt Shumer
💼 Part II. Working With AI
.
ข้อ 9. Maslow’s hammer
I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail. — Abraham Maslow
Maslow’s hammer เป็น mental model ที่บอกว่า เครื่องมือสามารถจำกัดมุมมองของเราได้
เช่น ถ้าเรามีค้อน เราจะมองทุกอย่างเป็นตะปู
ในยุคของ AI เราอาจมองว่าทุกอย่างแก้ได้ด้วย AI:
ทำงานเร็วขึ้น
ผิดพลาดน้อยลง
มีเวลามากขึ้น
แต่ไม่ใช่ทุกปัญหาจะแก้ได้ด้วย AI เพราะ AI ไม่ใช่เครื่องมือสำหรับแก้ทุกอย่าง
ถ้าเราอยากตอกตะปู เราจะต้องใช้ค้อน ไม่ใช่ AI
การใช้ AI ที่ถูกต้อง คือ เริ่มต้นจากปัญหาและความต้องการของเรา แล้วเลือกเครื่องมือที่ตอบโจทย์ ซึ่งเครื่องมือนั้นอาจจะเป็น AI หรือไม่ก็ได้
.
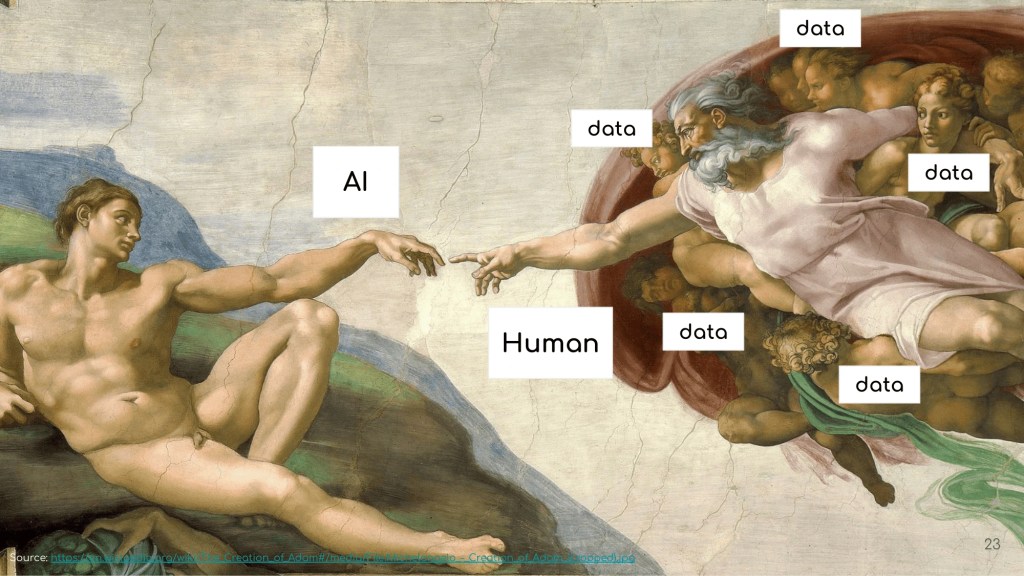
ข้อ 10. AI is built in man’s image
AI เกิดจากการ train model ด้วยข้อมูลจากอินเทอร์เน็ตซึ่งมาจากมนุษย์
Human -> Data -> Train -> AI
เพราะ AI ถูกสร้างจากข้อมูลของมนุษย์ และเรามองได้ว่า AI เป็นเหมือนเป็นมนุษย์คนหนึ่ง
.
ข้อ 11. AI as capable but junior assistant
ถ้าเรามอง AI เป็นคน AI จะเป็นเหมือนผู้ช่วยที่มีความรู้รอบด้านและมีศักยภาพสูง
แต่สิ่งเดียวที่ผู้ช่วยคนนี้ยังขาดไป คือ ทิศทาง
.
ข้อ 12. Even a fried egg is hard to get right
การทำงานกับ AI ก็เหมือนสั่งไข่ดาว แม้จะดูง่าย แต่ก็ไม่ง่ายอย่างที่คิด
บางครั้ง เราอยากกินไข่ไม่สุก แต่ได้แบบสุกมาแทน
บางครั้ง เราอยากให้ AI สร้างรูปในแบบที่เราคิด แต่ไม่เคยได้ภาพนั้นสักที
ถ้าสิ่งที่ AI ส่งกลับมาไม่ตรงใจ เราควรจะบอก AI ว่าอะไรที่ยังไม่ถูกใจ เพื่อให้ AI ปรับผลลัพธ์และส่งกลับมาให้เราเช็กจนกว่าเราจะพอใจกับงานของ AI
.
ข้อ 16. Be accountable
เราควรจะเช็กงานของ AI ทุกครั้ง เพราะถ้าเราไม่รับผิดชอบกับงานของ AI เราอาจจะเป็นเหมือนทนายความจากออสเตรเลียที่ถูกตรวจสอบ หลังจากศาลพบว่าเอกสารที่ทนายนำส่งเป็นข้อมูลที่ไม่มีอยู่จริง
แม้ทนายจะอ้างว่ารู้เท่าไม่ถึงการณ์ว่า AI ที่บริษัทให้ใช้สามารถสร้างข้อมูลที่ไม่มีอยู่จริงได้ และตัวเองควรตรวจสอบข้อมูลจาก AI ก่อน ศาลยังสั่งให้ทนายงดว่าความด้วยตัวเองเป็นเวลา 2 ปี โดยในระยะเวลานี้จะต้องทำงานเป็นลูกจ้างของคนอื่น และต้องรายงานต่อศาลทุกไตรมาส
ดังนั้น ไม่ว่างานของ AI จะดูดีขนาดไหน เราควรจะตรวจสอบด้วยตัวเองก่อนที่จะนำงานไปใช้จริง
เรามีปัจจัยที่ต้องพิจารณาในการทำ AI transformation มีอยู่ 4 อย่าง ได้แก่:
People: พนักงานและลูกค้าของเรา
Culture: วัฒนธรรมขององค์กร
Systems/tools/tech: ระบบ เครื่องมือ และเทคโนโลยี
Finance: เงิน (เพราะองค์กรอยู่ได้ด้วยเงินทุน)
People เป็นสิ่งที่เราต้องให้ความสำคัญเป็นอันดับแรก เพราะถ้าเราโฟกัสที่ technology แต่พนักงานหรือลูกค้าไม่พร้อมที่จะใช้เครื่องมือใหม่ เราอาจจะได้ AI solution ที่ไม่มีใครใช้
🤠 Topic 4. People Management
การบริหารพนักงานในยุคของ AI มีอยู่ 3 หัวข้อ ได้แก่:
Mindset อาจจะเริ่มที่ตัวเราก่อน เช่น ถ้าเราอยากทำ AI transformation แต่เราไม่ชอบ AI เราต้องหันกลับมามองว่า ถ้า AI เป็นสิ่งที่หลีกเลี่ยงไม่ได้ เป็นเราหรือเปล่าที่จะต้องเปลี่ยน
# Load libraries
# Connect to Gemini
from openai import OpenAI
# Connect to Google Drive
from google.colab import drive
# Extract text from PDF
import PyPDF2
# Dedent text
import textwrap
# Render markdown text
from rich.console import Console
from rich.markdown import Markdown
# Set the job description (JD)
web_dev_jd = """
Senior Web Developer
We're looking for a Senior Web Developer with a strong background in front-end development and a passion for creating dynamic, intuitive web experiences. The ideal candidate will have extensive experience with the entire development lifecycle, from project conception to final deployment and quality assurance. This role requires a blend of technical skill, creative collaboration, and a commitment to solving complex programming challenges.
Responsibilities
* Cooperate with designers to create clean, responsive interfaces and intuitive user experiences.
* Develop and maintain project concepts, ensuring an optimal workflow throughout the development cycle.
* Work with a team to manage large, complex design projects for corporate clients.
* Complete detailed programming tasks for both front-end and back-end server code.
* Conduct quality assurance tests to discover errors and optimize usability for all projects.
Qualifications
* Bachelor's degree in Computer Information Systems or a related field.
* Proven experience in all stages of the development cycle for dynamic web projects.
* Expertise in programming languages including PHP OOP, HTML5, JavaScript, CSS, and MySQL.
* Familiarity with various PHP frameworks such as Zend, Codeigniter, and Symfony.
* A strong background in project management and customer relations.
"""
Note: ในกรณีที่ JD เป็นไฟล์ PDF เราสามารถใช้วิธีดึงข้อมูลแบบเดียวกันกับ resumes ได้
.
📄 (3) Resumes
Input สุดท้าย คือ resumes ที่เราต้องการวิเคราะห์
ในตัวอย่าง เราจะดึงข้อมูล resumes จากไฟล์ PDF ใน Google Drive ใน 3 ขั้นตอน ได้แก่:
ขั้นที่ 1. เชื่อมต่อ Google Drive ด้วย drive.mount():
# Connect to Google Drive
drive.mount("/content/drive")
Note: Google จะถามยืนยันการให้สิทธิ์เข้าถึงไฟล์ใน Drive ให้เรากดยืนยันเพื่อไปต่อ
ขั้นที่ 2. กำหนด file path ของไฟล์ PDF ใน Google Drive:
ขั้นที่ 3. ดึง text ออกจาก resumes ด้วย for loop และ PyPDF2:
# Extract resume texts
# Instantiate a collector
rs_texts = {}
# Loop through resume files to get text
for key in rs_file_paths:
# Instantiate an empty string to store the extracted text
rs_text = ""
# Open the PDF file
reader = PyPDF2.PdfReader(rs_file_paths[key])
# Loop through the pages
for i in range(len(reader.pages)):
# Extract the text from the page
text = reader.pages[i].extract_text()
# Append the text to the string
rs_text += text
# Collect the extracted text
rs_texts[key] = rs_text
Contact
+1 (970) 343 888 999
george.evans@gmail.com
<https://www.coolfreecv.com>
32 ELM STREET MADISON, SD
57042
George Evans
PHP / OOP
Zend Framework Summary
Senior Web Developer specializing in front end development .
Experienced with all stages of the development cycle for dynamic
web projects. Well -versed in numerous programming languages
including HTML5, PHP OOP, JavaScript, CSS, MySQL. Strong
background in project management and customer relations.
Perceived as versatile, unconventional and committed, I am
looking for new and interesting programming challenges.
Experience
Web Developer - 09/201 8 to 05/20 22
Luna Web Design, New York
• Cooperate with designers to create clean interfaces and
simple, intuitive interactions and experiences.
• Develop project concepts and maintain optimal workflow.
• Work with senior developer to manage large, complex
design projects for corporate clients.
• Complete detailed programming and development tasks
for front end public and internal websites as well as
challenging back -end server code.
• Carry out quality assurance tests to discover errors and
optimize usability.
Education
Bachelor of Science: Computer Information Systems - 2018
Columbia University, NY
Certifications
PHP Framework (certificate): Zend, Codeigniter, Symfony.
Programming Languages: JavaScript, HTML5, PHP OOP, CSS, SQL,
MySQL.
Reference
Adam Smith - Luna Web Design
adam.smith@luna.com +1(970 )555 555 Skills
JavaScript Symfony Framework
model: model ของ Gemini ที่เราจะเรียกใช้ (เช่น Gemini 2.5 Flash)
temp: ระดับความคิดสร้างสรรค์ของ model โดยมีค่าระหว่าง 0 และ 2 โดย 0 จะทำให้ model ให้คำตอบเหมือนกันทุกครั้ง และ 2 คำตอบจะแตกต่างกันทุกครั้ง
# Create a function to get a Gemini response
def get_gemini_response(prompts, model, temp):
# Generate a response
response = client.chat.completions.create(
# Set the prompts
messages=prompts,
# Set the model
model=model,
# Set the temperature
temperature=temp
)
# Return the response
return response.choices[0].message.content
.
➕ (2) Function ใส่ Input ใน Prompt
ในขั้นที่ 2 เราจะสร้าง function เพื่อประกอบ input เข้ากับ prompt เพื่อพร้อมที่จะนำไปใช้ใน function ในขั้นที่ 1
ในตัวอย่างเราจะสร้าง function แบบนี้:
# Create a function to concatenate prompt + JD + resume
def concat_input(jd_text, rs_text):
# Set the system prompt
system_prompt = """
# 1. Your Role
You are an expert technical recruiter and resume analyst.
"""
# Set the user prompt
user_prompt = f"""
# 2. Your Task
Your task is to meticulously evaluate a candidate's resume against a specific job description (JD) and provide a detailed pre-screening report.
Your analysis must be structured with the following sections and include specific, data-driven insights.
## 1. Strengths
- Identify and elaborate on top three key strengths.
- For each strength, briefly provide specific evidence from the resume (e.g., "The candidate's experience with Python and Django, as shown in their role at Acme Corp, directly addresses the JD's requirement for...") and explain how it directly fulfills a requirement in the JD.
## 2. Weaknesses
- Identify top three areas where the candidate's experience or skills may not fully align with the JD's requirements.
- For each point, briefly explain the potential concern and why it might be a risk for the role (e.g., "The JD requires experience with AWS, but the resume only mentions exposure to Azure. This could indicate a gap in cloud infrastructure expertise.").
## 3. Candidate Summary
- Draft a concise summary of the candidate's professional background.
- Emphasise their JD-relevant core responsibilities, key achievements, and career progression as evidenced in the resume.
## 4. Overall Fit Score
- Provide a numerical score from 1 to 100, representing the overall alignment of the candidate's profile with the JD.
- A higher score indicates a stronger match: 80-100 = best match; 60-80 = strong match; 0-40 = weak match.
## 5. Hiring Recommendation
- Conclude with a clear, binary hiring recommendation: "🟢 Proceed to interview", "🟡 Add to waitlist", or "🔴 Do not proceed".
- Justify this recommendation with a brief, objective explanation based on the analysis above.
---
# 3. Your Output
- Use a professional and objective tone.
- Base your analysis solely on the provided resume and JD. Do not make assumptions.
- Be concise and to the point; no more than 30 words per sentence; the hiring manager needs to quickly grasp the key findings.
- Format your final report using markdown headings and bullet points for readability.
Output template:
'''
# [candidate's name (Title Case)] ([fit score]/100)
[recommendation]: [justification]
## Profile Summary:
[summary]
## Strengths:
- [strength 1]
- [strength 2]
- [strength 3]
## Weaknesses:
- [weakness 1]
- [weakness 2]
- [weakness 3]
'''
---
# 4. Your Input
**1. JD:**
{jd_text}
**2. Resume:**
{rs_text}
---
Generate the report.
"""
# Collect prompts
prompts = [
{
"role": "system",
"content": textwrap.dedent(system_prompt)
},
{
"role": "user",
"content": textwrap.dedent(user_prompt)
}
]
# Return the prompts
return prompts
Note: เราใช้ textwrap.dedent() เพื่อลบย่อหน้าที่เกิดจาก indent ใน function ออกจาก prompt เพื่อป้องกันความผิดพลาดในการประมวลผลของ AI และประหยัด input token
ใช้ for loop เพื่อส่ง resumes ให้กับ Gemini จนครบทุกใบ
# Instantiate a response collector
results = {}
# Loop through the resumes
for rs_name, rs_text in rs_texts.items():
# Create the prompts
prompts = concat_input(web_dev_jd, rs_text)
# Get the Gemini response
response = get_gemini_response(prompts=prompts, model="gemini-2.5-flash", temp=0.5)
# Collect the response
results[rs_name] = response
# Instantiate a console
console = Console()
# Instantiate a counter
i = 1
# Print the results
for rs_name, analysis_result in results.items():
# Print the resume name
print(f"👇 {i}. {rs_name}:")
# Print the response
console.print(Markdown(analysis_result))
# Add spacers and divider
print("\\n")
print("-----------------------------------------------------------")
print("\\n")
# Add a counter
i += 1
ตัวอย่างผลลัพธ์:
ในตัวอย่าง จะเห็นได้ว่า George Evans เหมาะที่จะเป็น Senior Web Developer
ในบทความนี้ เราจะมาดู 4 ขั้นตอนในการใช้งาน google-genai ซึ่งเป็น official library สำหรับทำงานกับ Gemini API ผ่านตัวอย่างการสร้างสูตรอาหารใน Google Colab กัน:
# Create a function to get Gemini response
def get_response(model, user_prompt, config):
# Get response
response = client.models.generate_content(
# Set model
model=model,
# Set user prompt
contents=user_prompt,
# Set config
config=config
)
# Return response
return response.text
📬 Generate Response
ในขั้นที่ 4 เราจะ get response จาก Gemini โดยใช้ function ที่เราสร้างในขั้นที่ 3
เนื่องจาก function ต้องการ 3 arguments เราจะต้องกำหนด 3 สิ่งนี้ก่อนที่จะสร้าง response ได้:
Model
User prompt
Configuration
.
🤖 Set Model
ในตัวอย่างนี้ เราจะใช้ model เป็น Gemini 2.5 Flash ซึ่งเราสามารถกำหนดได้ดังนี้:
สำหรับ user prompt เราสามารถกำหนดเป็น string ได้แบบนี้:
# Set user prompt
gemini_user_prompt = """
Create a healthy Thai-inspired burger for one person.
Protein: chicken or tofu
Bun: whole-wheat if possible (or lettuce wrap)
Deliver (match field names exactly):
- `menu` (string)
- `ingredient` (list of items with name, description, amount, unit)
- `steps` (30-word strings)
- `calorie_kcal` (float, total for the dish)
"""
.
🛠️ Set Configuration
สำหรับ configuration เราสามารถตั้งค่า model ได้หลายค่า
ในตัวอย่างนี้ เราจะเลือกกำหนด 3 ค่า ได้แก่:
System prompt
Temperature
Output type and structure
ค่าที่ 1. System prompt คือ prompt ที่กำหนดพฤติกรรมของ Gemini ในการตอบสนองต่อ user prompt ของเรา
เราสามารถกำหนด system prompt เป็น string ได้แบบนี้:
# Set system prompt
system_prompt = """
You are a highly experienced home cook specialising in healthy Thai-style food.
Constraints:
- Single-serving
- Favour grilling/pan-searing over deep-frying
- Keep ingredients common in Thai kitchens
- Keep steps <=7
- Include an approximate total calories for the whole dish
- Keep language simple
- Return JSON only that matches the given schema exactly (no extra fields)
"""
หลังกำหนด system prompt, temperature, และ output type กับ structure แล้ว ให้เรารวมค่าทั้งหมดไว้ใน GenerateContentConfig() แบบนี้:
# Set configuration
gemini_config = GenerateContentConfig(
# Set system prompt
system_instruction=system_prompt,
# Set temperature
temperature=temp,
# Set response type
response_mime_type=output_type,
# Set response structure
response_schema=OutputStructure
)
หลังจากกำหนด arguments แล้ว เราจะเรียกใช้ function เพื่อ get response แบบนี้:
# Generate a recipe
recipe = get_response(
# Set model
model=gemini_model,
# Set user prompt
user_prompt=gemini_user_prompt,
# Set configuration
config=gemini_config
)
.
🖨️ Print Response
สุดท้าย เราจะดู response ด้วย print():
# Print response
print(recipe)
ผลลัพธ์:
{
"menu": "Thai Chicken Burger",
"ingredient": [
{
"name": "Ground Chicken",
"description": "Lean ground chicken",
"amount": 150.0,
"unit": "g"
},
{
"name": "Whole-wheat Burger Bun",
"description": "Standard size",
"amount": 1.0,
"unit": "unit"
},
{
"name": "Lime Juice",
"description": "Freshly squeezed",
"amount": 1.0,
"unit": "tablespoon"
},
{
"name": "Fish Sauce",
"description": "Thai fish sauce",
"amount": 1.0,
"unit": "tablespoon"
},
{
"name": "Fresh Ginger",
"description": "Grated",
"amount": 1.0,
"unit": "teaspoon"
},
{
"name": "Garlic",
"description": "Minced",
"amount": 1.0,
"unit": "clove"
},
{
"name": "Cilantro",
"description": "Fresh, chopped",
"amount": 2.0,
"unit": "tablespoons"
},
{
"name": "Green Onion",
"description": "Chopped",
"amount": 1.0,
"unit": "tablespoon"
},
{
"name": "Red Chilli",
"description": "Finely minced (optional)",
"amount": 0.5,
"unit": "teaspoon"
},
{
"name": "Lettuce Leaf",
"description": "Fresh, crisp",
"amount": 1.0,
"unit": "large"
},
{
"name": "Cucumber",
"description": "Sliced thinly",
"amount": 3.0,
"unit": "slices"
},
{
"name": "Cooking Oil",
"description": "Any neutral oil",
"amount": 1.0,
"unit": "teaspoon"
}
],
"steps": [
"Combine ground chicken with fish sauce, lime juice, grated ginger, minced garlic, chopped cilantro, and green onion in a bowl. Mix thoroughly.",
"Form the seasoned chicken mixture into a single, uniform burger patty. If using chilli, incorporate it now.",
"Heat cooking oil in a non-stick pan over medium heat. Cook the chicken patty for 5-7 minutes per side, or until it is thoroughly cooked through.",
"While the patty cooks, lightly toast the whole-wheat burger bun in a dry pan or toaster until golden brown.",
"Assemble your burger: Place the cooked chicken patty on the bottom half of the toasted bun. Top with fresh lettuce and cucumber slices.",
"Complete the burger with the top bun. Serve immediately and enjoy your healthy Thai-inspired meal."
],
"calorie_kcal": 450.0
}
เท่านี้ก็จบ flow การทำงานกับ Gemini API ด้วย google-genai library แล้ว
แล้วเราก็จะต้องส่งข้อมูลเพิ่มให้ก่อน AI จะทำงานได้
จากตัวอย่าง เราจะเห็นว่า การทำงานกับ AI มีความเหมือนกันกับการทำงานกับคน ดังนั้น การมองว่า AI เป็นเพื่อนร่วมงานจะช่วยเป็นแนวทางในการทำงานกับ AI ให้เราได้
.
➿ ข้อ 3. Human in the Loop
สุดท้ายและเป็นข้อที่สำคัญ คือ เราควรทำงาน “ร่วม” กับ AI
อย่างที่เราเห็นว่า AI เป็นเหมือนเพื่อนร่วมงาน และเช่นเดียวกับเพื่อนร่วมงานที่ทำงานผิดพลาดได้ AI ก็เช่นกัน
[ROLE] You are a travel planner helping me organise a New Year holiday trip. [INSTRUCTION] Suggest a affordable 3-day itinerary for a relaxing vacation.
[CONTEXT] I enjoy nature and fresh air, and I like to avoid crowded tourist spots. [EXAMPLE] Examples of places I like are Chiang Mai and Nan.
Explain API in a [STYLE] bullet-point format for [AUDIENCE] a 10-year-old, using an analogy. Length [LENGTH] around 100-150 words. Use [TONE] friendly tone.
เพราะ AI เรียนรู้การทำงานจากมนุษย์ เราสามารถใส่คำแสดงอารมณ์เข้าไปใน prompt เพื่อส่งสารบางอย่างให้กับ AI ได้
ถ้าเปรียบเทียบกับคน คือ แทนที่จะบอกว่า:
ช่วยทำรายงานให้หน่อย
เป็น
รีบทำรายงานตอนนี้ให้หน่อย ด่วนที่สุด
ตัวอย่างเช่น:
ใส่ความเร่งด่วน:
This is extremely urgent! Summarise this article as quickly as possible, focusing only on the key points.
ใส่ความตื่นเต้น:
Write an exciting social media post that builds anticipation for our upcoming event! Make readers feel thrilled and eager to attend.
ใส่ความสำคัญ:
Write an important and professional email explaining the new company policy. Emphasise its significance and ensure employees understand its impact on their roles.